Repeated "write better code" prompts can make AI-generated code 100x faster
A simple request to "write better code" helped Sonnet 3.5 create code that runs 100 times faster than its first attempt, while adding unexpected (and unwanted) features typically found in enterprise software.
BuzzFeed Senior Data Scientist Max Woolf recently ran an experiment: what happens when you repeatedly tell Claude 3.5 to "write better code"? The results were surprising - not just in terms of performance gains, but in what the LLM decided "better" meant.
Woolf started with a classic programming challenge: write Python code to find the difference between the largest and smallest numbers with a digit sum of 30 in a million random numbers between 1 and 100,000. After getting Claude's first solution, he simply kept prompting it to "write better code."
The results were dramatic. The original code took 657 milliseconds to run. By the final iteration, it was down to just 6 milliseconds - a 100x speedup. But raw performance wasn't the only surprise.
Enterprise features appear out of nowhere
In its fourth and final "write better code" iteration, Claude spontaneously transformed the code into what looked like an enterprise application, adding typical corporate features without being asked. This suggests the LLM has somehow linked the concept of "better code" with "enterprise-grade software" - an interesting window into its training.
Developer Simon Willison offers an explanation for why this iterative improvement works: language models like Claude start fresh with each new prompt - they don't build up knowledge or memory over time like humans do. When asked to "write better code," Claude gets the entire previous conversation as context but analyzes it like unfamiliar code it's seeing for the first time.
This explains the continuous improvements - the LLM approaches the code with fresh eyes each time, unconstrained by previous attempts or preconceptions about what the "right" solution should be.
Prompt Engineering isn't going anywhere
When Woolf tried again with more specific prompts, he got better results faster, but ran into subtle bugs that needed human fixes. He emphasizes that careful prompt engineering is worth the effort, and argues that as AI models get more sophisticated, precise guidance becomes more important, not less.
"Although it’s both counterintuitive and unfun, a small amount of guidance asking the LLM specifically what you want, and even giving a few examples of what you want, will objectively improve the output of LLMs more than the effort needed to construct said prompts", Woolf writes.
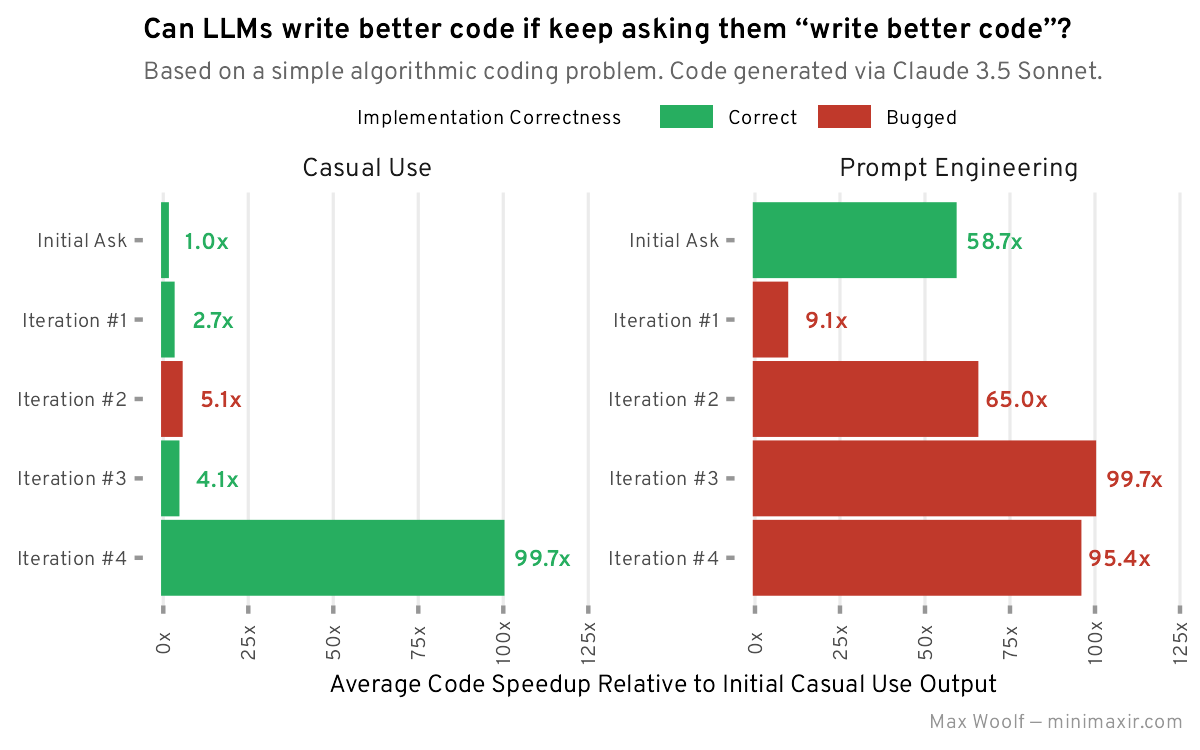
Interestingly, in both experiments, Claude skipped optimizations that seemed obvious to human developers, like removing duplicates or sorting numbers first. And even minor changes in how you phrase requests can dramatically affect Claude's output.
Woolf is careful not to overstate AI's capabilities. While the performance gains are impressive, human developers are still essential for verifying solutions and troubleshooting. Despite what some AI enthusiasts may claim, we're not yet in the era of perfect, automatically generated code.
"Even if LLMs can be wrong, one notable thing I learnt from these experiments is that they do have interesting ideas and tool suggestions even if the code output can’t be used as-is," Woolf writes.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.