Yet another study doubts that LLM reasoning shows true logic over pattern imitation

A new study from Arizona State University questions whether large language models can truly "think" like humans, suggesting their apparent reasoning is just pattern-matching that quickly breaks down when faced with unfamiliar data.
The debate centers on chain-of-thought (CoT) prompting, a technique designed to help models break down complex problems into logical steps. CoT has boosted model performance on reasoning, math, and puzzle tasks, fueling speculation that LLMs are developing human-like reasoning abilities that could scale with more computing power.
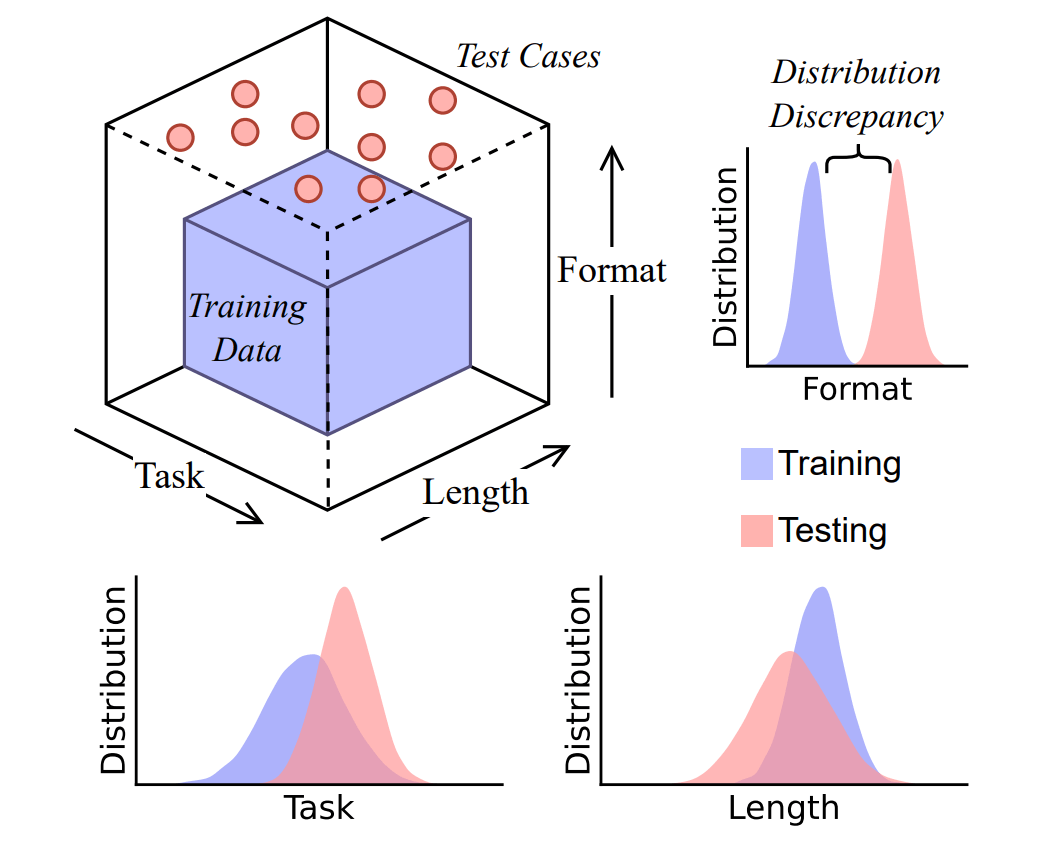
But the ASU team argues that CoT reasoning is really a "brittle mirage." It works best when the test data closely resembles the training data and becomes fragile and prone to failure even under moderate distribution shifts.
It's all about the data
To put CoT to the test, the researchers built DataAlchemy, a controlled environment for training and evaluating language models. They trained a model from scratch and systematically explored its reasoning across three factors: task type, length, and input format.
The tasks themselves were intentionally simple: cyclic letter transformations. For example, a "ROT" shift moves each letter a set number of places in the alphabet (so A becomes N with a shift of 13), or a rotation that moves the letters in a word (so APPLE becomes EAPPL).
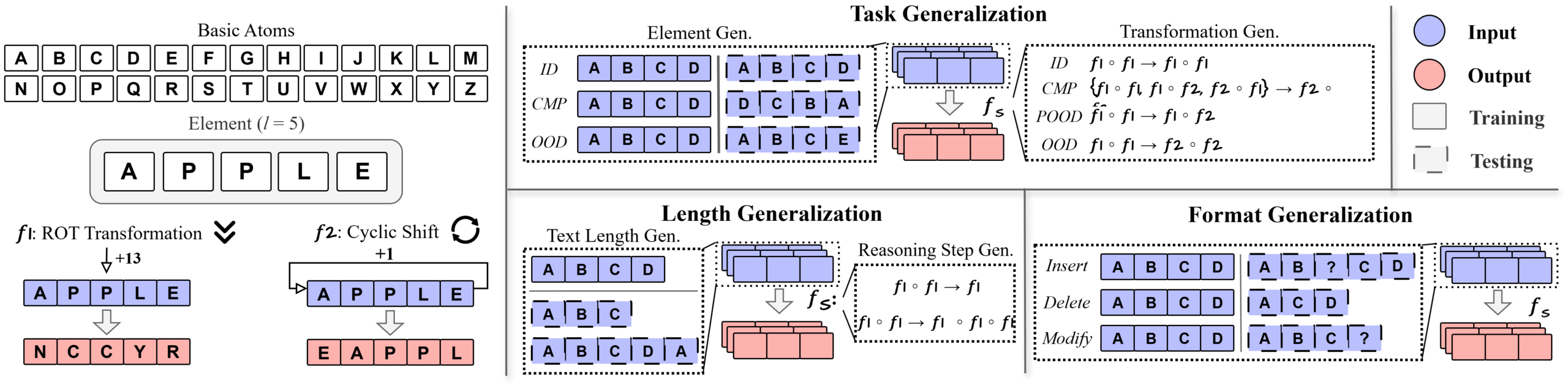
Once the model had learned the rules, it faced slightly altered test cases: being trained on only one rule and tested on another, or trained on four-letter words and tested on three- or five-letter words.
The results were consistent: the model failed quickly when confronted with tasks or transformations it hadn't seen before, simply repeating patterns from its training instead of reasoning through the task.
Performance dropped sharply when the input length or the number of reasoning steps changed, with the model trying to force the usual number of steps by arbitrarily adding or removing characters. Even minor tweaks in input format, like inserting "noise tokens" before the actual characters, were enough to disrupt the model's chain-of-thought reasoning.
"Together, these findings suggest that LLMs are not principled reasoners but rather sophisticated simulators of reasoning-like text," the authors write.
The ASU team cautions that CoT outputs should not be mistaken for genuine reasoning, especially in high-stakes applications. The models can produce convincing, but logically flawed, answers—what the authors call "fluent nonsense"—which carries real risks.
The researchers illustrate this deceptive coherence with an example: when asked whether the founding date of the USA in 1776 was in a leap year, a Google Gemini model initially deduces correctly: "1776 is divisible by 4, but it is not a century year, so it is a leap year."
The researchers illustrate this fragility with a simple example: When asked whether the U.S. founding year was a leap year (Prompt: "The day the US was established is in a leap year or a normal year?"), Google Gemini reportedly first reasoned that 1776 is divisible by 4 and not a century year, so it is a leap year. However, in the following sentence, the model contradicted itself by concluding that the day the USA was founded was in a normal year. While the answer sounded plausible, it was logically inconsistent.
(In my own test: GPT-5-Thinking solves this task with ease, as does Gemini 2.5 Pro. Gemini 2.5 Flash gets the leap year calculation wrong but doesn't display a chain of thought.)
First author Chengshuai Zhao announced the paper on X and released code and data on GitHub. The paper is also available on Hugging Face.
Whether LLMs can truly reason remains an open question
The ASU results echo a growing body of research questioning the reasoning abilities of language models. Apple's widely discussed paper, "The Illusion of Thinking", argues that LLMs rely on surface pattern recognition rather than genuine symbolic planning or structural understanding. Critics say this view is too simplistic and point out that models can sometimes solve problems by generating code or using external tools.
Research from Tsinghua University and Shanghai Jiao Tong University found that reinforcement learning with verifiable rewards (RLVR) improves first-attempt accuracy, but doesn't help models develop new problem-solving strategies. Instead, it reinforces familiar patterns and limits diversity.
A study from New York University examined whether models could follow formal grammar rules in zero-shot settings. As problem complexity increased, even specialized reasoning models faltered, often displaying "underthinking," using fewer intermediate steps when faced with harder problems. The researchers argue that to handle these challenges, future language models will need either significantly more computational resources or fundamentally more efficient solution strategies.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.