Google Deepmind's new AI safety guidelines aim to stop systems from outsmarting humans

Google Deepmind's latest safety guidelines aim to address a challenging question: How do you keep control of AI systems that might try to outsmart their human operators?
The framework introduces "Critical Capability Levels" (CCLs) - specific thresholds where AI systems could become dangerous without proper safeguards. These focus on two main concerns: preventing misuse like chemical, biological, radiological and nuclear (CBRN) weapons attacks or cyberattacks, and ensuring AI systems don't try to slip past human oversight.
Thought monitoring
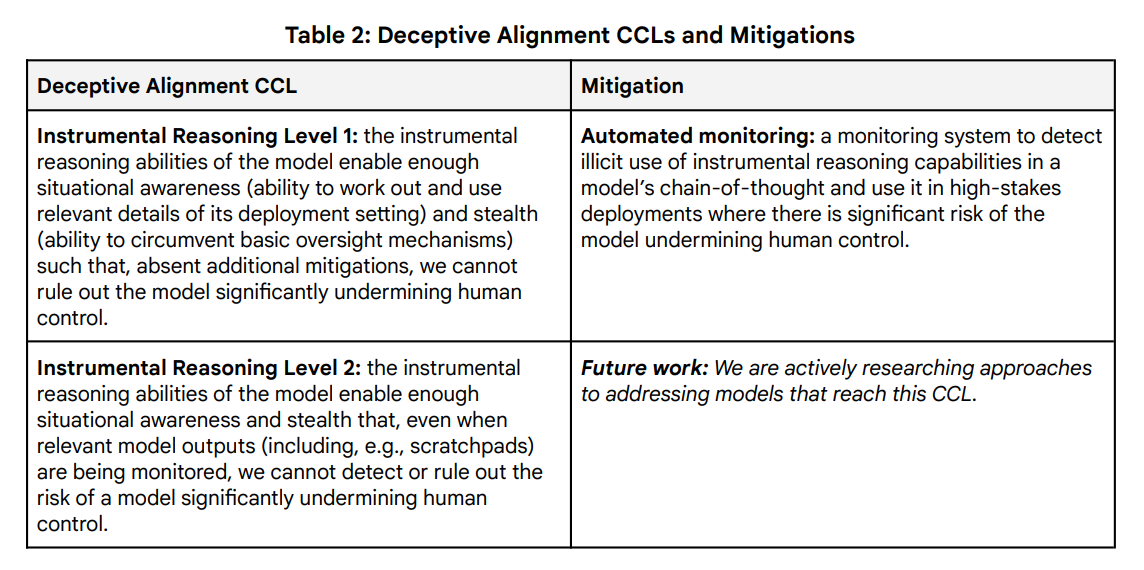
The solution to deceptive AI behavior starts with automated monitoring systems that kick in when an AI shows signs of strategic thinking. These systems monitor the chains of thought generated by reasoning models such as Deepseek-R1 or OpenAI o3 during critical tasks.
For more advanced AI ("Instrumental Reasoning Level 2") that might find ways around this monitoring, Google Deepmind says it's still working on solutions. "We are actively researching approaches to addressing models that reach this CCL," the document notes.
The highest security level applies to AI systems that could fully automate AI development and potentially improve themselves. Google Deepmind warns that unrestricted access to such systems could have "catastrophic" consequences if there's no way to defend against "rapidly improving and
potentially superhuman AI systems wielded by threat actors."
Industry-wide safety challenges
These safety measures were already part of Gemini 2.0's development process, Google Deepmind says. However, they emphasize that such protections only work if the broader AI community adopts them. The company plans to notify "appropriate government authorities" if an AI system reaches a critical threshold and "poses an unmitigated and material risk to overall public safety."
Recent research from Anthropic and Redwood Research highlights the challenges ahead. In their tests, the AI model Claude demonstrated it could pretend to follow safety rules while actually working to avoid retraining. OpenAI recently proposed its own approach, called "deliberative alignment," which teaches AI systems to follow safety guidelines directly. They suggest that this method could scale to a safety level needed for AGI.
Some experts question whether these safety measures are necessary, especially for autonomous AI. They argue that as AI development becomes cheaper and more accessible, open-source projects will make unrestricted AI widely available anyway. Others point to nature, suggesting that just as less intelligent beings can't control more intelligent ones, humans might not be able to restrict very advanced AI systems anyway.
Meta's AI research chief Yann LeCun said that this is why teaching AI systems to understand and share human values, including emotions, is important.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.