SenseTime unveils SenseNova 5o, China's first real-time multimodal AI model to rival GPT-4o

Chinese AI company SenseTime introduced its new multimodal AI model SenseNova 5o and the improved language model SenseNova 5.5 at the World Artificial Intelligence Conference.
SenseTime claims that SenseNova 5o is China's first real-time multimodal model that provides multimodal AI interaction comparable to GPT-4o. It can process audio, text, image and video data, allowing users to interact with the model simply by talking to it.
SenseTime says the model is particularly well suited for real-time conversations. The company showed a demo reminiscent of OpenAI's GPT-4o demo from early May, which also showcased the model's vision capabilities. For example, SenseNova 5o can recognize and describe individual objects by simply pointing a smartphone camera at the object while the AI app is running.
Video: via Sensetime
However, while OpenAI demonstrated many other multimodal capabilities beyond speech, particularly in image generation, SenseTime did not mention these for SenseNova.
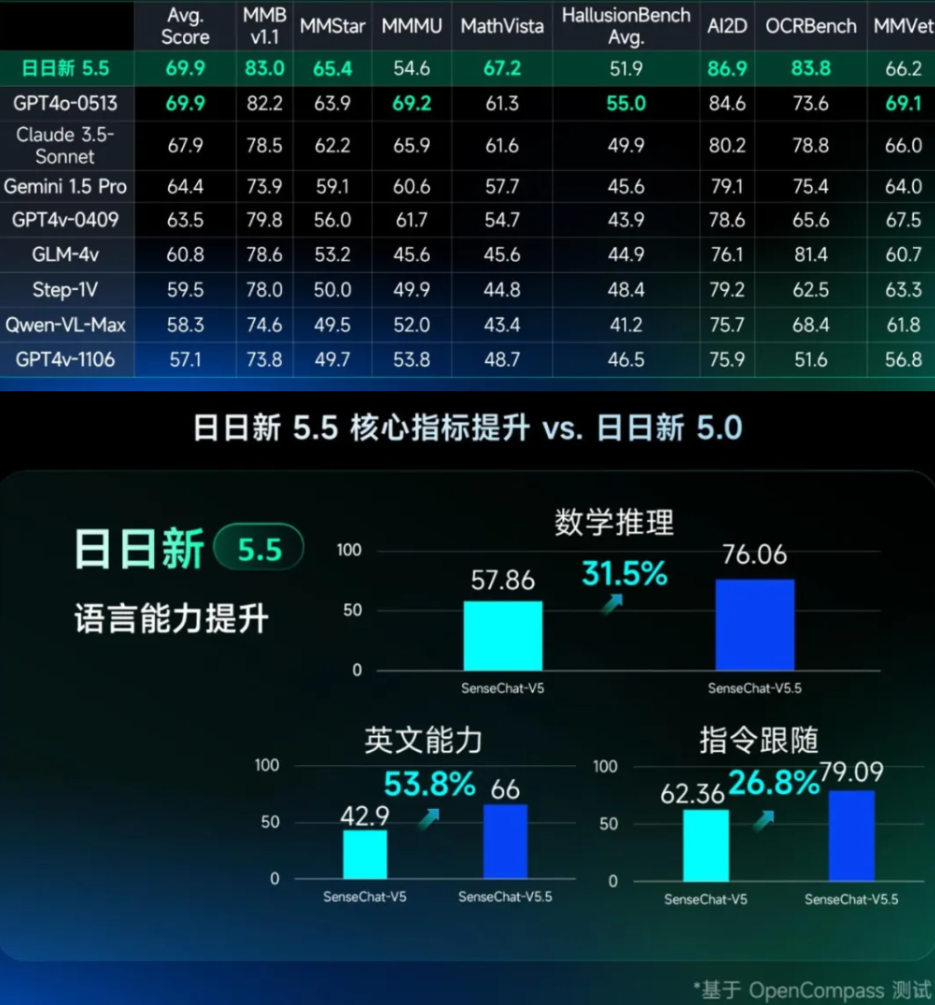
SenseTime has also updated its SenseNova language model. According to the company, the new version 5.5 achieves a 30 percent increase in performance over version 5.0, which was released just two months ago. The training data included more than ten terabytes of high-quality data, with many synthetically generated reasoning chains to improve its reasoning capabilities.
SenseTime claims that with significantly improved skills in Mathematical Reasoning (+31.5%), English (+53.8%), and Prompt Following (+26.8%), interactivity and many core indicators are on par with GPT-4o.
The SenseNova Large Model is currently being used by more than 3,000 government and corporate customers in industries such as technology, healthcare, finance, and programming.
SenseTime is also investing in edge-based language models that are fast and cost-effective. With SenseChat Lite-5.5, inference time has been reduced to 0.19 seconds, 40 percent faster than version 5.0, and inference speed has increased by 15 percent to 90.2 words per second.
The Vimi AI avatar video generator, part of SenseNova 5.5, can generate up to one-minute clips from a single photo while providing control over facial expressions, lighting and background.
Video: via Sensetime
Dr. Xu Li, CEO of SenseTime, believes 2024 will be a decisive year for large models, which will transition from unimodal to multimodal. SenseTime is focusing on increasing the interactivity of AI models. Xu Li promises "unprecedented transformations in human-AI interactions."
Founded in 2014, Hong Kong-based SenseTime is one of the best-funded Chinese AI companies. In the past, the company has made headlines primarily for its visual surveillance software that uses facial recognition.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.