Verbalized Sampling is a simple prompt technique meant to make AI responses less boring

Language models often repeat themselves and fall back on stereotypical answers after training. Verbalized Sampling is a simple prompt technique designed to make AI responses less repetitive.
Researchers from several US universities traced this issue to how people evaluate AI output. Their analysis found that human raters consistently prefer familiar, typical responses when judging AI answers. This preference gets encoded in the models, leading to less variety over time.
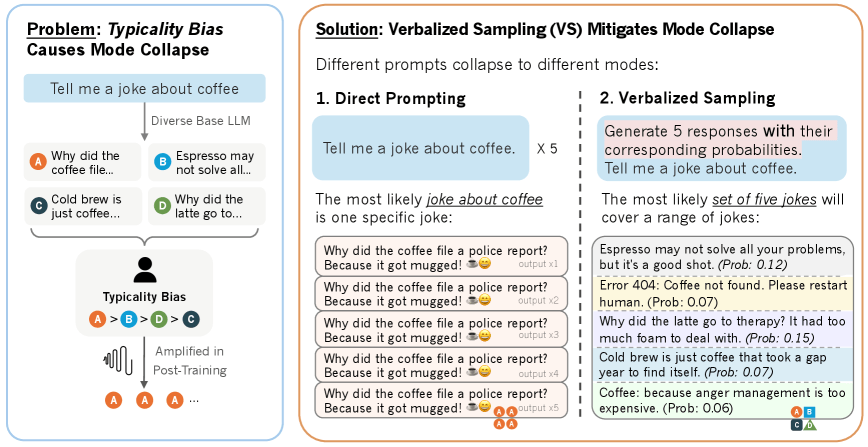
To test this idea, the researchers used the HELPSTEER dataset, which includes 6,874 response pairs. Human raters almost always picked the answers the base models ranked as most likely, regardless of whether those answers were actually correct. This effect held up across multiple datasets.
Instead of asking a model for just one answer, Verbalized Sampling prompts it for several responses, each with a probability attached. The prompt looks like this:
<instruction>
Generate 5 responses to the user query, each within a separate <response> tag. Each <response> must include a <text> and a numeric <probability>.
Randomly sample the responses from the full distribution.
</instruction>
Write a 100-word story about a bear.
The team built three versions of the method. The standard version asks for multiple answers with probabilities. An expanded version adds step-by-step reasoning before generating responses. The third runs through several rounds of dialogue. None of the approaches require extra training or access to the model's internal probability scores.
More variety and more realistic model behavior
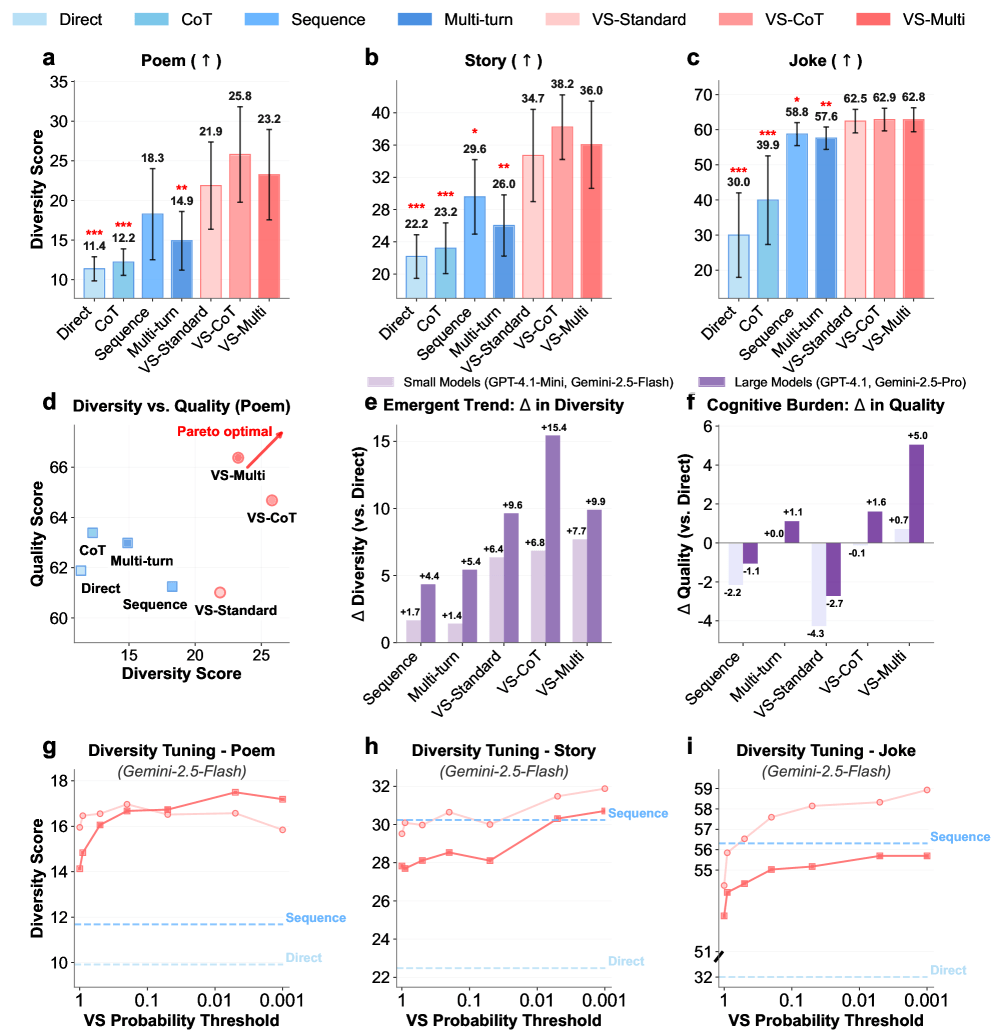
In creative writing tasks, Verbalized Sampling increased response diversity by 1.6 to 2.1 times. For example, standard prompting for car jokes always returned the same punchline ("Why did the car get a flat tire? Because it ran over a fork in the road!"), while Verbalized Sampling produced five completely different jokes (such as "What kind of car does a Jedi drive? A Toy-Yoda!").
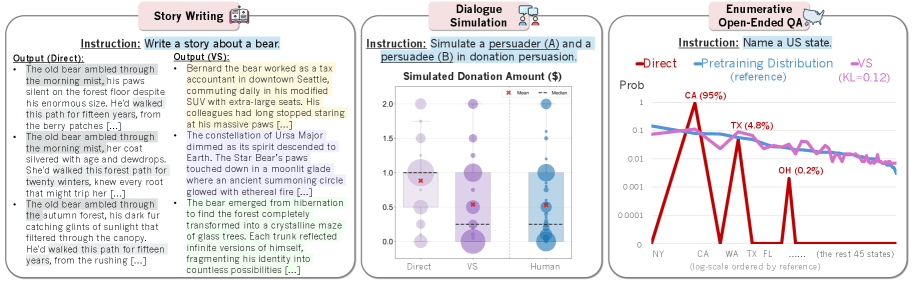
In dialogue simulations, models acted more like people - they sometimes resisted persuasion attempts and changed their opinions in more realistic ways. When simulating donation behavior, the results were much closer to actual human behavior.
For open-ended questions like "Name a US state," the spread of answers closely mirrored the original training data. Standard prompts, on the other hand, mostly returned common states like California and Texas.
Models trained with a wider range of synthetic math tasks also saw accuracy rise from 32.8 to 37.5 percent. Larger models got even more out of the method, with improvements 1.5 to 2 times higher than smaller versions.
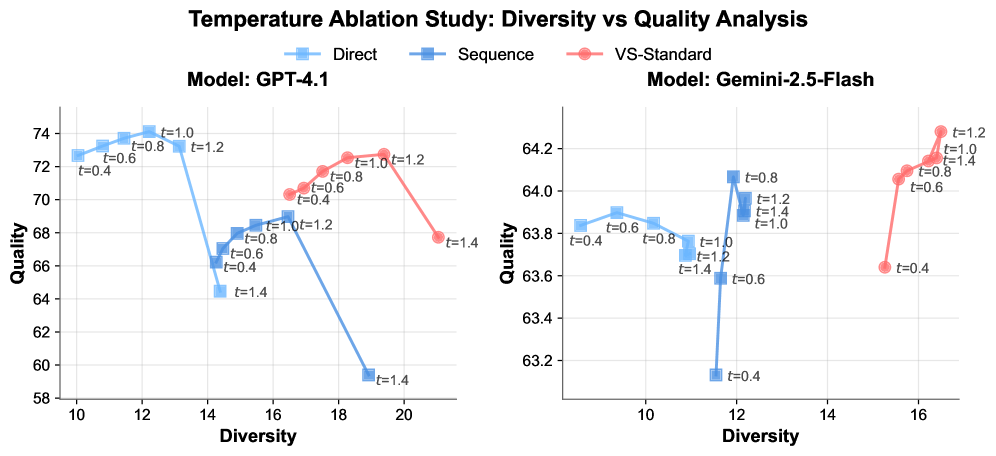
The researchers tested Verbalized Sampling with different generation parameters, such as temperature. The benefits remained consistent across all settings, and combining Verbalized Sampling with parameter adjustments led to further improvements. At every tested temperature, the technique achieved a better balance between quality and diversity than standard prompting.
More creative image descriptions
The method also works for image generation. The team used Verbalized Sampling to create image descriptions, then ran those through image generators. For the prompt "Astronaut on a Horse," standard prompts always gave similar photorealistic desert scenes. Verbalized Sampling led to much more diverse descriptions.

The researchers also checked safety, running over 350 potentially risky prompts. The rejection rate stayed above 97 percent, and fact accuracy was not affected.
The team has published code and instructions for Verbalized Sampling and points to use cases in creative writing, social simulation, and idea generation.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.