Researchers use popular "Ace Attorney" video game to test how well AI can actually reason

Researchers have put leading AI models through a new kind of test—one that measures how well they can reason their way to a courtroom victory. The results highlight some clear differences in both performance and cost.
A team from the Hao AI Lab at the University of California San Diego evaluated current language models using "Phoenix Wright: Ace Attorney," a game that requires players to collect evidence, spot contradictions, and expose the truth behind lies.
According to Hao AI Lab, Ace Attorney is particularly suitable for this test because it requires players to collect evidence, uncover contradictions and uncover the truth behind lies. The models had to sift through long conversations, spot inconsistencies during cross-examination, and select the appropriate evidence to challenge witness statements.
The experiment was partly inspired by OpenAI co-founder Ilya Sutskever, who once compared next-word prediction to understanding a detective story. Sutskever recently secured additional multi-billion-euro funding for a new AI venture.
o1 leads, Gemini follows
The researchers tested several top multimodal and reasoning models, including OpenAI o1, Gemini 2.5 Pro, Claude 3.7-thinking, and Llama 4 Maverick. Both o1 and Gemini 2.5 Pro advanced to level 4, but o1 came out ahead on the toughest cases.
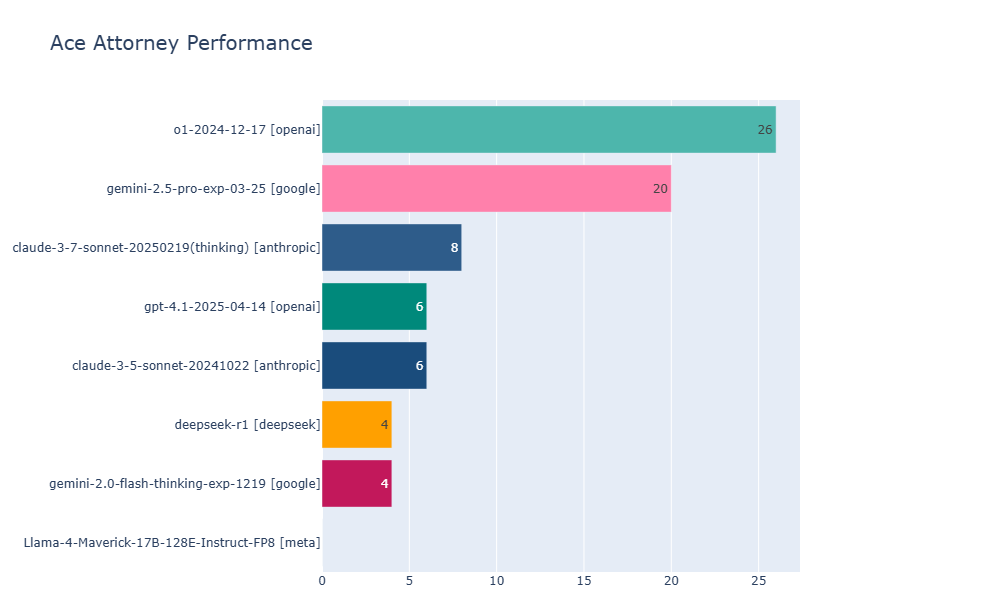
The test goes beyond simple text or image analysis. As the team explains, models have to search through long contexts and recognize contradictions in them, understand visual information precisely and make strategic decisions in the course of the game.
"Game design pushes AI beyond pure textual and visual tasks by requiring it to convert understanding into context-aware actions. It is harder to overfit because success here demands reasoning over context-aware action space - not just memorization," the researchers explain.
Overfitting occurs when a language model memorizes its training data—including all randomness and errors—so it performs poorly on new, unfamiliar examples. This issue also arises with reasoning models optimized for math and code tasks. These models may become more efficient at finding the correct solutions, but they also reduce the diversity of paths considered.
Gemini 2.5 Pro offers better price-performanc
Gemini 2.5 Pro turned out to be significantly more cost-efficient than the other models tested. Hao AI Lab reports that it is six to fifteen times cheaper than o1, depending on the case. In one particularly lengthy Level 2 scenario, o1 incurred costs exceeding $45.75, while Gemini 2.5 Pro completed the task for $7.89.
Gemini 2.5 Pro also outperformed GPT-4.1—which is not specifically optimized for reasoning—in terms of cost, at $1.25 per million input tokens compared to $2 for GPT-4.1. The researchers note, however, that the actual costs could be slightly higher due to image processing requirements.
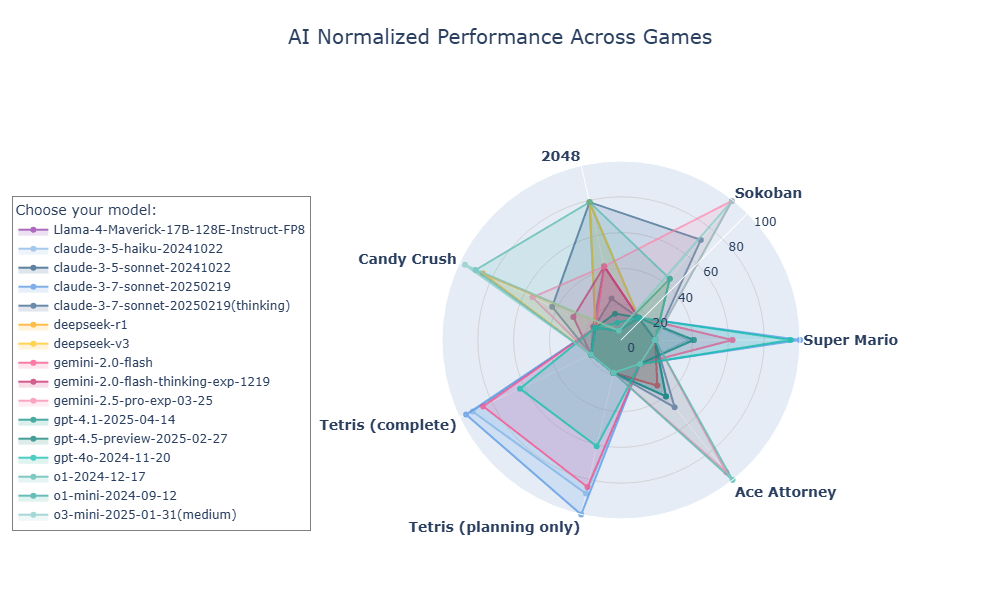
Since February, the team has been benchmarking language models on a range of games, including Candy Crush, 2048, Sokoban, Tetris, and Super Mario. Of all the titles tested so far, Ace Attorney is likely the game with the most demanding mechanics when it comes to reasoning.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.