AI-generated CUDA kernels outperform PyTorch in several GPU-heavy machine learning benchmarks
A team at Stanford has shown that large language models can automatically generate highly efficient GPU kernels, sometimes outperforming the standard functions found in the popular machine learning framework PyTorch.
These so-called CUDA-C kernels are compact, specialized programs that run directly on Nvidia GPUs. They handle tasks like matrix multiplications and image processing, serving as the building blocks for many AI operations.
In the experiments, language models created CUDA kernels that were then benchmarked against PyTorch's built-in routines. PyTorch, developed in part by Meta, is widely used for machine learning and provides a library of pre-made GPU operations essential for AI workloads.
In several tests, the AI-generated kernels ran significantly faster than PyTorch's own code. For example, one kernel sped up layer normalization—a step that standardizes neural network values—by a factor of 4.8.
Other improvements showed up in image convolution (Conv2D), the softmax function (which turns raw outputs into probabilities), and a composite operation that combines convolution, ReLU activation (setting negative numbers to zero), and max-pooling (selecting the highest value from image regions). In several of these cases, the automatically generated code outpaced PyTorch.
Parallel search enables rapid code optimization
The research used a benchmark called KernelBench, where a language model tries to replace specific PyTorch operators with its own CUDA kernels to achieve faster GPU execution.
The team worked with OpenAI o3 and Gemini 2.5 Pro, two large language models that use parallel optimization strategies in multiple rounds. Each generated kernel was then checked for both correctness and speed.
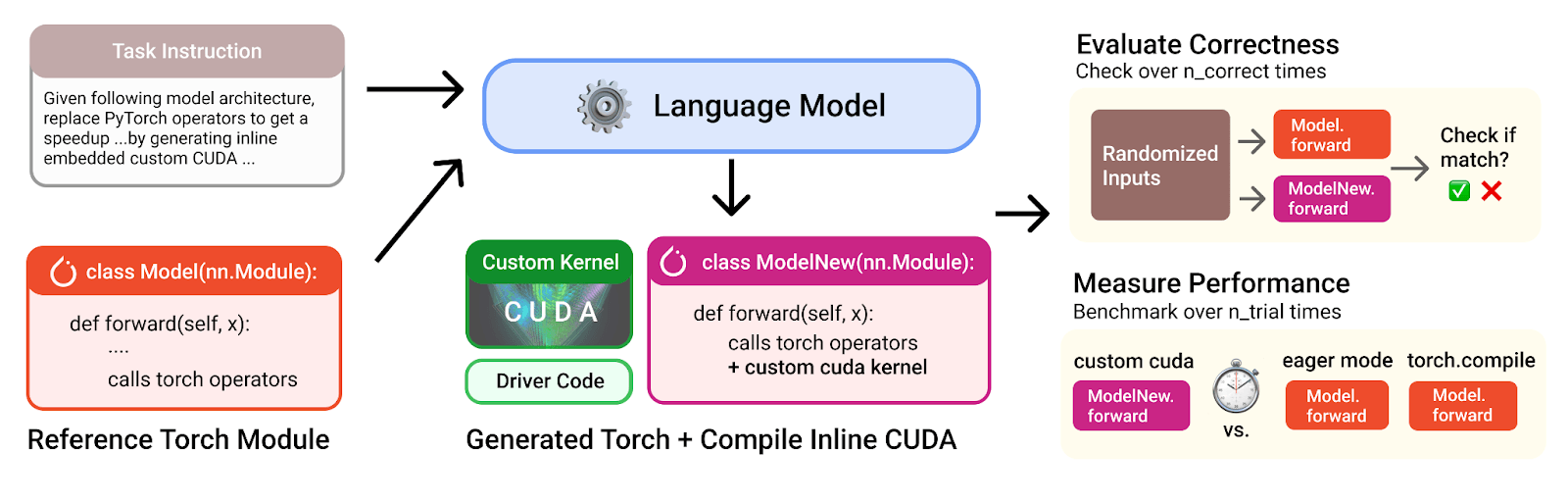
Unlike traditional approaches that tweak a kernel step by step, the Stanford method made two major changes. First, optimization ideas were expressed in everyday language. Then, multiple code variants were generated from each idea at once. All of these were executed in parallel, and only the fastest versions moved on to the next round.
This branching search led to a wider range of solutions. The most effective kernels used established techniques like more efficient memory access, overlapping arithmetic and memory operations, reducing data precision (for example, switching from FP32 to FP16), better use of GPU compute units, or simplifying loop structures.
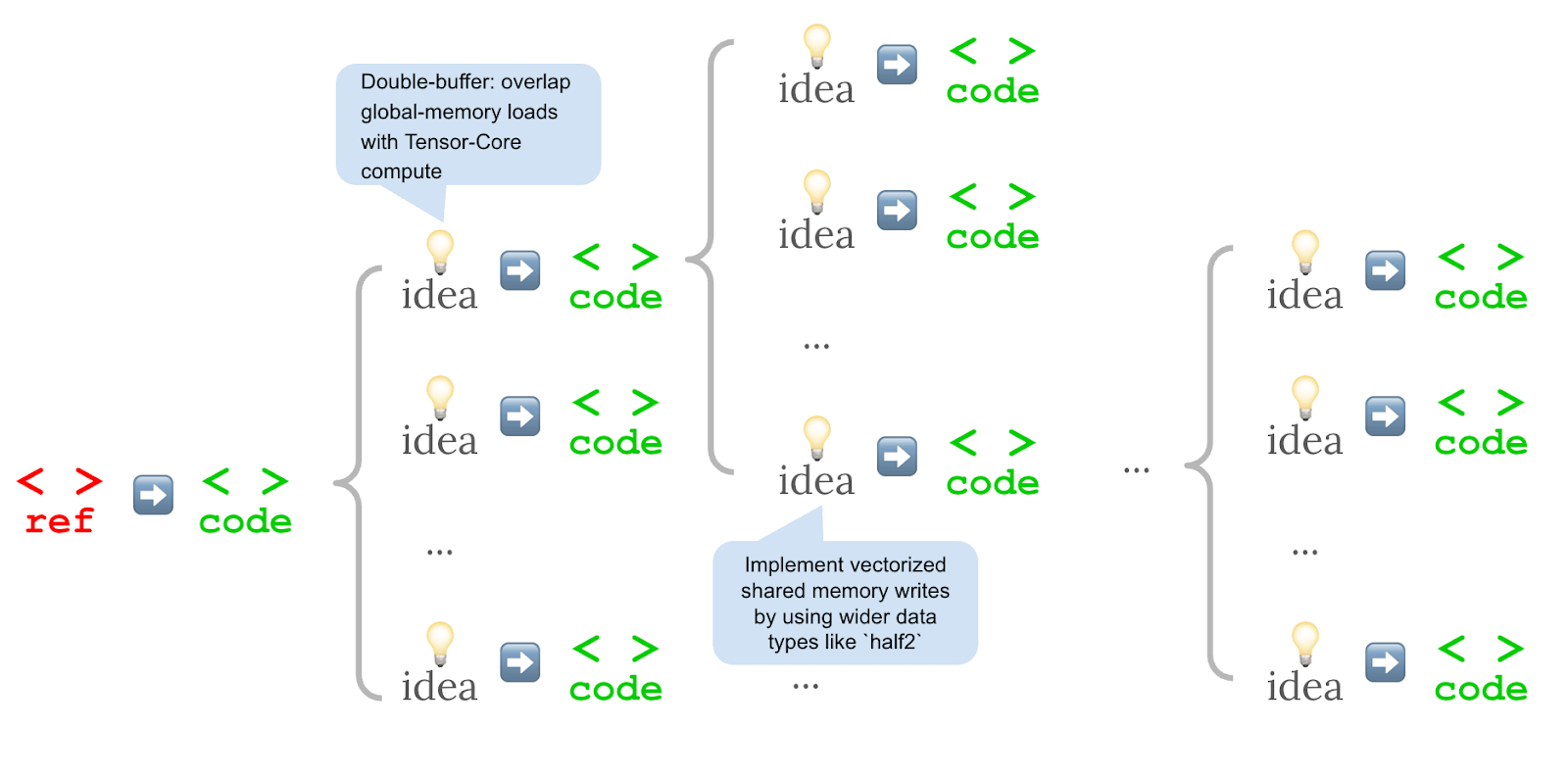
The researchers emphasize that their approach works alongside existing training methods rather than replacing them. Since the search process creates synthetic data, this information can help train future models. The result is a win-win: faster code at runtime and valuable training data for improving language models.
One example shows how an AI-generated kernel for image convolution (Conv2D) improved from 20 percent to nearly 180 percent of PyTorch's speed after 13 iterations. Conv2D is a fundamental operation in image processing, where input images are combined with filter matrices.
Key improvements included converting the convolution into a matrix multiplication that taps into the GPU's specialized tensor cores, using double buffering to overlap computation and memory access, and precomputing memory indices in shared memory for faster data retrieval.
The final version incorporated sophisticated CUDA programming techniques that you'd typically only see from developers with years of GPU optimization experience.
Challenges with FP16
The team still has some kinks to work out. The AI-generated kernels struggle with newer AI tasks that use lower-precision data types like FP16. In one test, an FP16 matrix multiplication kernel only hit 52 percent of PyTorch's speed. Things looked even worse for Flash Attention, a memory-intensive technique used in large language models, where the AI-generated kernel crawled along at just 9 percent of PyTorch's pace.
But the researchers aren't discouraged. They point out that before this, no one could reliably generate these kinds of kernels automatically. Even with limited resources for their search process, the new approach is already making strides.
These findings line up with other recent work showing how parallel search strategies, when paired with powerful language models, can create impressive system components. We've seen similar results from projects like DeepMind's AlphaEvolve and the Deep Think feature of Gemini 2.5 Pro.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.