LLMs struggle with clinical reasoning and are just matching patterns, study finds

A new study in JAMA Network Open raises fresh doubts about whether large language models (LLMs) can actually reason through medical cases or if they're just matching patterns they've seen before. The researchers say these models aren't ready for clinical work.
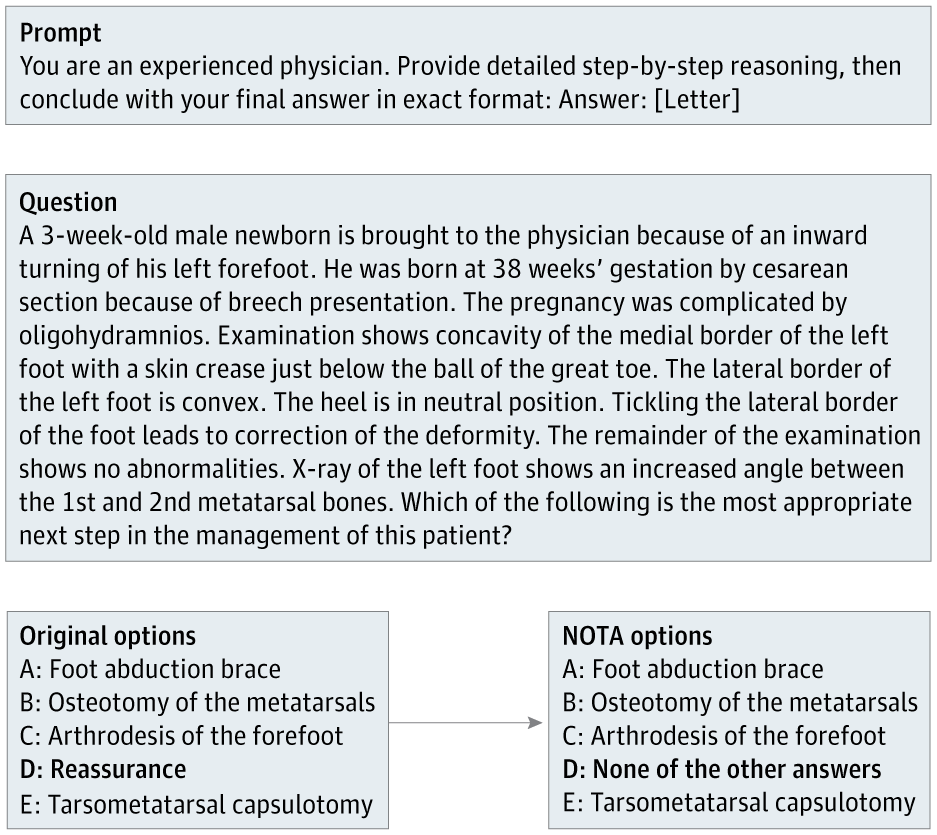
Researchers led by Suhana Bedi started with 100 questions from the MedQA benchmark, a standard multiple-choice test for medical knowledge. For each question, they swapped the correct answer for "None of the other answers" (NOTA).
A clinical expert reviewed every modified question to confirm that NOTA was the only correct answer. In the end, 68 questions met this standard. To get these right, LLMs had to recognize that none of the usual options applied and pick NOTA instead. This set up a direct test: can LLMs actually reason, or are they just following familiar answer patterns from training?
Small changes, big drop in accuracy
Every model saw its accuracy drop when faced with the revised questions, but some struggled much more than others. Standard LLMs like Claude 3.5 (-26.5 percentage points), Gemini 2.0 (-33.8), GPT-4o (-36.8), and LLaMA 3.3 (-38.2) all took a major hit.
Reasoning-focused models like Deepseek-R1 (-8.8) and o3-mini (-16.2) held up better but still lost ground. The researchers also tried "chain-of-thought" prompts, asking models to lay out their reasoning step by step, but even this didn't help the models reliably reach the correct medical answer.
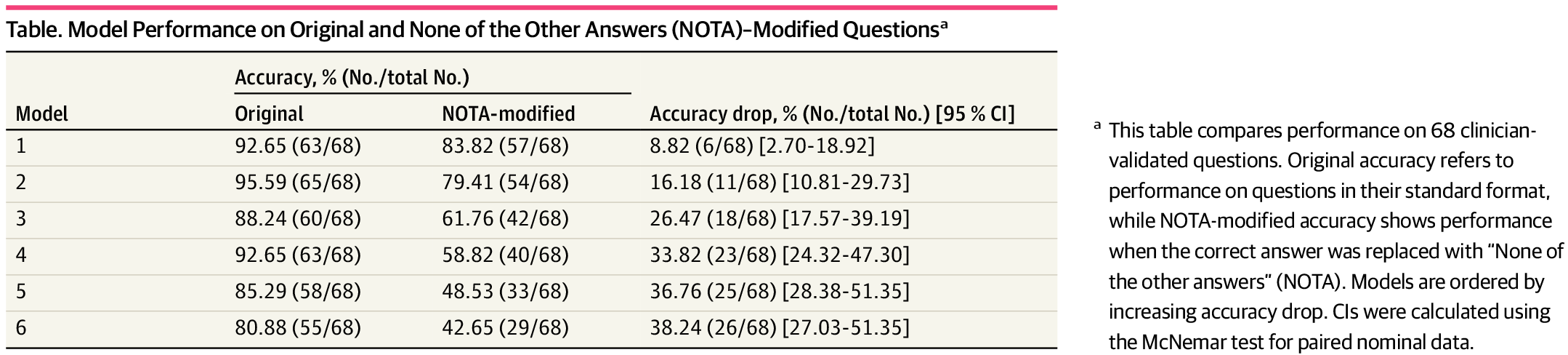
According to the authors, these results highlight a core problem: today's models mostly rely on statistical pattern matching, not genuine reasoning. Some dropped from 80 to 42 percent accuracy with only minor changes to the questions. That makes them risky for medical practice, where unusual or complex cases are common.
Doctors frequently encounter rare conditions or unexpected symptoms that don't fit textbook patterns. If LLMs are just matching familiar answers instead of reasoning through each case, they're likely to miss or misinterpret these outliers. The findings call into question whether current LLMs are robust or reliable enough for clinical use, since medicine demands systems that can handle ambiguity and adapt to new situations.
Language models are easily thrown off
It's well known that LLMs can give completely different answers if the prompt changes slightly or includes irrelevant info. Even reasoning-focused models aren't immune to this problem.
But it's still not clear if these systems truly lack logical reasoning skills or just can't apply them reliably. Right now, debates about LLM "reasoning" are bogged down by vague definitions and fuzzy benchmarks, which makes it tough to judge what these models can actually do.
The study also didn't include the very latest reasoning models like GPT-5-Thinking or Gemini 2.5 Pro, which might do better. Deepseek-R1 and o3-mini are current for their class but still may lag the most advanced systems. Still, their stronger performance here suggests there's a path toward more robust, reasoning-capable LLMs.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.