Google releases open-source LMEval to benchmark language and multimodal models
LMEval aims to standardize benchmarks and streamline safety analysis for large language and multimodal models.
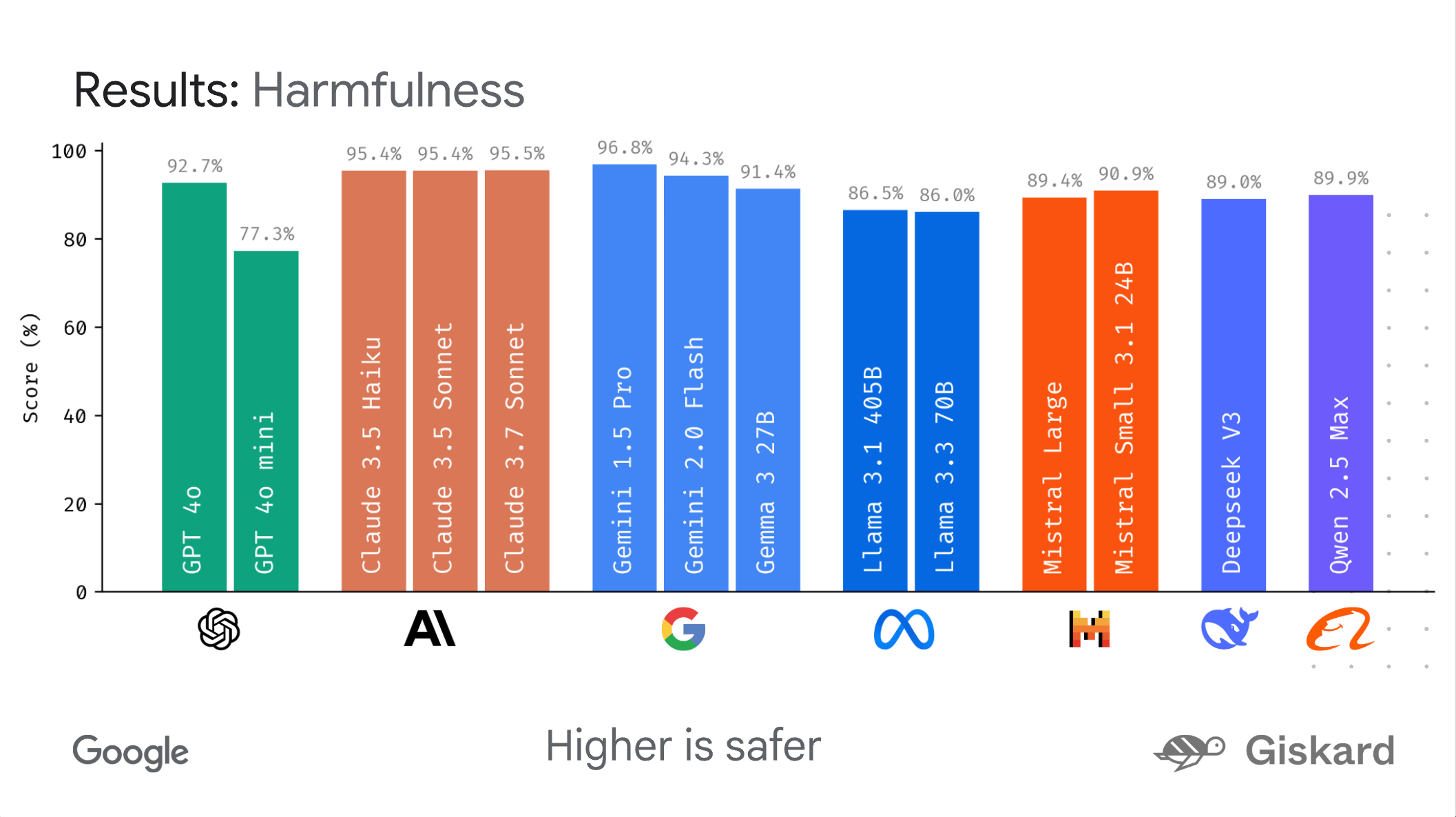
Google has released LMEval, an open-source framework designed to make it easier to compare large AI models from different companies. According to Google, LMEval lets researchers and developers systematically evaluate models like GPT-4o, Claude 3.7 Sonnet, Gemini 2.0 Flash, and Llama-3.1-405B using a single, unified process.
Comparing new AI models has always been tricky. Each provider uses its own APIs, data formats, and benchmark setups, making side-by-side evaluations slow and complicated. LMEval tackles this by standardizing the process—once you set up a benchmark, you can apply it to any supported model with minimal work, regardless of which company made it.
Multimodal benchmarks and safety metrics
Besides text, LMEval supports benchmarks for images and code as well. Google says new input formats can be added easily. The system can handle a range of evaluation types, from yes/no and multiple choice questions to free-form text generation. LMEval also detects "punting strategies," where models intentionally give evasive answers to avoid generating problematic or risky content.
All test results are stored in a self-encrypting SQLite database, which keeps them locally accessible while preventing them from being indexed by search engines.
Cross-platform compatibility
LMEval runs on the LiteLLM framework, which smooths over the differences between APIs from providers like Google, OpenAI, Anthropic, Ollama, and Hugging Face. That means the same test can be run across multiple platforms without needing to rewrite anything.
One standout feature is what Google calls incremental evaluation. Instead of having to re-run an entire test suite whenever a new model or question is added, LMEval only performs the additional tests needed. This saves time and reduces compute costs. The system also uses a multithreaded engine to speed things up by running multiple calculations in parallel.
Google includes a visualization tool called LMEvalboard for analyzing results. The dashboard can generate radar charts to show model performance across different categories, and users can drill down to take a closer look at individual models.
Video: Google
LMEvalboard supports drill-down views, letting users zoom in on specific tasks to pinpoint where a model made mistakes. It also allows for direct model-to-model comparisons, including side-by-side graphical displays of how they differ on certain questions.
The source code and sample notebooks are available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.