IBM's Granite 4.0 family of hybrid models uses much less memory during inference

Key Points
-
IBM has released Granite 4.0, an open source AI language model series that uses a hybrid Mamba/Transformer architecture to lower memory requirements for inference and support efficient processing of long contexts.
-
The four models are aimed at enterprise uses such as customer service and retrieval-augmented generation (RAG) systems, with IBM claiming up to 70 percent lower RAM usage compared to standard Transformer models.
-
Granite 4.0 models are certified under the ISO/IEC 42001:2023 international standard, which covers transparency, safety, and responsible use of AI systems.
IBM has released the fourth generation of its Granite language models. Granite 4.0 uses a hybrid Mamba/Transformer architecture aimed at lowering memory requirements during inference without cutting performance.
Granite 4.0 is designed for agentic workflows or as standalone models for enterprise tasks like customer service and RAG systems, with a focus on low latency and operating costs. Thinking variants are planned for fall.
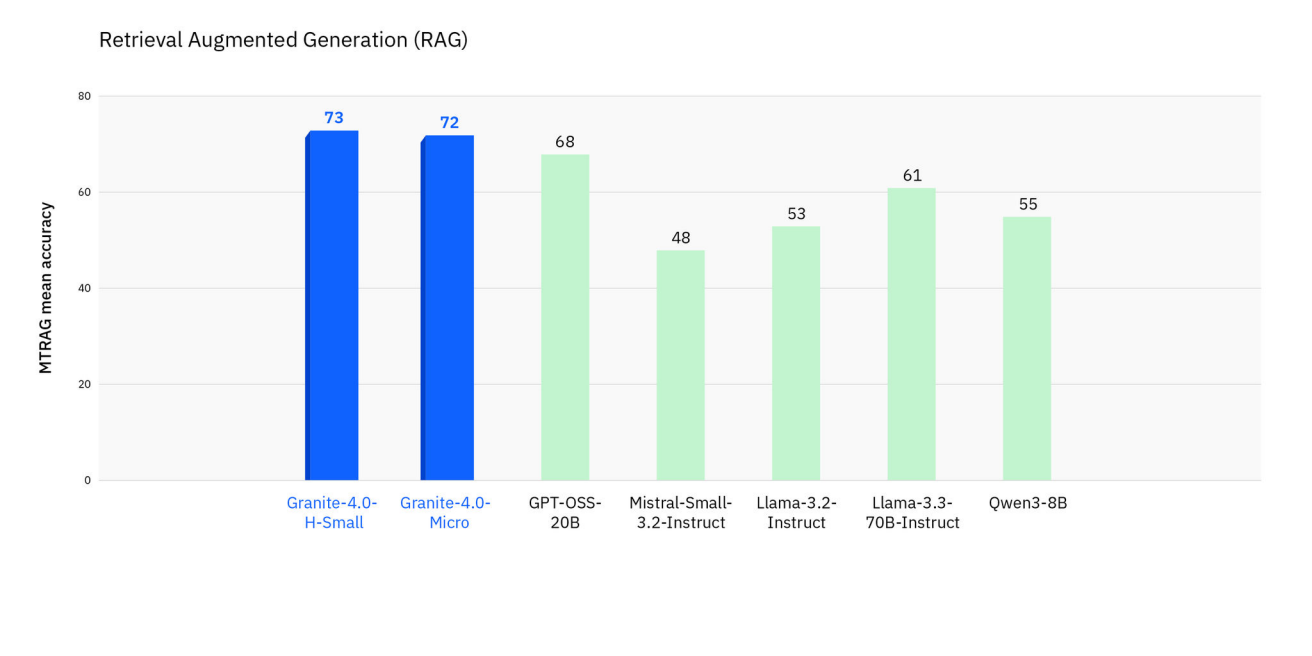
The models are open source under the Apache 2.0 license, cryptographically signed, and are the first open language models to earn ISO/IEC 42001:2023 accreditation. IBM says the training data is curated, ethically sourced, and cleared for business.
All Granite 4.0 models were trained on the same 22 trillion token dataset, which includes DataComp-LM (DCLM), GneissWeb, TxT360 subsets, Wikipedia, and other business-focused sources. For content generated by Granite on IBM watsonx.ai, IBM offers unlimited indemnification against third-party IP claims.
Granite 4.0 includes four model variants:
-
Granite-4.0-H-Small: hybrid mixture-of-experts (MoE) model (32B parameters, 9B active)
-
Granite-4.0-H-Tiny: hybrid MoE (7B parameters, 1B active)
-
Granite-4.0-H-Micro: dense hybrid model with 3B parameters
-
Granite-4.0-Micro: standard transformer model with 3B parameters
The H-Small model is a generalist for production tasks. Tiny and Micro are built for low-latency and edge scenarios, and can be used as fast modules in larger agent workflows, for example for function calling.
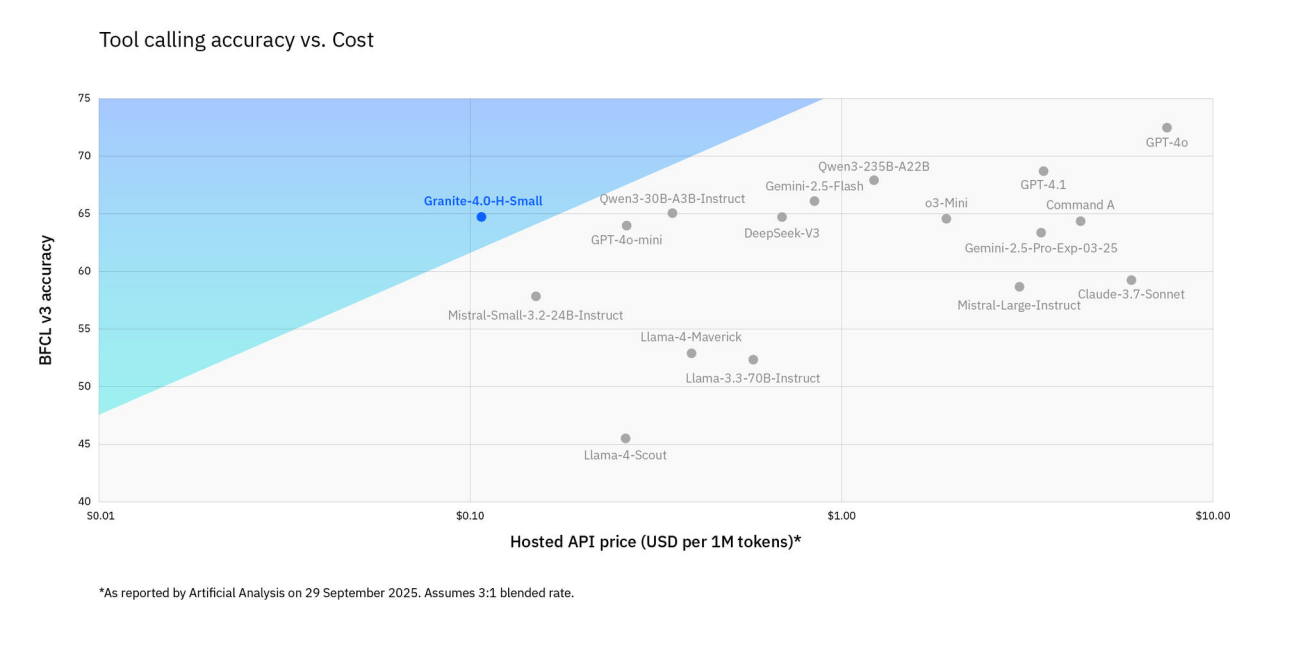
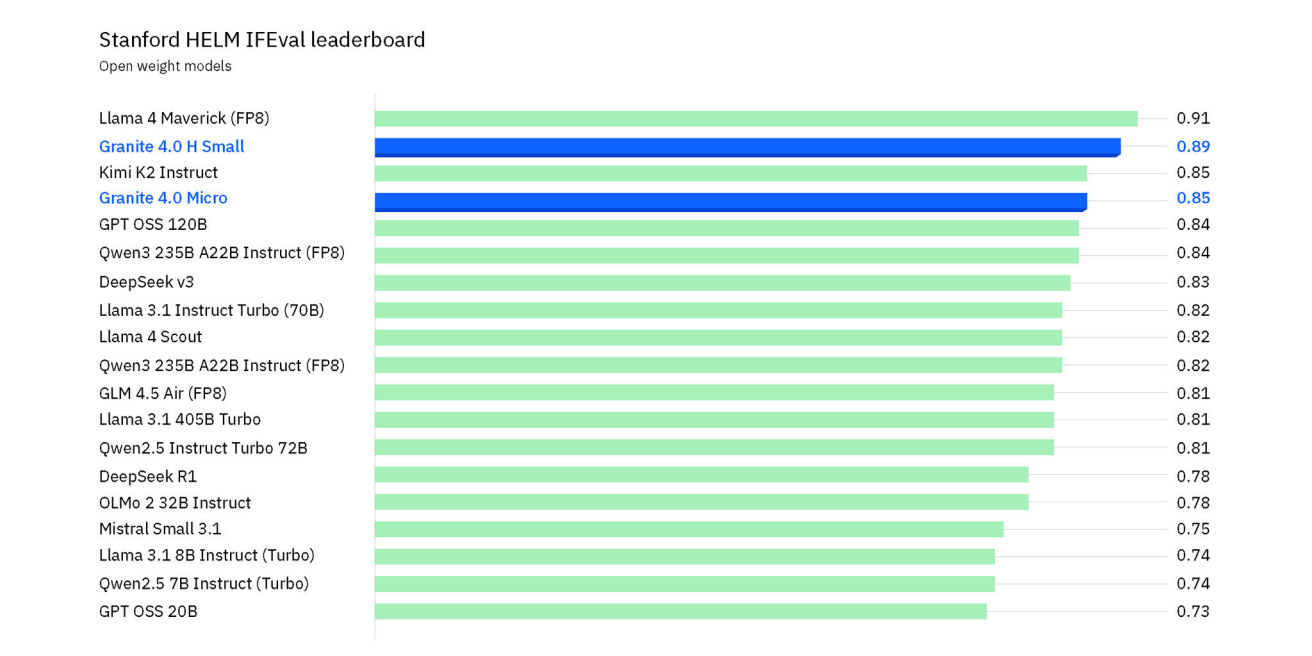
Architecture
Granite 4.0 uses a mix of Mamba 2 and Transformer layers in a 9:1 ratio. Transformers hit memory limits quickly with long contexts, but Mamba-2 scales linearly with sequence length and uses constant memory. Mamba processes input sequentially and keeps order, so no explicit position encoding is needed.
Transformers still have an advantage for in-context learning, like few-shot prompting. The hybrid design combines both approaches. H-Tiny and H-Small also use mixture-of-experts blocks with "shared experts" that are always active for better parameter efficiency.
For real workloads, IBM reports up to 70 percent less RAM usage compared to pure transformer models, especially with long inputs or multiple parallel sessions.
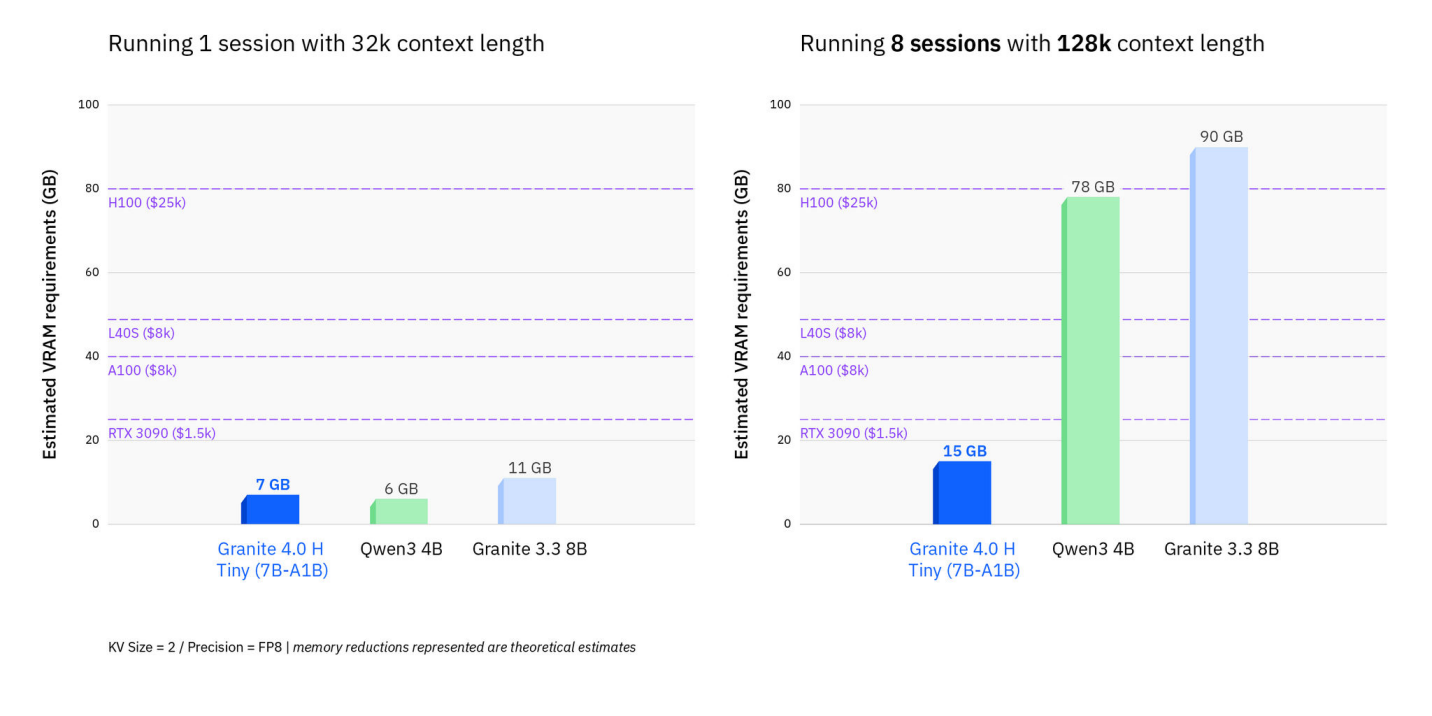
Granite 4.0 runs on AMD Instinct MI-300X, and optimizations for Hexagon NPUs (via Qualcomm and Nexa AI) make it suitable for smartphones and PCs.
Availability
Granite 4.0 Instruct is available through IBM watsonx.ai and on Dell Pro AI Studio, Dell Enterprise Hub, Docker Hub, Hugging Face, Kaggle, LM Studio, NVIDIA NIM, Ollama, OPAQUE, and Replicate. Base models are on Hugging Face. Support for Amazon SageMaker JumpStart and Microsoft Azure AI Foundry is coming soon.
IBM points users to the Granite Playground and technical documentation in the Granite Docs. Granite 4.0 models work with tools like Unsloth for fine-tuning and Continue for coding assistants.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now