Tencent trains AI that can explain and execute game strategies in Honor of Kings
Tencent researchers are testing new ways to teach AI models strategic thinking by training them on the game Honor of Kings. Their research shows that under certain conditions, smaller AI systems can outperform much larger ones.
The team points to a gap in current AI agents: most can play games but can't explain their decisions, while language models can discuss strategy but struggle to play. The "Think in Games" (TiG) framework is designed to bridge this gap.
Training on real match data
For their experiments, the researchers used Honor of Kings, a mobile MOBA developed by Tencent. The game requires complex, team-based strategy - two teams of five compete to destroy towers and control resources. The team defined 40 macro actions, such as "Push top lane," "Secure dragon," and "Defend base." The AI had to choose the best move in a given situation and explain its reasoning.

The models were trained on anonymized recordings of real matches, with an equal number of wins and losses. The data was standardized, and each move was labeled with a specific macro action.
Training took place in two phases. First, supervised learning introduced the AI to basic game mechanics. Next, reinforcement learning refined its strategy, using a reward system that gave one point for a correct move and zero for an incorrect one.
Smaller models outperform larger ones
The team tested several language models, including Qwen2.5 with 7, 14, and 32 billion parameters, and the newer Qwen3-14B. For comparison, they included Deepseek-R1, a much larger model.
Their method combined two steps: first, they distilled training data from Deepseek-R1, which already showed strong performance in games. Then, they applied Group Relative Policy Optimization (GRPO), which refines models by comparing multiple generated answers.
Results showed clear differences by model and training approach. Qwen3-14B reached 90.91 percent correct strategic decisions after 2,000 training steps using supervised learning plus GRPO, outperforming Deepseek-R1, which reached 86.67 percent.
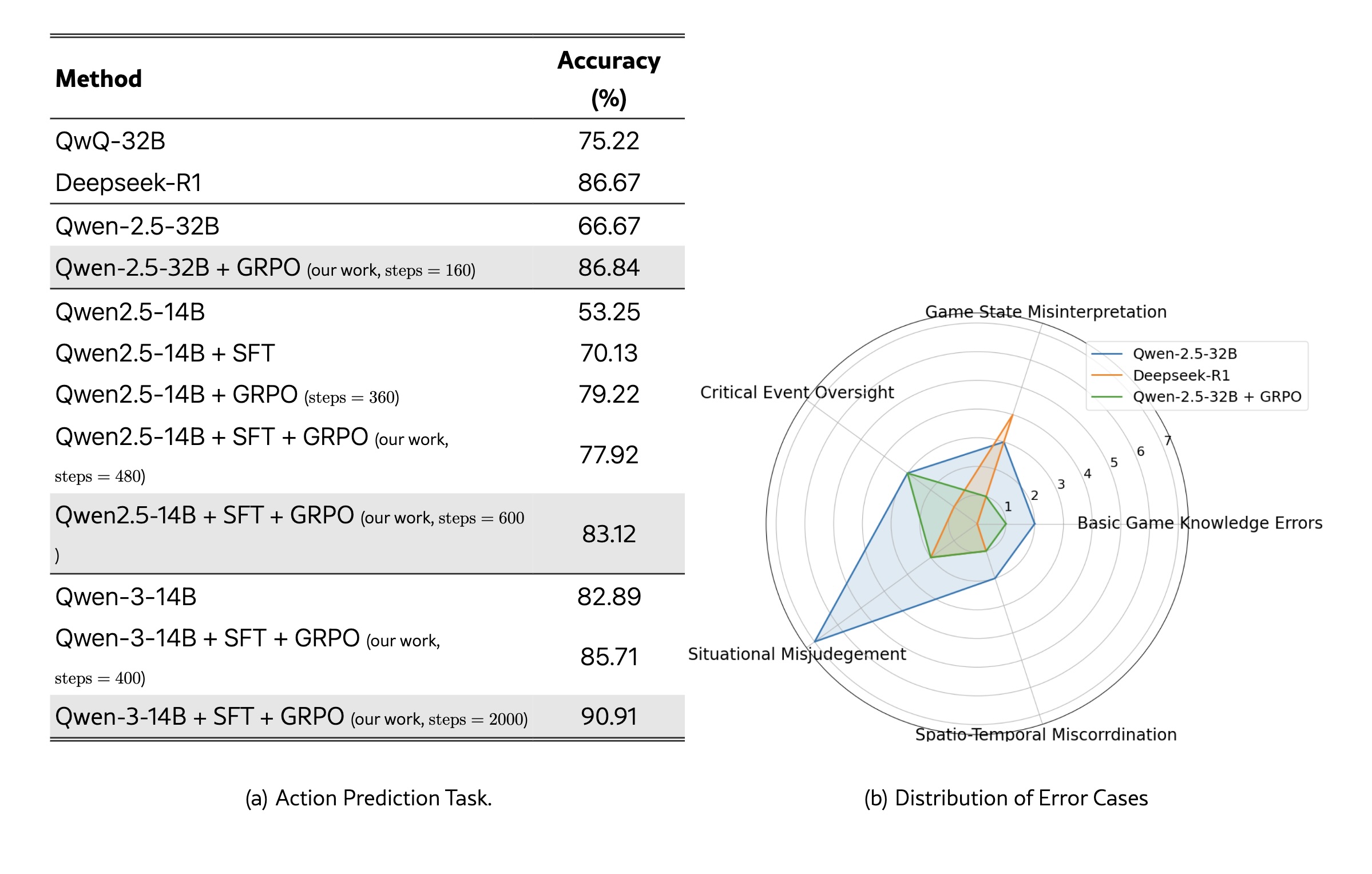
GRPO significantly improved model accuracy. Qwen-2.5-32B increased from 66.67 to 86.84 percent, and Qwen-2.5-14B improved from 53.25 to 83.12 percent after both phases. GRPO works by normalizing rewards across groups of answers and calculating relative advantages, which helps stabilize learning.
The trained systems can also explain their decisions. In one example, the AI identified a weak tower as the right target and warned about possible ambushes from opposing players. Models trained on Honor of Kings retained their abilities to read text, solve math problems, and answer general questions.
The research team sees potential applications for this framework outside of games, in areas that require both strategic reasoning and clear explanations. However, they note that results depend on the quality of the underlying language models, and it's not clear if the approach will transfer to other domains.
Other research projects are moving in a similar direction. In August 2025, Google introduced Game Arena, an open platform where advanced models compete in games instead of traditional benchmarks. Earlier, ROCKET-1 showed that a hierarchical agent in Minecraft could solve simple tasks with up to 100 percent success. Both projects point to a broader trend: using real gameplay as training data and a benchmark for AI systems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.