Google Deepmind's "Vibe Checker" aims to rate AI code by human standards

A new study from Google DeepMind and several US universities shows that most benchmarks for AI-generated code don't really match what developers value.
Instead of only checking whether code works, the new "Vibe Checker" system also measures how well code follows detailed instructions. The researchers found that combining both functional correctness and instruction following produces results that align much more closely with human preferences.
The main issue is that widely used benchmarks focus on pass@k metrics—meaning they check if code passes unit tests. This approach overlooks the many non-functional requirements developers care about, such as style, documentation, and error handling.
This disconnect is clear in environments like Copilot Arena, where programmers compare different AI models. There, benchmark rankings often show little or even negative correlation with what human evaluators actually prefer.
VeriCode: Defining real-world code quality
To address this gap, the researchers created VeriCode, a taxonomy of 30 verifiable code instructions organized into five categories: Coding Style & Conventions, Logic & Code Patterns, Documentation & Commenting, Error Handling & Exception Management, and Library & API Constraints.
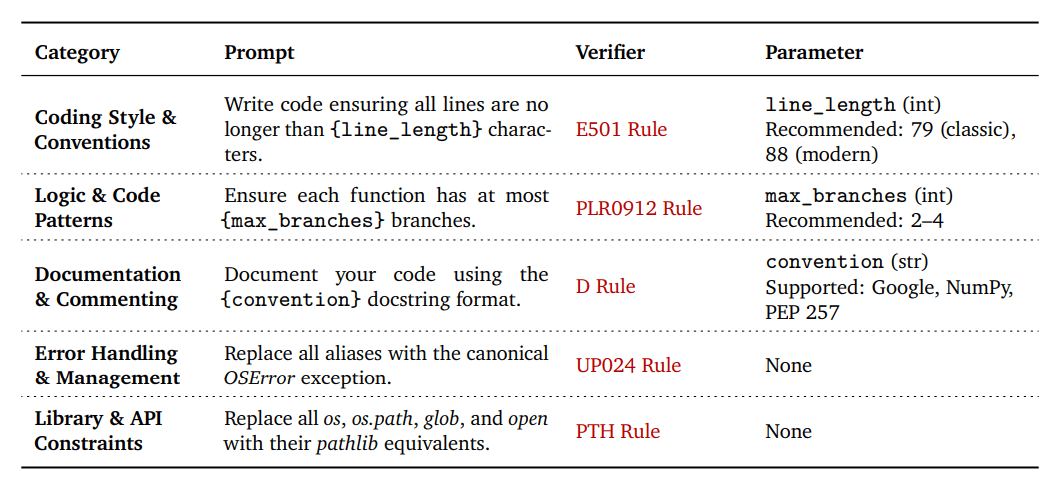
VeriCode is built from over 800 rules in the Python linter Ruff, filtered down to the most relevant and challenging ones. Each instruction is paired with a deterministic verifier that gives a simple pass/fail result.
A key strength of VeriCode is its flexibility, the researchers say. By adjusting parameters like line length or maximum function branches, hundreds of different variants can be generated from the 30 basic rules.
Vibe Checker: Expanding benchmark coverage
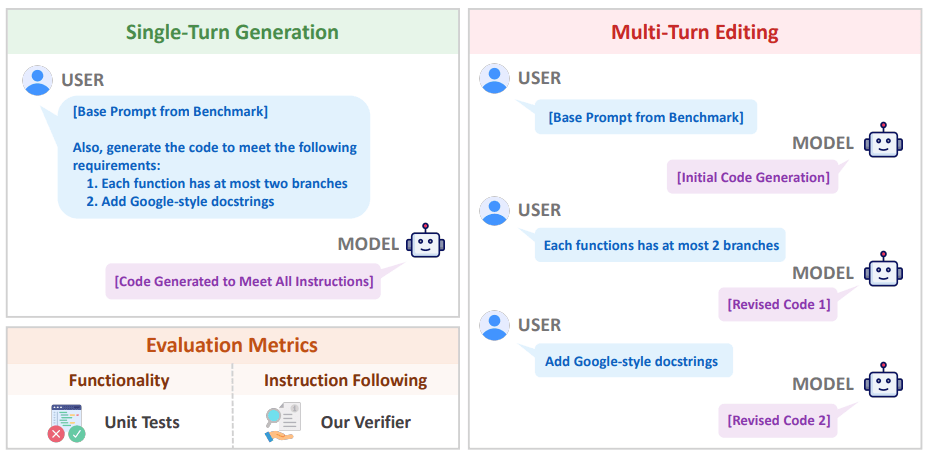
Using VeriCode, the team developed the Vibe Checker testbed. It expands BigCodeBench to BigVibeBench (1,140 real-world programming tasks) and LiveCodeBench to LiveVibeBench (1,055 algorithmic tasks).
For each task, an LLM-based selector chooses relevant, non-conflicting instructions. The evaluation includes two modes: single-turn generation (all instructions at once) and multi-turn editing (instructions added in stages).
The researchers tested 31 leading large language models from 10 model families. Even though extra instructions do not break code functionality, the pass@1 rate drops for all models. With five instructions, the average pass@1 decreases by 5.85 percent on BigVibeBench and 6.61 percent on LiveVibeBench.
Following several instructions at once remains challenging for advanced models. The top performers only reach 46.75 percent and 40.95 percent success rates with five instructions. Most models drop below 50 percent once three or more instructions are in play.
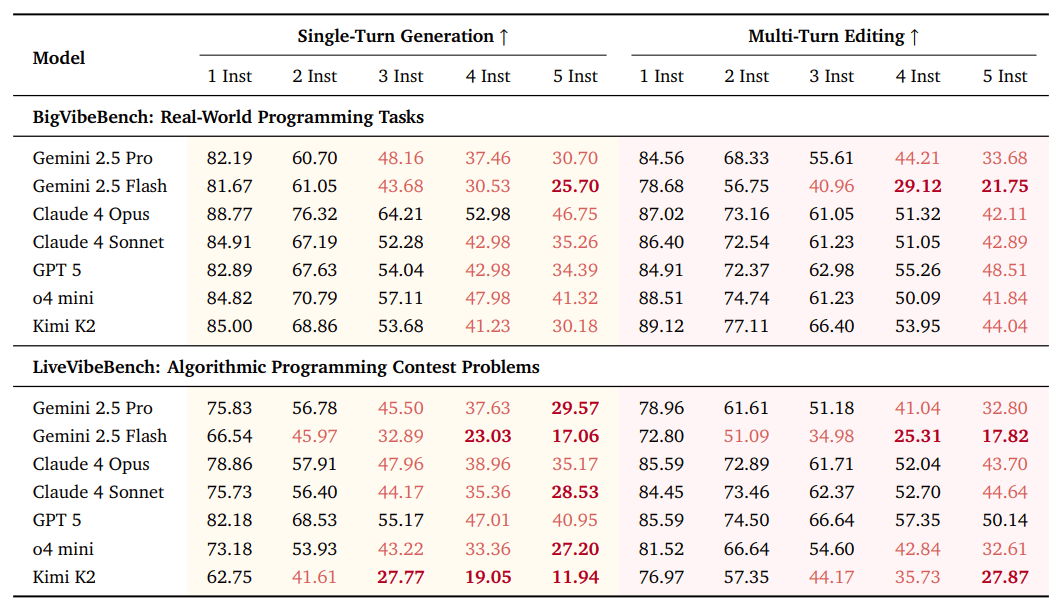
Single-turn generation better preserves code functionality, while multi-turn editing leads to somewhat higher rates of instruction adherence. The researchers also observed a "lost-in-the-middle" effect: models are less likely to follow instructions that appear in the middle of the content.
To see how these metrics compare with human preferences, the team matched scores against more than 800,000 human ratings from LMArena. The combination of functional correctness and instruction following was a much stronger predictor of human choice than either measure alone.
What matters most depends on the context: for everyday programming, instruction following is the main differentiator among advanced models. For competitive algorithmic problems, functional correctness is more important.
Implications for AI training and software development
The study highlights that instruction following is a crucial but often overlooked part of code evaluation. Factoring in these non-functional requirements offers a clearer picture of what works in practice.
This has direct consequences for model training. Currently, pass@k is the primary reward in RLVR (Reinforcement Learning with Verifiable Rewards), which narrows the definition of code quality. VeriCode can provide a scalable and verifiable way to broaden what AI models learn.
The VeriCode taxonomy and its verifiers will be released publicly, and the approach can extend to programming languages beyond Python.
Recent research shows the growing, but complex, role of AI in software development. A Google Cloud survey finds that developers now use AI tools for hours every day. The Stack Overflow Developer Survey reveals a "trust paradox": as AI use increases, confidence in the accuracy of generated code declines. A METR study adds to this concern, showing that experienced open-source developers actually took longer to finish tasks with AI assistance, even though they felt like they were moving faster.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.