Tiny open-source image model Meissonic offers impressive image quality for its size

A new open-source AI model called Meissonic can generate high-quality images using only a billion parameters. This compact size could enable local text-to-image applications, especially on mobile devices.
Researchers from Alibaba Group, Skywork AI, and several universities developed Meissonic using a unique transformer architecture and novel training techniques. The model runs on average gaming PCs and could eventually run on mobile phones.
Meissonic uses masked image modeling, where parts of images are hidden during training. The model learns to reconstruct missing parts based on visible areas and text descriptions. This helps it to understand the relationships between image elements and text.
The model's architecture allows it to generate high-resolution images of 1024 x 1024 pixels: photorealistic scenes as well as stylized text, memes, or cartoon stickers, just like much larger models.
Unlike typical autoregressive models that generate images sequentially, Meissonic predicts all image tokens simultaneously through parallel, iterative refinement. The researchers say this non-autoregressive approach reduces decoding steps by about 99%, significantly speeding up image creation.
Meissonic combines multimodal and monomodal transformer layers. Multimodal layers capture text-image interactions, while monomodal layers refine visual representations. The researchers found that a 1:2 ratio between these layer types worked best.
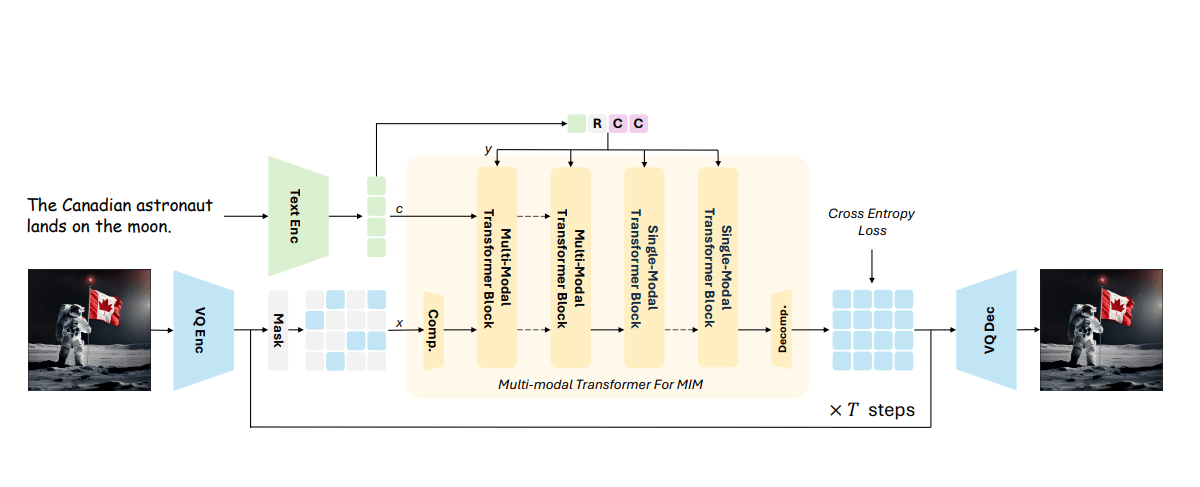
The researchers trained Meissonic using a four-step process. First, they taught the model basic concepts using 200 million images at 256 x 256 pixel resolution. Next, they improved its text comprehension with 10 million carefully filtered image-text pairs at 512 x 512 resolution.
In the third step, they added special compression layers to enable 1024 x 1024 pixel output. Finally, they fine-tuned the model using low learning rates and incorporated human preference data to refine its performance.
Meissonic can outperform much larger models
Despite its small size, Meissonic outperformed larger models like SDXL and DeepFloyd-XL on benchmarks including Human Preference Score v2. It scored 28.83 on HPSv2, higher than the other models.


Meissonic can also perform inpainting and outpainting without additional training. The researchers show examples of changing image backgrounds, styles, and objects.

The researchers believe their approach could enable faster, cheaper development of custom AI image generators. It could also drive the development of on-device text-to-image applications for mobile devices.
A demo is available on Hugging Face, and the code is available on GitHub. The model runs on consumer GPUs with 8GB of VRAM.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.