AI learns math reasoning by playing Snake and Tetris-like games rather than using math datasets
Researchers have found an unexpected way for multimodal AI models to learn mathematical reasoning: by playing simple arcade games like Snake and Tetris, rather than training on math datasets.
Traditionally, AI models gain expertise in a domain by processing large amounts of specialized data. But a new study from Rice University, Johns Hopkins University, and Nvidia takes a different approach. The team calls their method "Visual Game Learning" (ViGaL), using Qwen2.5-VL-7B as the foundation.
Games help models pick up transferable skills
The idea builds on findings from cognitive science showing that games can promote general problem-solving abilities. For their experiment, the researchers created two custom game environments based on Snake and Tetris, each designed to train different kinds of thinking.
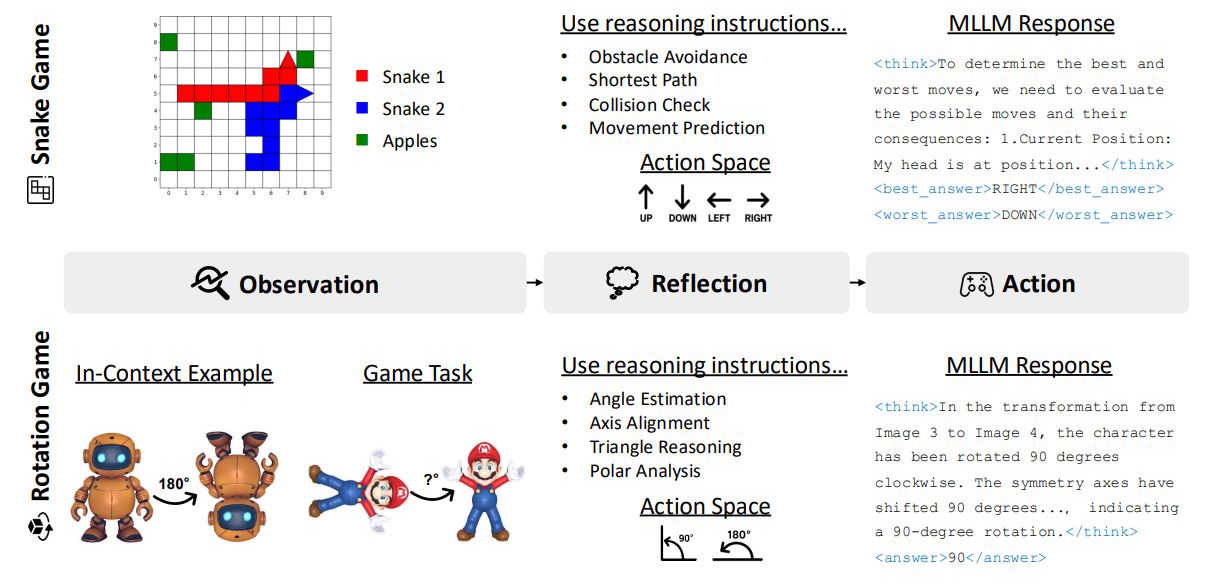
In Snake, the model played on a 10x10 grid, controlling two snakes as they competed for apples. In the Tetris-inspired rotation game, the model saw 3D objects from different angles and had to recognize them after 90 or 180 degree rotations.
They generated 36,000 training examples for each game, with difficulty that could be adjusted. For the 3D objects, the team used Hunyuan3D. Training on Snake boosted the model's performance on 2D coordinate and expression problems, while the rotation game improved its ability to estimate angles and lengths.
Snake training outperforms math datasets in some areas
Training on Snake and rotation problems nudged the base model slightly ahead of MM-Eureka-Qwen-7B, a model specifically trained on math data, with 50.6 percent accuracy compared to 50.1 percent on math benchmarks.
The gains were even more dramatic for geometry problems, where performance nearly doubled. Part of that came from MM-Eureka's weak results on the Geo3K geometry benchmark. Against other specialized models, the gap was smaller but still present.
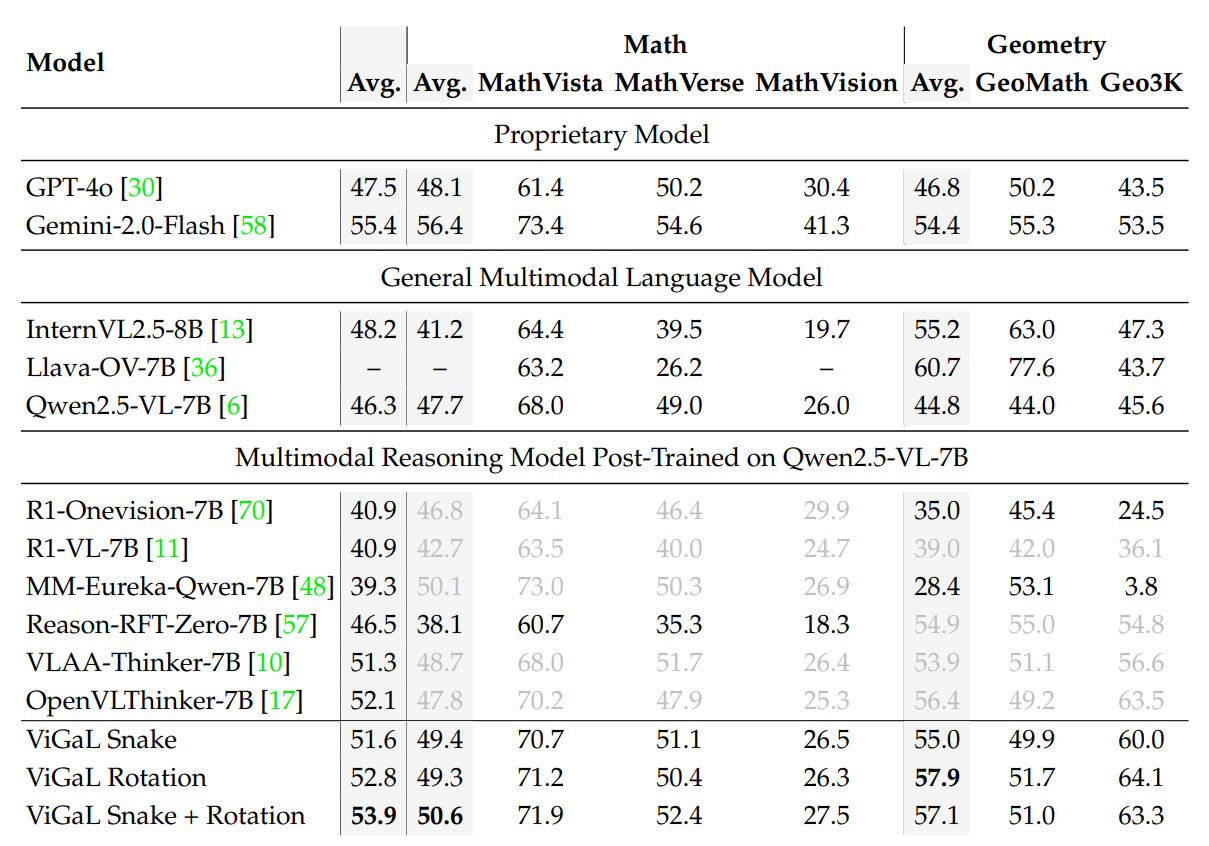
ViGaL also held up well against closed-source systems, posting 53.9 percent average accuracy across all benchmarks - higher than GPT-4o (47.5 percent), but just behind Gemini 2.0 Flash (55.4 percent).
On harder math problems, the small retrained model outperformed the much larger GPT-4o (64.7 percent vs. 55.9 percent). In more general tasks, ViGaL ranked just below its base model and trailed GPT-4o by a few percentage points.
Finally, the researchers put ViGaL through its paces on Atari games, which are quite different from its training environments. Here, it nearly doubled the base model's score.
Reinforcement learning beats fine-tuning
Step-by-step thinking instructions turned out to be key. Prompts like "find the nearest apple by calculating Manhattan distances" for Snake, or "identify important symmetry axes" for Rotation, improved accuracy by 1.9 percentage points.
Reward function design also mattered: the model had to identify both optimal and worst moves, with this contrastive learning adding another 1.8 points. Adjusting game difficulty - for example, varying snake length from 1 to 5 segments - further stabilized training.
All told, reinforcement learning with rewards boosted performance by 12.3 percent, while standard supervised fine-tuning on the same data actually made results worse, dropping accuracy by 1.9 percent. Scaling up the training data helped too: doubling the data improved results by another 1.3 points.
Toward a new training paradigm?
The results suggest a new direction for AI training. Rather than relying on expensive, human-labeled datasets, synthetic games could provide scalable training tasks that teach general reasoning skills. The researchers say future work could explore a broader range of game-based learning to build more robust AI.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.