Study reveals major reasoning flaws in smaller AI language models

A new study has uncovered significant gaps in the reasoning abilities of AI language models, especially smaller and cheaper ones. These models struggle with chained elementary-level math problems.
Researchers from the Mila Institute, Google DeepMind, and Microsoft Research investigated how well different AI language models could solve linked elementary school-level math word problems. They created a test called "Compositional GSM" that combines two problems from the GSM8K dataset, using the answer from the first problem as a variable in the second.
The results show many models performed much worse than expected on these more complex reasoning tasks. This "reasoning gap" is particularly pronounced in smaller, cheaper models and even those specializing in math.
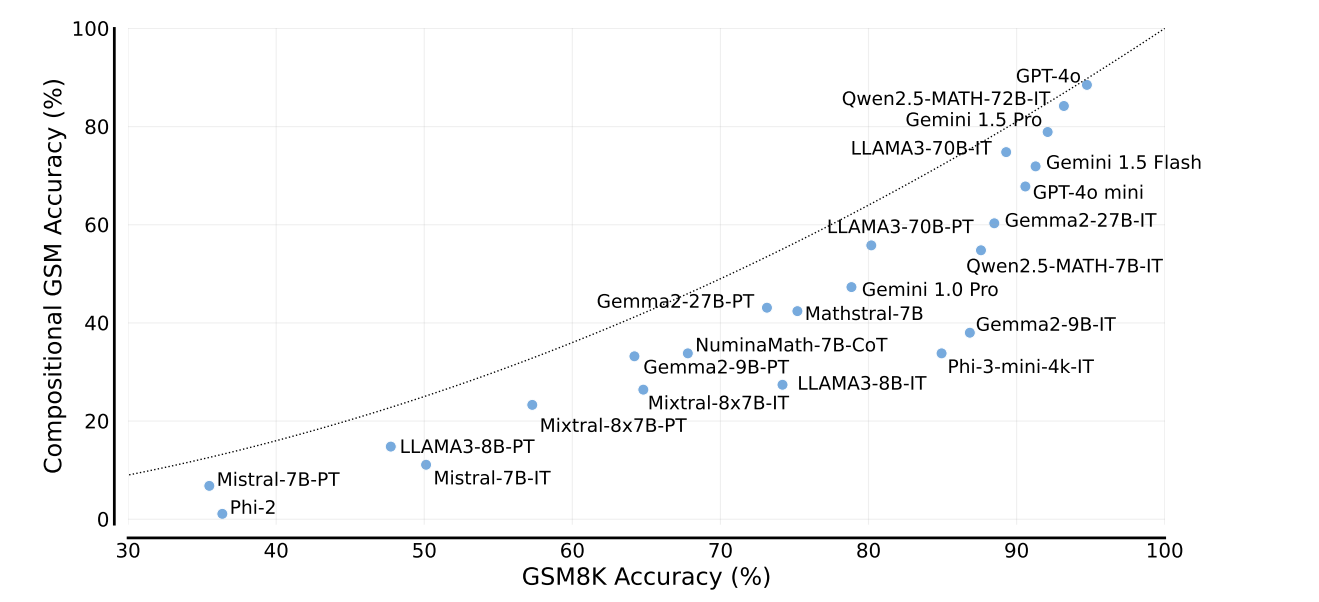
"Our findings reveal a significant reasoning gap in most LLMs, that is performance difference between solving the compositional pairs and solving each question independently," explain the authors, led by Arian Hosseini of the Mila Institute.
Smaller models struggle with complex tasks
While smaller models often score similarly to larger ones on standard math tests like GSM8K, they show a 2-12 times larger logic gap on the new Compositional GSM test. For instance, GPT-4o mini falls far behind GPT-4o on the new test, despite nearly matching it on the original benchmark. Similar patterns appeared across other model families like Gemini and LLAMA3.
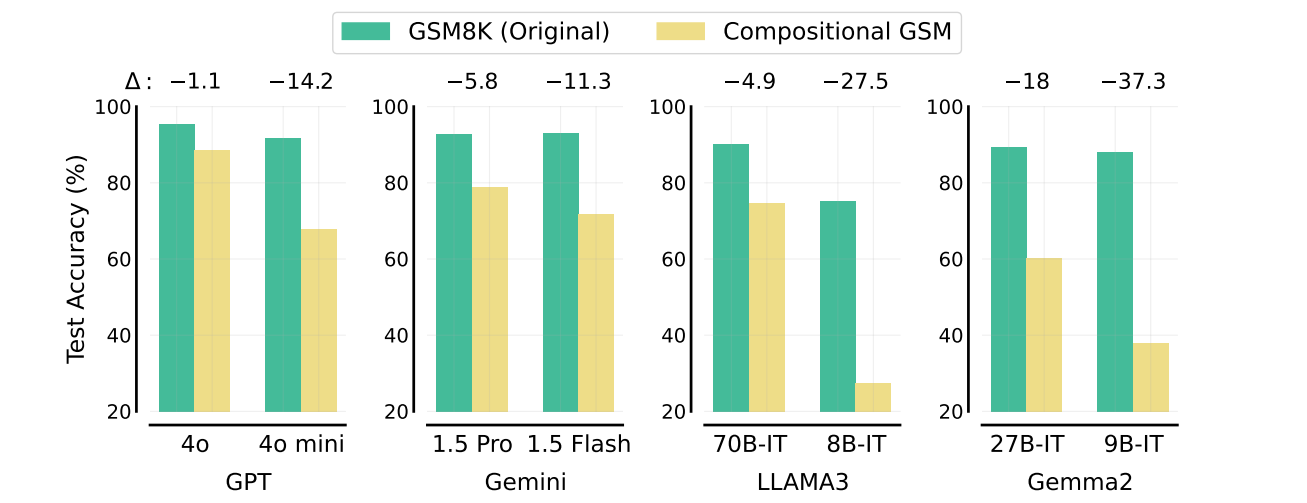
The researchers suggest this indicates smaller models may recognize surface-level patterns in common tasks but struggle to apply that knowledge in new contexts. Current training methods for these models may focus too much on optimizing for standard benchmarks at the expense of general reasoning ability.
Even specialized math models showed weaknesses. For example, Qwen2.5-Math-7B-IT scores over 80% on difficult high school tasks but solves less than 60% of chained elementary school problems correctly.
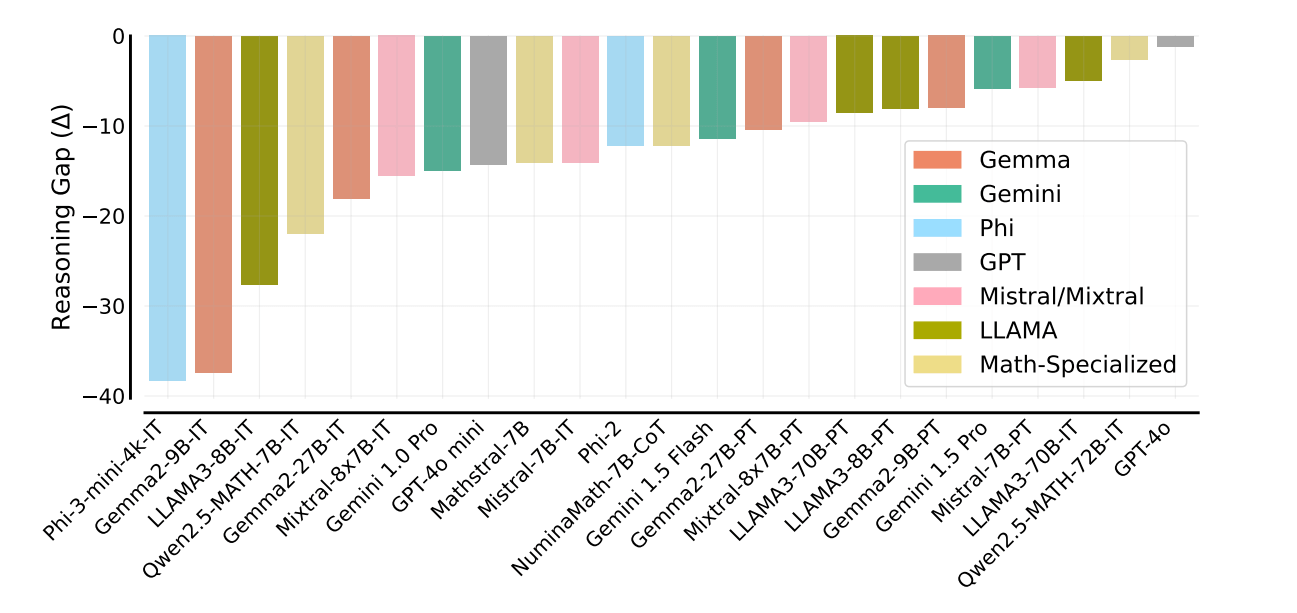
The small, mathematically specialized models show similar weaknesses. For example, Qwen2.5-Math-7B-IT achieves over 80 percent accuracy on difficult high school competition-level questions, but solves less than 60 percent of chained grade school problems correctly.
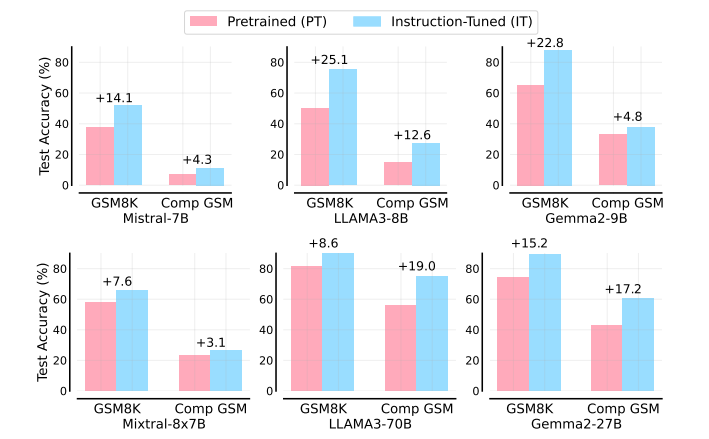
The study also examined the effects of instruction tuning, a method for refining language models. For small models, this significantly improved performance on the original GSM8K test but only slightly on Compositional GSM. Larger models didn't show this discrepancy, pointing to fundamental differences in how smaller models learn and generalize.
The study is not entirely up-to-date, as OpenAI's new logic-optimized o1 model was not tested. A recent planning benchmark showed that o1 is much better at planning, but still makes major mistakes.
A math professor recently showed that while o1 was able to complete a mathematical proof that had previously failed with other LLMs, a human solved the problem faster and more elegantly. Google's Gemini models are also said to perform better at math tasks after recent updates.
Beyond benchmarks: Testing true understanding
The researchers stress that current evaluation methods have masked these systematic differences, leading to potential overestimation of small model capabilities. They call for a re-evaluation of development strategies for low-cost AI systems, and question whether these models have inherent limitations in complex reasoning and generalization. This could have significant implications for their practical applications.
The results also challenge recent claims of AI efficiency gains. While some argue that language models have become more efficient rather than more capable, and that scaling these efficient models could lead to significant performance improvements, this study suggests otherwise.
The authors emphasize that their goal wasn't to create another benchmark. Instead, they view their work as a case study providing deeper insights into the functioning and limitations of current AI systems. By chaining tasks, they test whether models can flexibly apply and combine learned knowledge - a crucial distinction between true understanding and superficial pattern matching.
The researchers hope their methodology can be applied to other domains and benchmarks, providing a more comprehensive picture of AI capabilities. This approach could reveal hidden weaknesses in AI systems that might otherwise go unnoticed in simpler, isolated tests.
The study adds to existing evidence of logical weaknesses in language models. Previous research has shown LLMs struggle with basic logical inferences and simple planning puzzles, despite high scores on common logic and math benchmarks.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.