Research shows that high-quality education data is key to AI performance

A new dataset called FineWeb-Edu highlights the importance of high-quality learning content for the performance of large language models.
FineWeb-Edu is a new high-quality Hugging Face dataset for training large language models (LLMs). It's based on FineWeb, an already filtered web dataset with 15 trillion tokens from 96 CommonCrawl snapshots.
Hugging Face researchers used a classifier trained on the results of a Llama-3-70B-Instruct model's evaluation of FineWeb articles to filter FineWeb for educational content, creating FineWeb-Edu.
Only text data that scored at least 3 out of 5 on an educational scale were included in FineWeb-Edu. This filtered dataset has 1.3 trillion tokens, less than 10% of the original.
The researchers trained a set of 1.82 billion parameter LLMs on 350 billion tokens each from FineWeb-Edu and other datasets. They then compared the performance of the models on various benchmarks.
The result: FineWeb-Edu massively outperforms the unfiltered FineWeb dataset and all other public web datasets, especially on tasks requiring knowledge and logical reasoning.
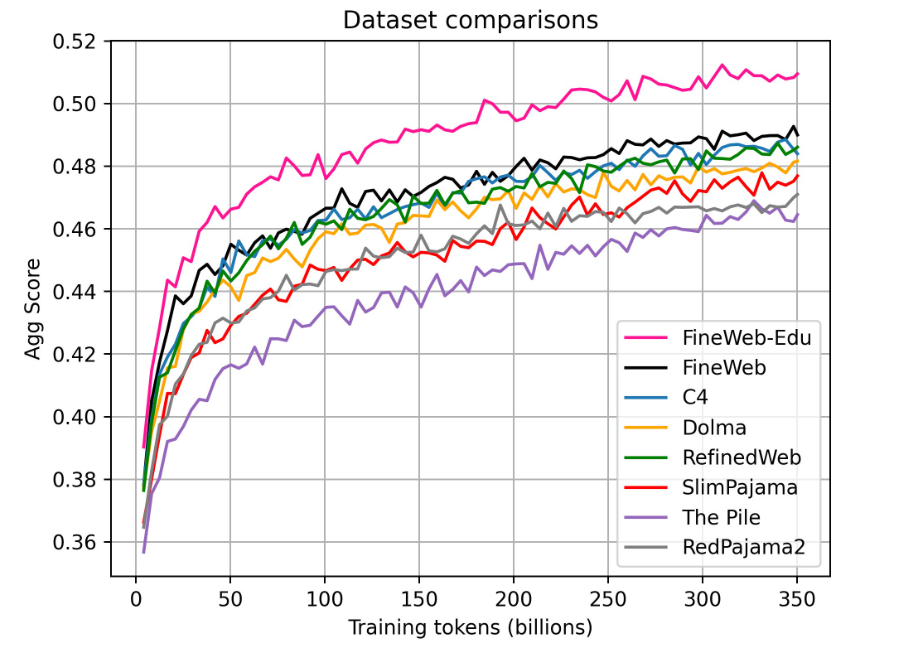
To reach the performance of FineWeb-Edu, other datasets like C4 or Dolma need up to 10 times more training data. This again shows the effectiveness of focusing on high quality educational data, something Microsoft has already shown with its "Textbooks is all you need" research and tiny Phi models. But Microsoft hasn't made its classifier and dataset publicly available.
Quality beats quantity, but to scale AI, you need both
AI expert Andrej Karpathy shares the Hugging Face team's assessment. The average website on the Internet is so random and terrible that it is not even clear how previous LLMs were able to learn anything from it, Karpathy says.
"You'd think it's random articles but it's not, it's weird data dumps, ad spam and SEO, terabytes of stock ticker updates, etc. And then there are diamonds mixed in there, the challenge is pick them out," he writes.
Along with the 1.3 trillion token dataset (very high educational content), the researchers are also releasing a less heavily filtered 5.4 trillion token version (high educational content) on Hugging Face. Both datasets are freely available, and the researchers also detail their process for compiling the dataset.
The researchers hope to apply the FineWeb-Edu findings to other languages in the future, to make high-quality Web data available for different languages.
Going forward, the research shows that data quality and diversity could take precedence over sheer size in AI training. In addition, synthetically generated data with human quality control could be used to fill specific gaps in data sets or to achieve the scale still needed for new flagship models.
This also explains why OpenAI and other LLM developers are so interested in deals with established publishers. They want access to high-quality data sources such as textbooks, news articles, or scientific papers that can improve their model training. Some of this material has already been used in GPT-4 and others, but without permission.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.