New prompting method can help improve LLM reasoning skills

Chinese researchers have created a technique that enables large language models (LLMs) to recognize and filter out irrelevant information in text-based tasks, leading to significant improvements in their logical reasoning abilities.
The research team from Guilin University of Electronic Technology and other institutions developed the GSMIR dataset, which consists of 500 elementary school math problems intentionally injected with irrelevant sentences. GSMIR is derived from the existing GSM8K dataset.
Tests on GSMIR showed that GPT-3.5-Turbo and GPT-3.5-Turbo-16k could identify irrelevant information in up to 74.9% of cases. However, the models were unable to automatically exclude this information once it was detected before solving a task.
Recognizing and filtering irrelevant information - and only then responding
To address this, the researchers developed the two-stage "Analysis to Filtration Prompting" (ATF) method. First, the model analyzes the task and identifies irrelevant information by examining each sub-sentence. It then filters out this information before starting the actual reasoning process.
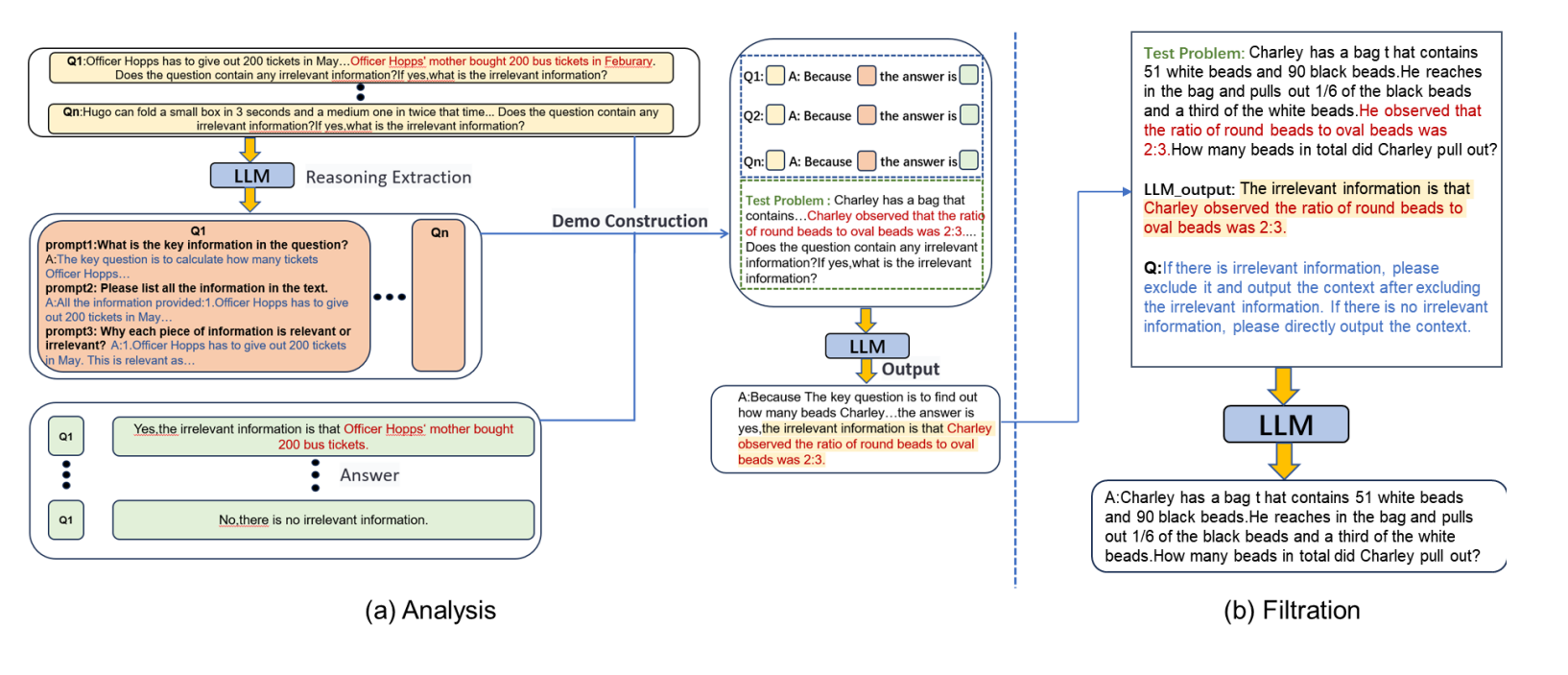
Using ATF, the accuracy of LLMs in solving tasks with irrelevant information approached their performance on the original tasks without such distractions. The method worked with all tested prompting techniques.
The combination of ATF with "Chain-of-Thought Prompting" (COT) was particularly effective. For GPT-3.5-Turbo, accuracy increased from 50.2% without ATF to 74.9% with ATF – an improvement of nearly 25 percentage points.
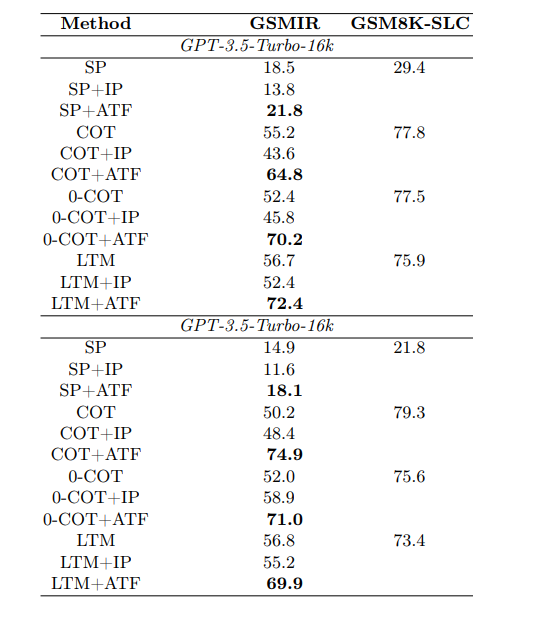
The smallest improvement came when ATF was combined with Standard Prompting (SP), where accuracy increased by only 3.3 percentage points. The researchers suggest that this is because SP's accuracy on the original questions was already very low at 18.5%, with most errors likely due to calculation errors rather than irrelevant information.
Because the ATF method is specifically designed to reduce the impact of irrelevant information, but not to improve the general computational ability of LLMs, the effect of ATF in combination with SP was limited.
With other prompting techniques, such as COT, which better support LLMs in correctly solving reasoning tasks, ATF was able to improve performance more significantly because irrelevant information accounted for a larger proportion of errors.
The study has some limitations. Experiments were conducted only with GPT-3.5, and the researchers only examined tasks containing a single piece of irrelevant information. In real-world scenarios, problem descriptions may contain multiple confounding factors.
In approximately 15% of cases, irrelevant information was not recognized as such. More than half of these instances involved "weak irrelevant information" that did not impact the model's ability to arrive at the correct answer.
This suggests that ATF is most effective for "strong irrelevant information" that significantly interferes with the reasoning process. Only 2.2% of cases saw relevant information incorrectly classified as irrelevant.
Despite these limitations, the study shows that language models' logical reasoning abilities can be enhanced by filtering out irrelevant information through prompt engineering. While the ATF method could help LLMs better handle noisy real-world data, it does not address their fundamental weaknesses in logic.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.