Graph RAG: Access to external data becomes much more accurate with Microsoft's approach

Microsoft researchers have developed a method called Graph RAG that significantly enhances how language models process external data.
Published in April, the approach allows for more meaningful answers to general queries across large databases compared to traditional methods that simply string together text snippets. According to Microsoft, in just a few months, Graph RAG has demonstrated clear advantages over traditional vector-based RAG approaches.
Retrieval augmented generation (RAG) is a common technique for answering user queries on large data sets that exceed the context window of a language model. While models such as Gemini 1.5 Pro can now process up to two million tokens at a time, RAG frameworks first retrieve relevant information from external sources to enrich the context of an original query. That way, it can still help improve answers.
However, conventional vector-based RAG works best when answers are contained locally in text areas. It struggles with query-focused summaries spanning entire document collections.
Graph RAG differs by combining the modularity of knowledge graphs with the capabilities of language models. This makes it much more effective for questions such as "Which public figures are mentioned in various entertainment articles?"

The process begins by extracting chunks of text from source documents. A language model then identifies entities and relationships within each chunk. Entities in a knowledge graph can include people, companies, or places, for example.
To answer a user query, the system prepares grouped summaries and generates parallel intermediate answers for each chunk. These are then condensed into a final answer through query-focused summarization. Microsoft says this approach is more efficient than directly summarizing source texts, as each query requires fewer context tokens.
Graph RAG also excels at identifying higher-level topics in databases. Answers are more comprehensive than with vector RAG, while source information makes it easier to verify claims.

A key advantage of knowledge graphs over vector databases is that humans can more easily explore and add new content. This combination of language models and knowledge graphs as external information sources could make AI answers more verifiable.
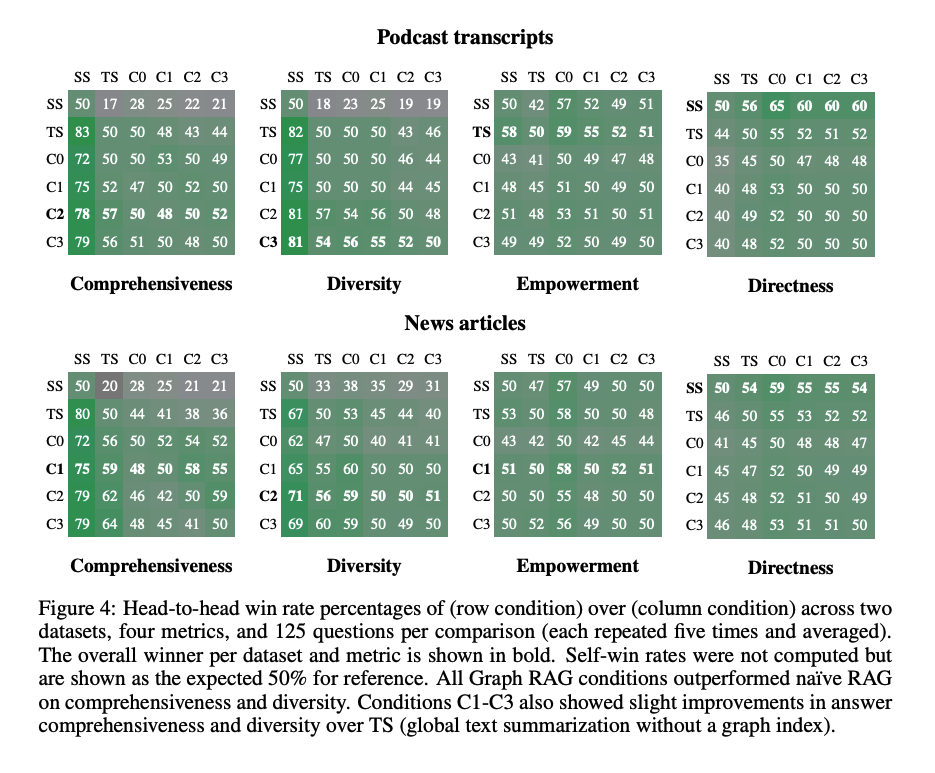
The researchers tested their approach on podcast transcripts and news articles. They generated questions using a language model and compared the performance of Graph RAG at different levels of summarization with traditional RAG. Benchmarks showed that all Graph RAG approaches outperformed traditional methods in terms of completeness and variety.
Microsoft released Graph RAG as a Python implementation on GitHub and Azure in early July. LinkedIn's initial customer support tests are promising. Over a six-month period, response times to support requests dropped by an average of nearly 30%. Extensive independent benchmarking has yet to be done. Alternatives are available from companies such as neo4j.
The researchers acknowledge some limitations in their evaluation. They only tested Graph RAG on corpora of about one million tokens – theoretically small enough to fit in a single text prompt. However, language models still struggle with "lost in the middle" issues for long documents, which RAG systems have been shown to mitigate. Graph RAG and similar approaches might be able to combine the best of both worlds.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.