"Highlighted Chain of Thought" prompting boosts LLM accuracy and verifiability

A novel prompting method called "Highlighted Chain of Thought" (HoT) helps large language models better explain their reasoning and makes their answers easier for humans to verify.
The approach works in two steps: First, the AI reformulates the original question and marks important facts using XML tags. Then, it generates an answer that references these highlighted facts, creating clear connections between the question and response.
This structured approach forces models to more carefully consider the facts presented, which may reduce hallucinations, according to the researchers. The color-coded highlights also make it faster for humans to verify the AI's reasoning.

The research team used 15 human-annotated question-answer pairs to train AI models to independently generate highlights through prompting. Testing shows HoT improves AI accuracy across various tasks. At its best, the technique achieved improvements up to 15 percent, varying by model and benchmark.
Compared to the traditional chain-of-thought (CoT) method used to train current reasoning models like OpenAI o1, HoT increased accuracy by 1.6 percentage points for arithmetic tasks, 2.58 points for question-answering, and 2.53 points for logical reasoning.
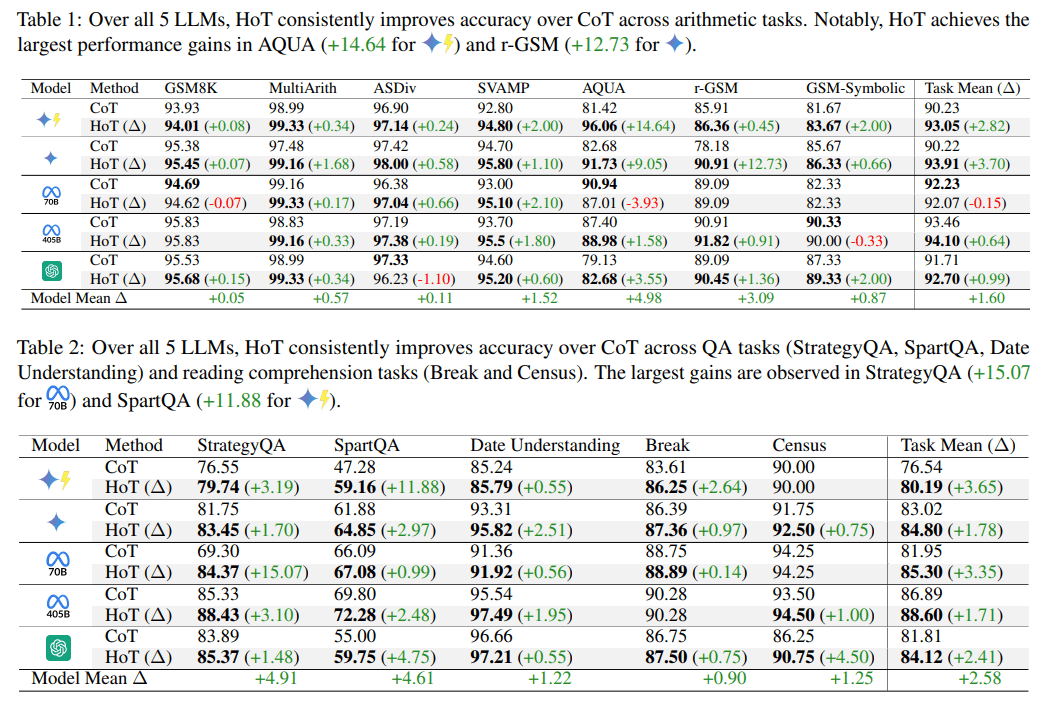
The researchers tested HoT across five AI models: GPT-4o, Gemini-1.5-Pro, Gemini-1.5-Flash, Llama-3.1-70B, and Llama-3.1-405B. They evaluated 17 different task types covering arithmetic, reading comprehension, and logical thinking.
Reasoning models showed little to no benefit from HoT in testing, and in some cases performed worse, with Deepseek-R1 actually showing slightly decreased performance. The researchers attribute this to the example-based prompting approach, which can lead to poorer results with reasoning models.
Mixed results for human verification
Human testers completed verification tasks 25 percent faster with highlighted answers. However, the highlighting had an unexpected effect on trust: Users became more likely to accept AI answers, even incorrect ones.
With highlighting, humans correctly identified accurate answers 84.5 percent of the time, compared to 78.8 percent without highlighting. However, their ability to spot wrong answers dropped from 72.2 percent to 54.8 percent when highlighting was present. Tests using AI models as verifiers showed no clear improvement.

The researchers remain optimistic about HoT's potential to make AI systems more transparent and comprehensible, though they acknowledge more research is needed on how highlighting affects user trust.
The method also has technical limitations. Smaller models such as Llama-3.1-8B and Qwen-2.5-Coder-32B struggle to follow tagging instructions, often tagging results incorrectly or simply repeating examples. The research also found that moving tags to random phrases significantly affects accuracy, highlighting the importance of consistent tagging between questions and answers.
Looking ahead, the team plans to train AI models to generate HoT answers directly rather than using prompt examples, which could make the method more effective and widely applicable.
The research paper is available on the preprint server arXiv and on a project page. The researchers make their code and data available on Github.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.