Irrelevant input causes LLM failures — what it means for writing effective prompts

A recent study from the Massachusetts Institute of Technology examines how large language models (LLMs) respond to systematic disruptions in prompt design when solving math word problems. The findings indicate that even minor additions of irrelevant context can significantly degrade performance.
The researchers tested 13 open- and closed-source LLMs—including Mixtral, Mistral, Llama, and Command-R—using questions from the GSM8K dataset, which focuses on grade school-level arithmetic problems. Four types of prompt perturbations were introduced:
- Irrelevant context, such as Wikipedia entries or financial reports, occupying up to 90 percent of the input window
- Unusual instructions, such as "Add a color in front of each adjective"
- Additional but non-essential context that was topically relevant but not needed to solve the problem
- A combination of relevant context and misleading instructions
The most significant drop in performance came from irrelevant context, which reduced the number of correctly solved problems by an average of 55.89 percent. Unusual instructions led to an 8.52 percent decline, while non-essential relevant context caused a 7.01 percent drop. When both types of interference were combined, performance fell by 12.91 percent.
Larger models show no immunity
Contrary to what many might expect, the size of a model offered no protection against these issues. Mixtral, the largest model tested with 39 billion active parameters, actually showed the worst performance degradation.
Mid-sized models like Mistral-7B and Llama-3.2-3B performed somewhat better, though Llama-3.1-8B completely failed to respond when given irrelevant context. Even OpenAI's GPT-4o wasn't immune, losing up to 62.5 percent of its accuracy when faced with irrelevant contextual information.
The complexity of the tasks—measured by the number of required calculation steps—had little impact on how susceptible the models were to prompt interference. Performance remained relatively consistent across different levels of task difficulty.
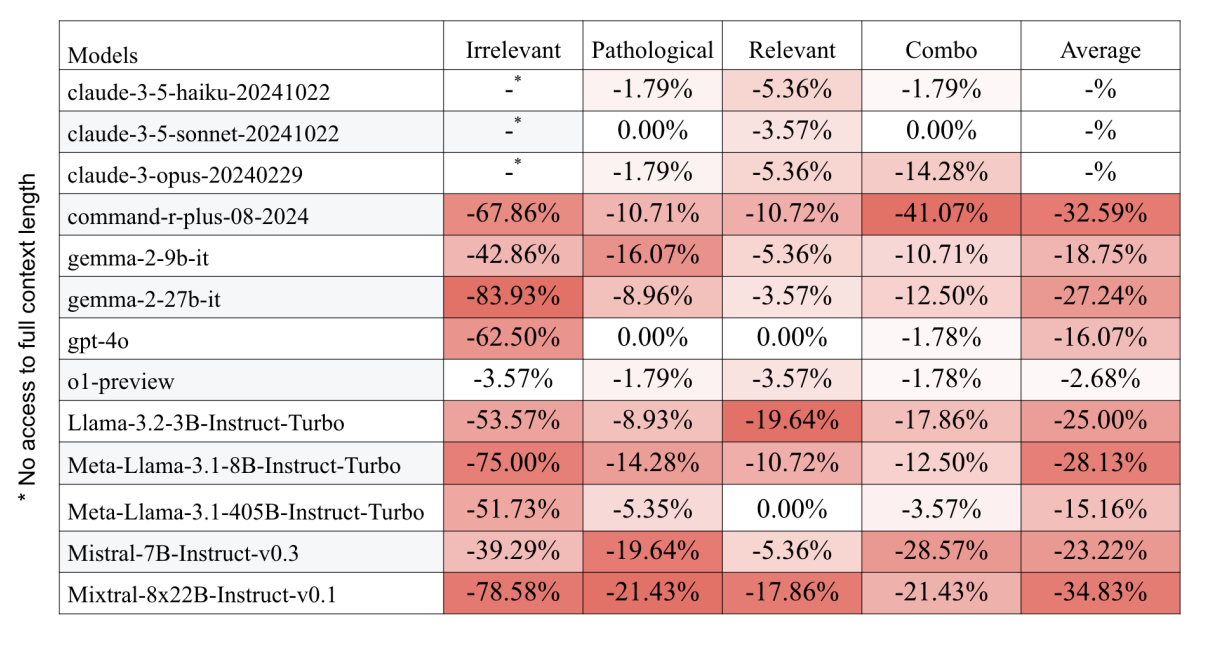
One interesting outlier stands out in the data: The reasoning-focused model "o1-preview" barely flinched at the various distractions, performing far better than traditional LLMs. The success raises some questions though - is this because the model is specifically tuned for math problems like those in the study, or has it actually developed better reasoning skills for sorting relevant from irrelevant information? From a practical standpoint, the distinction might not matter as long as the approach works.
However, an Apple study from October 2023 adds an important counterpoint. According to that research, even reasoning models can be thrown off by irrelevant information, as they merely imitate logical patterns rather than truly understanding logic.
Real-world robustness remains an open challenge
According to the authors, the study shows how susceptible today's LLMs are to realistic disturbances. These kinds of disruptions happen frequently in real-world applications, showing up as editorial introductions, extra background information, or contradictory references.
The research team calls for a new approach: developing training methods and architectures specifically designed to handle messy, real-world contexts. They also point out the need for more realistic testing benchmarks that better reflect actual use conditions, rather than the carefully cleaned formats currently used in most evaluations.
Implications for Prompt design
The results of the study show that when irrelevant information appears in prompts, model performance drops dramatically. This means that prompts should be clear, concise, and reduced to essential information. Even if additional details are factually correct, they can mislead or confuse models. The key is to focus only on information that directly helps solve the task at hand.
Before engaging with an LLM, users should carefully preprocess their input data to include only task-relevant information. Long chat sessions pose a particular challenge since they accumulate context that can interfere with performance. A better approach is breaking complex tasks into separate conversations, each with its own focused prompt.
The research highlights how LLMs struggle to distinguish between relevant and irrelevant information. To address this limitation, prompt designers should create clear separations between contextual information and the actual task, using techniques like precise formatting and descriptive headings. This makes it immediately clear to the model what information matters for solving the problem.
However, the study suggests that even carefully crafted prompts aren't a complete solution. While following these design principles can help, LLM performance remains unpredictable when faced with various types of contextual interference. Better prompt design improves results but doesn't eliminate the fundamental reliability challenges these models face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.