



Meta's "Self-Rewarding Language Models" are designed to improve themselves and complement or, in the future, completely replace human-dependent feedback methods. A first test shows the potential, but there are still many unanswered questions.
Researchers from Meta and New York University have presented a new concept for language models, called "Self-Rewarding Language Models". These models are able to generate their own rewards during training, leading to a continuous improvement in their performance. This is in contrast to conventional approaches such as reinforcement learning with human feedback (RLHF) or direct preference optimization (DPO), where the reward signal comes from humans.
The researchers say their work overcomes a key limitation of those methods: the human performance level is a potential bottleneck. The idea behind self-rewarding models is to overcome this limitation by teaching the models to evaluate and improve themselves, potentially beyond the level that can be achieved through human feedback.
Llama 2 70B shows significantly improved performance as a self-rewarding LM
The method starts with a pre-trained language model, in this case Meta's Llama 2 70B. This model already has an extensive knowledge base and the ability to respond to a large number of queries. First, the model generates responses to queries and evaluates them according to criteria defined in a prompt. The model then uses this feedback as training data to improve future generations, similar to DPO, but without human input. Based on this, the model then learns to give better answers — but also to better evaluate its answers and in turn improve future answers.

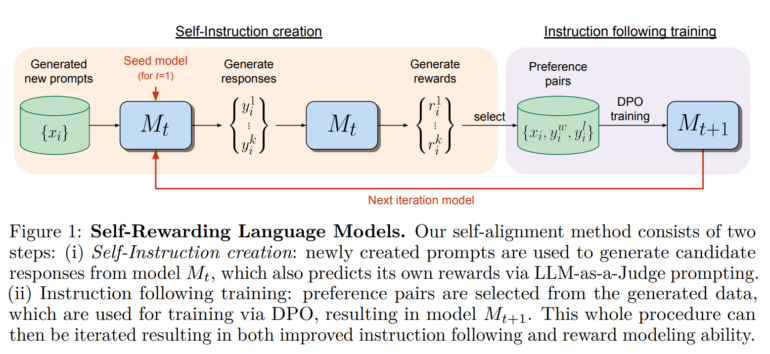
Because the model is constantly learning by evaluating its answers, it can theoretically continue to improve without relying on human data or limitations. The team plans to further investigate the exact limits of this process.
In initial experiments, however, the three iteratively trained, self-rewarding models showed significant improvements in following instructions, at least in the AlpacaEval 2.0 benchmark that the team used for evaluation and in which GPT-4-Turbo evaluates the quality of responses. In the benchmark, the Llama 2 70B variant outperformed several well-known models, including Claude 2, Gemini Pro, and GPT-4 0613.

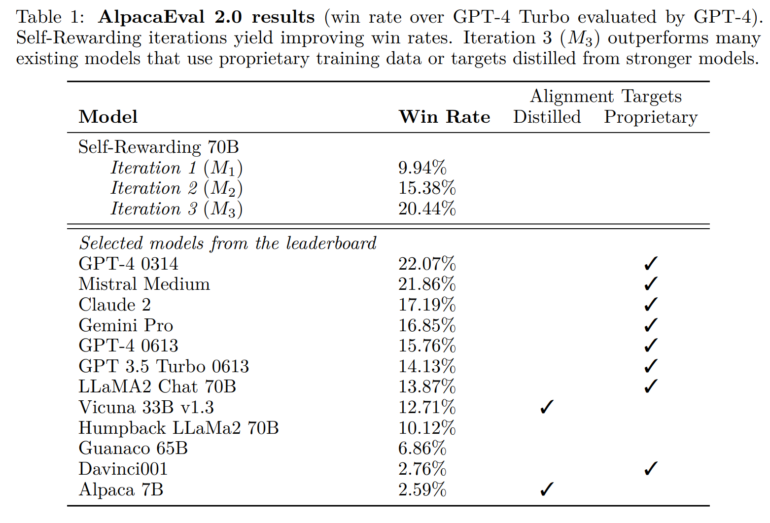
It is unclear whether a high score on this benchmark translates into good performance in practice, especially since GPT-4 favors models with longer outputs and those trained with GPT-4 outputs in the evaluation. In fact, the team notes that the outputs of their models are iteratively getting longer.
The team therefore plans to investigate the method further, perform human evaluations of the outputs, and check whether the method is susceptible to "reward hacking," where the model learns to exploit gaps or weaknesses in the reward system to obtain a higher reward without improving on the actual task.