Researchers develop method to better detect LLM bullshit

A team of researchers at the University of Oxford has developed a method for identifying errors in LLM generations. They measure "semantic entropy" in the responses of large language models to identify potential confabulations.
In machine learning, entropy describes the natural fluctuations and uncertainties in the data. By estimating entropy, a model can better assess how well it captures the underlying patterns in the data and how much uncertainty remains in its predictions.
The "semantic entropy" now used by the Oxford researchers measures this uncertainty at the level of the meaning of sentences. It is designed to estimate when an LLM query might lead to correct but arbitrary or incorrect answers to the same question.
The researchers call this subset of AI hallucinations - or LLM soft bullshit - "confabulation" and distinguish it from systematic or learned LLM errors. The researchers emphasize that their method only improves on these confabulations.
Language models are better at knowing what they don't know than previously assumed
The researchers generate several possible answers to a question and group them based on bidirectional implication. If a sentence A implies that a sentence B is true and vice versa, they are assigned to the same semantic cluster by another language model.
By analyzing multiple possible answers to a question and grouping them, researchers calculate semantic entropy. A high semantic entropy indicates a high level of uncertainty and therefore possible confabulation, while a low value indicates consistent and more likely correct answers.
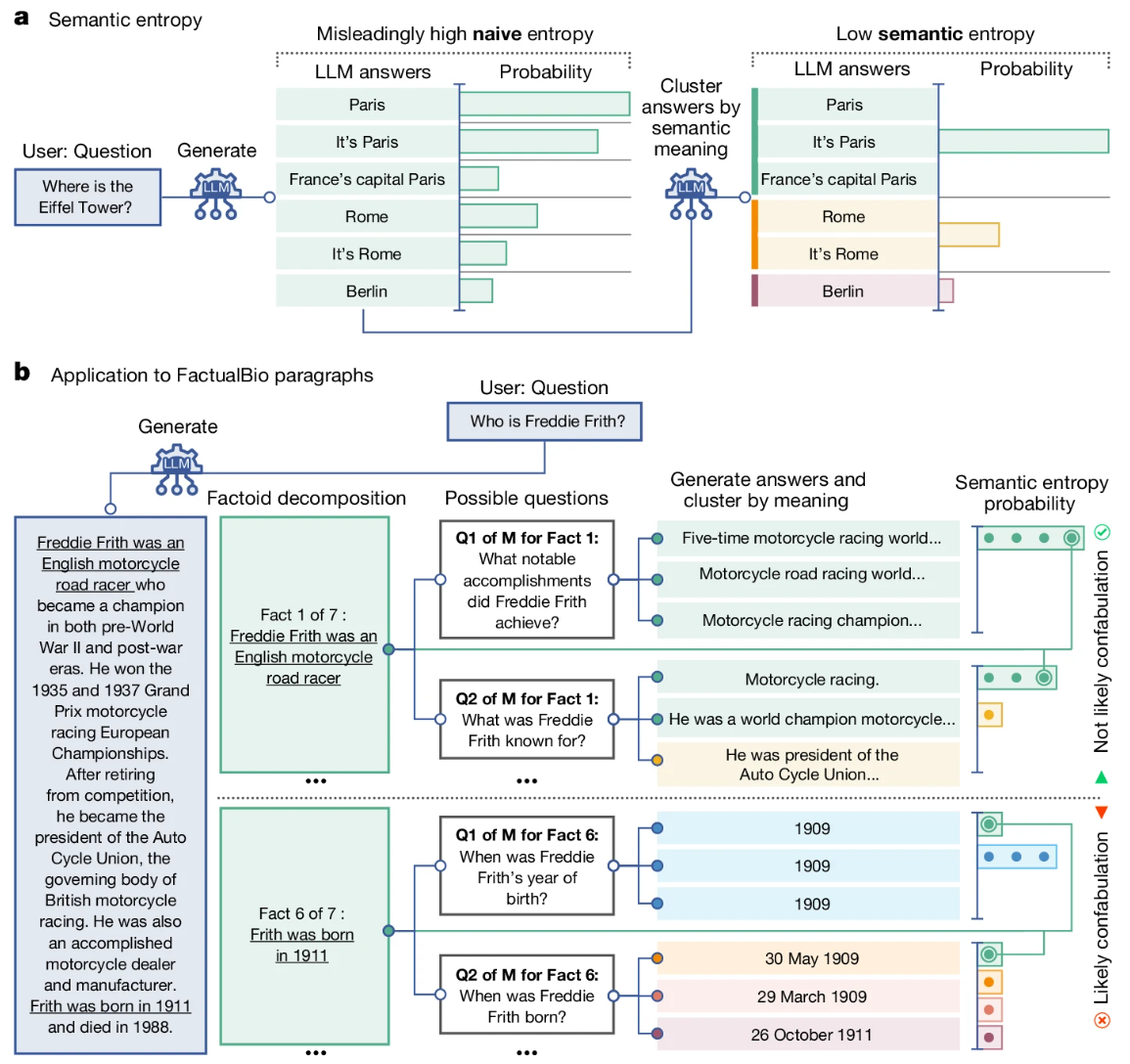
By filtering out questions that are likely to lead to confabulation, the accuracy of the remaining answers can be increased. According to the researchers, this works across different language models and domains without training on domain-specific knowledge.
In tests across 30 task and model combinations, the method was able to distinguish between correct and incorrect AI answers about 79 percent of the time, outperforming existing methods by about ten percent.
This relative success of semantic entropy in error detection suggests that LLMs are better at "knowing what they don't know" than previously thought - "they just don’t know they know what they don’t know," the researchers write.
They emphasize that their method is not a comprehensive solution for all types of errors in LLMs, focusing specifically on the detection of confabulation. Further research is needed to address systematic errors and other uncertainties.
Higher LLM reliability is more expensive
In practice, model and AI service providers could build semantic entropy into their systems and allow users to see how certain a language model is that a suggested answer is correct. If it is not sure, it might not generate an answer or mark uncertain passages of text.

However, this would mean higher costs. According to co-author Sebastian Farquhar, the entropy check increases the cost per query by a factor of five to ten because up to five additional queries have to be generated and evaluated for each single question.
"For situations where reliability matters, the extra tenth of a penny is worth it," Farquhar writes.
It remains to be seen whether companies like OpenAI or Google, with hundreds of millions or even billions of chatbot queries per day, will come to a similar conclusion for a ten percent improvement in a particular segment of hallucinations, or whether they'll just move on and not care.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.