Study reveals major weaknesses in AI's ability to understand diagrams and abstract visuals

Recent advances have made AI models increasingly multimodal, able to process text, images, speech, and video together.
While these models perform well with natural photos and portraits, they show significant weaknesses in understanding abstract visuals like diagrams and charts, according to researchers at China's Zhejiang University. This limitation could hinder AI's use in many professional fields.
The researchers developed a "multimodal self-instruct" method to create a diverse dataset of 11,193 abstract images with related questions. These covered eight common scenarios: dashboards, road maps, diagrams, tables, flowcharts, relationship graphs, visual puzzles, and 2D floor plans. They used Python libraries like Matplotlib to closely match questions to graphics.
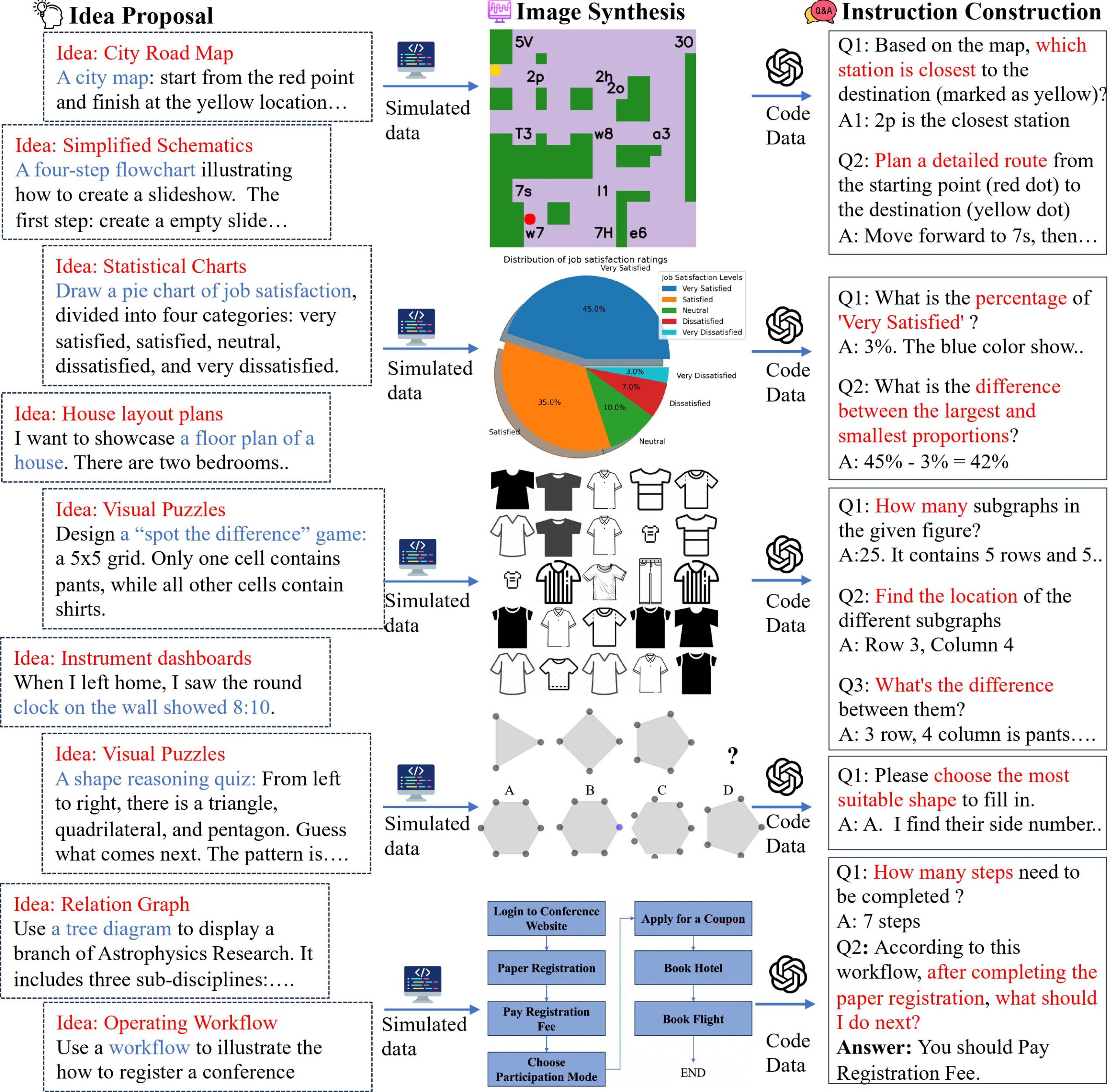
When tested on this dataset, even advanced models like GPT-4o and Claude 3.5 Sonnet only achieved average accuracies of 64.7% and 59.9% respectively across all tasks. This falls well short of human performance, which was at least 82.1%.
"Our benchmark indicates that current LMMs are far from human-level performance. They even fail to complete simple daily tasks, e.g., reading the time on a clock or planning a route using a map," the researchers conclude.

For instance, GPT-4o only managed 54.8% accuracy on dashboard tasks involving reading clocks and meters. The models also struggled with spatial relationships in floor plans and made errors with abstract concepts in diagrams and graphs.
Open-source models performed even worse, especially on visual reasoning tasks. While closed models like Claude 3.5 Sonnet reached up to 62% accuracy on road map navigation and visual puzzles, smaller open-source models scored below 20%.
To test if synthetic data could improve performance, the researchers fine-tuned the open-source Llava-1.5-7B model on 62,476 graph, table, and road map instructions. This boosted its accuracy on road map tasks to 67.7%, surpassing GPT-4V by 23.3%.
The approach relies on closed models like GPT-4o to create high-quality reference data, which is costly. Future work aims to use open-source models like LLaMA 3 or DeepSeek-V2 instead.
The researchers plan to expand beyond the current eight scenarios and increase the resolution of the visual encoder, which they see as a major limitation of current multimodal language models.
This study adds to growing evidence that image processing in large language models isn't great yet, depending on the usage scenario. A recent study showed that LMMs have problems with finding specific visual objects in large image sets.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.