Deepseek’s first hybrid model V3.1 surpasses its R1 reasoning model on benchmarks
Deepseek is releasing Deepseek-V3.1, its first hybrid AI model with two operating modes. The company calls the new model its "first step toward the agent era," signaling a focus on building models with stronger agent skills.
V3.1 builds on the earlier Deepseek-V3 model, adding 840 billion more training tokens. The extra training is aimed at improving long-context understanding and performance on complex tasks. Deepseek has also updated the tokenizer and chat template.
Deepseek shifts toward Anthropic's hybrid approach
Deepseek-V3.1 lets users switch between two modes. Think mode (deepseek-reasoner) is tuned for multi-step reasoning and tool use, while non-think mode (deepseek-chat) is designed for simpler tasks. Both modes support a 128,000-token context window. The model switches between modes based on a special </think> token in the prompt.
Users can try the feature directly in Deepseek's chat interface using the "DeepThink" button at the bottom left. The approach closely resembles Anthropic's hybrid models like Opus and Sonnet.
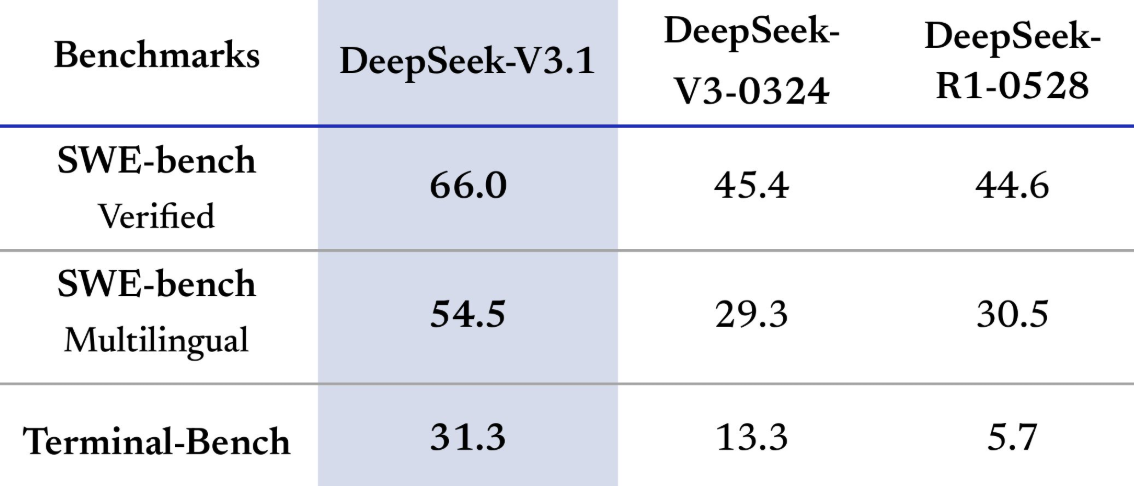
According to Deepseek, the model shows better results on benchmarks like SWE and Terminal-Bench and has "big gains in thinking efficiency." The company also reports that "Think Mode" is faster than its previous reasoning model, R1. The model architecture is unchanged, with 671 billion total parameters and 37 billion active.
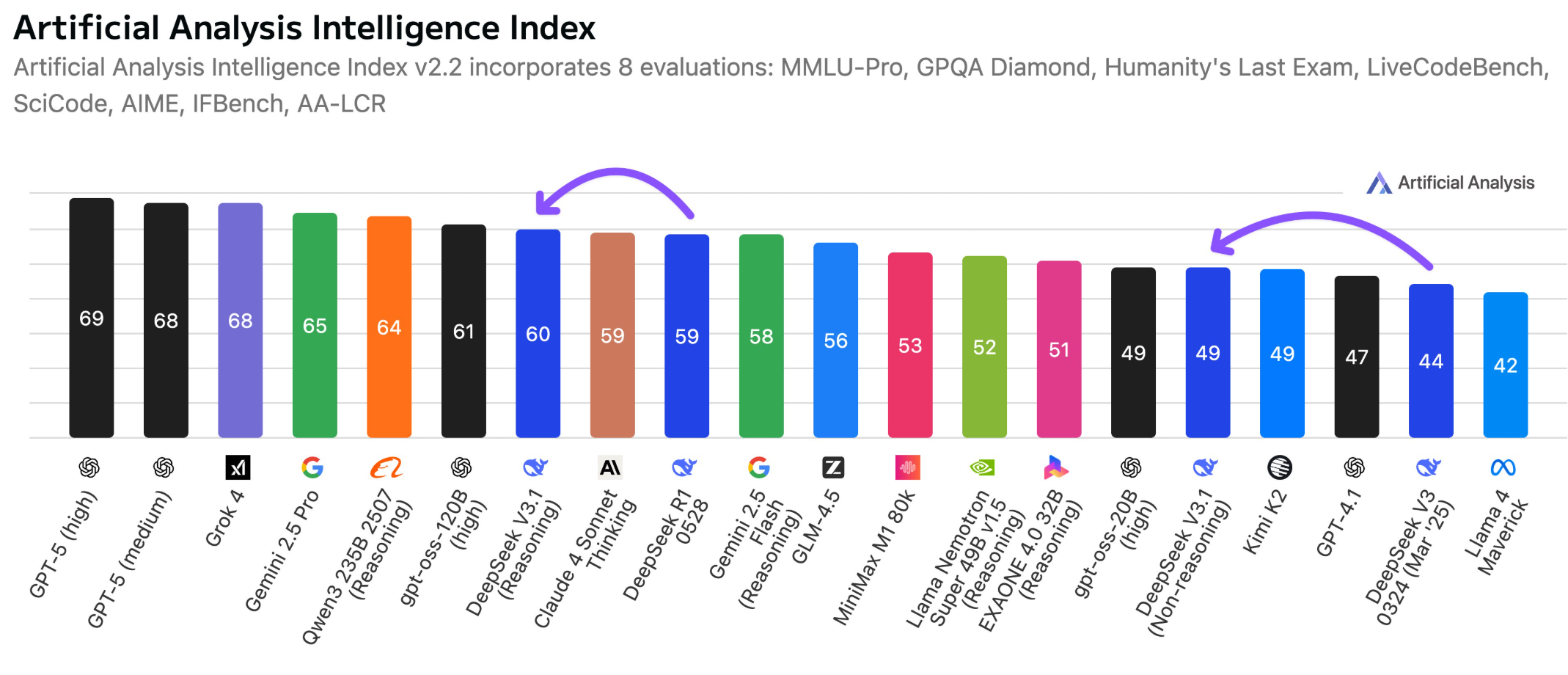
Artificial Analysis notes that V3.1 scores 60 on its intelligence index in reasoning mode, up slightly from R1's score of 59. Still, V3.1 lags Alibaba's latest model and "has not taken back the lead." It also performs slightly worse than OpenAI's recently released open-source reasoning model GPT-OSS.
The analysis also flags a key limitation: V3.1 does not support function calling in reasoning mode, which is "likely to substantially limit its ability to support agentic workflows." Competing models like GPT-5 Thinking and others can use tools such as image analysis or code generation within their chain of thought, giving them more options to boost overall performance.
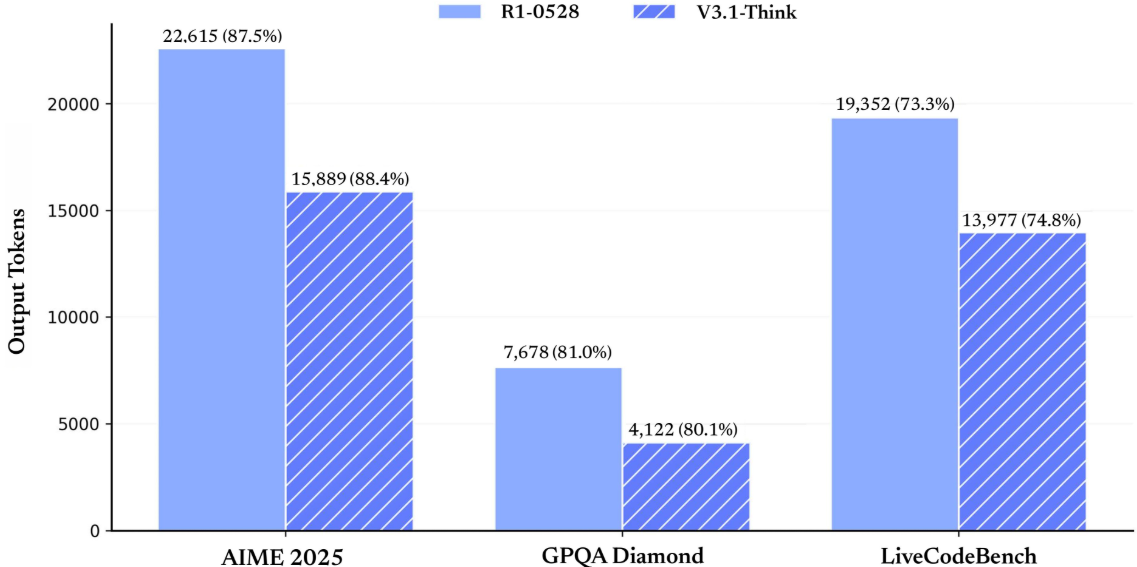
Artificial Analysis also notes that V3.1 uses slightly fewer tokens than R1 in reasoning mode and slightly more than V3 0324 in non-reasoning mode, but non-reasoning mode is still much more efficient overall.
Deepseek is dirt cheap
Along with the new model, Deepseek is introducing a new pricing structure starting September 5, 2025. Input API calls will cost $0.07 per million tokens for cache hits and $0.56 for cache misses. Output tokens are priced at $1.68 per million.
These rates are far lower than what competitors charge. Gemini 2.5 Pro is $10.00 per million output tokens ($15.00 for prompts over 200,000 tokens), OpenAI GPT-5 is $10.00 per million even after price cuts, and Anthropic Claude Opus 4.1 comes in at up to $75.00 per million.
Deepseek-V3.1 is available through two dedicated API endpoints. Support for the Anthropic API format and beta strict function calling should make development easier. The open-source weights are available on Hugging Face, and both the source code and weights are MIT licensed.
As with other Chinese AI models, Deepseek-V3.1 applies content restrictions and adapts certain answers to align with government guidelines. Similar limitations may be coming to the US, as the Trump administration is pushing for new regulations on how American AI models handle so-called "woke" topics.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.