IBM's Granite Code open-source models outperform larger rivals in programming tasks
IBM releases a set of models called "Granite Code" specialized for programming. The models outperform some larger open-source competitors on benchmarks and are designed to help companies with various software development tasks.
The models come in two flavors (Base and Instruct) and four sizes each, with 3, 8, 20, and 34 billion parameters. They vary in context length, ranging from 2,048 tokens for 3 billion parameters to 8,192 tokens for 20 billion parameters.
The relatively short context window, GPT-4 Turbo for example has a 128K context window, limits its usefulness somewhat, as there is little room to include additional information such as specific documentation or your own code base in a prompt. However, IBM is currently working on versions with larger context windows.
The base models were trained in two phases. Phase 1 involved training with 3-4 trillion tokens from 116 programming languages to develop a broad understanding. In phase 2, the models were further trained with a carefully selected mix of 500 billion tokens from high-quality code and natural language data to enhance logical reasoning ability, according to IBM Research.
The instruction models were created by refining the base models with a combination of filtered code commits, natural language instruction records, and synthetically generated code datasets.
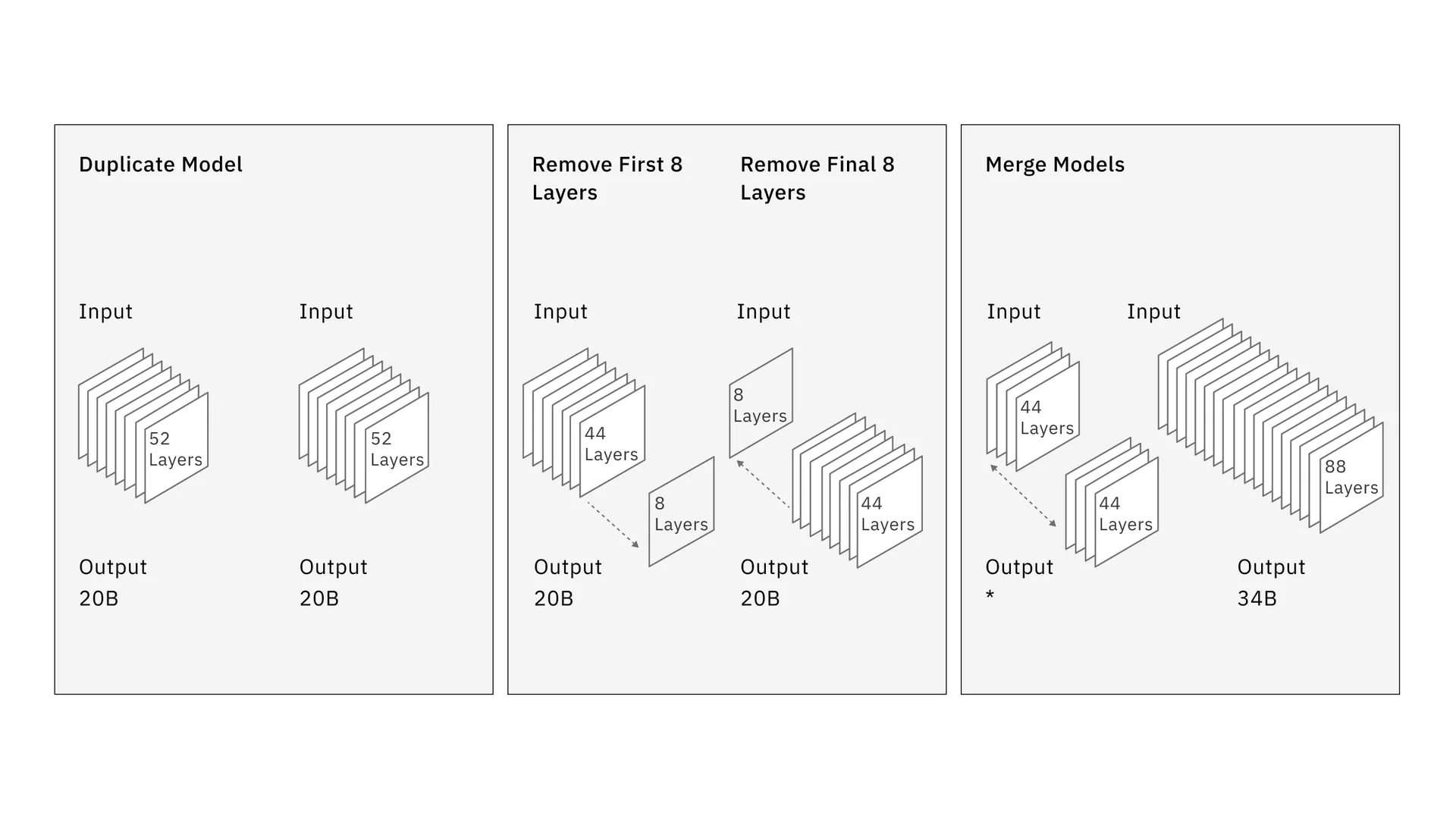
The 34B variant is unique in that IBM researchers used a new approach called depth upscaling. They first duplicated the 52-layer 20B variant, then removed the first eight layers from one variant and the last eight layers from the other, and finally reassembled them into an 88-layer model.
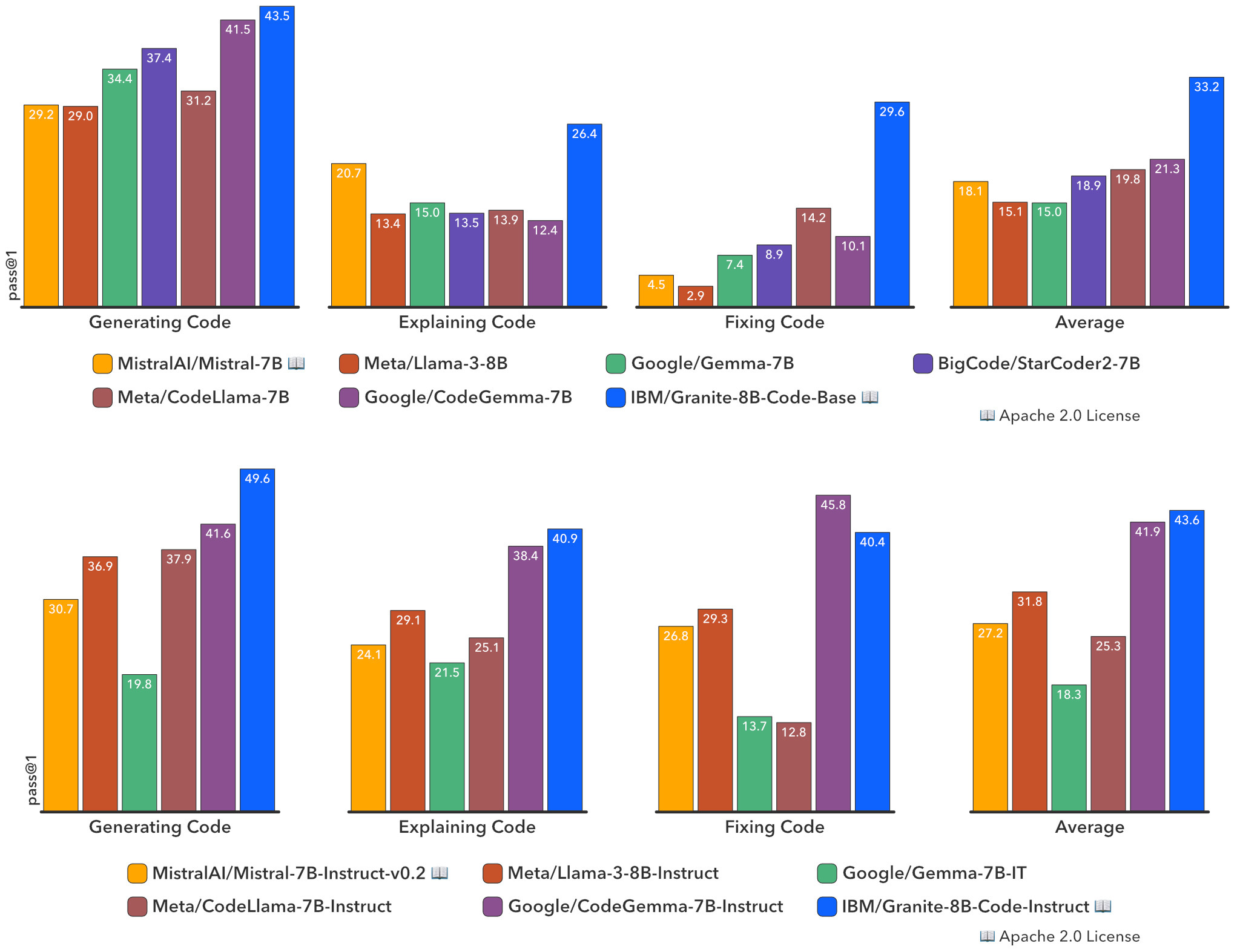
Equal or better performance with fewer parameters
In benchmark evaluations covering code synthesis, debugging, explanation, editing, mathematical reasoning, and more, Granite code models performed quite well among open-source models across all sizes and benchmarks, often outperforming other open-source code models twice their size, IBM Research reports.
For example, on the HumanEvalPack benchmark, Granite-8B-Code-Base beat Google's best-performing CodeGemma-8B model by nearly 12 points on average (33.2% vs. 21.3%), despite being trained on significantly fewer tokens.
Most of the training data comes from a cleaned GitHub dataset, StarCoderData, and other publicly available code repositories. This is relevant because there are lawsuits against other code models, including Github, for alleged copyright infringement of training data.
IBM plans to update these models regularly, with versions featuring larger context windows and specializations for Python and Java coming soon. They are available on Hugging Face and GitHub. Granite Code is also part of IBM's watsonx enterprise platform.
This new family of coding LLMs is IBM's first in this direction, but the company laid an important foundation for the development of open coding models back in 2021 with the CodeNet dataset.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.