DeepEyesV2 outperforms bigger rivals by favoring tools over sheer knowledge

Chinese researchers have built a multimodal AI model that can analyze images, run code, and search the web. Instead of relying on knowledge acquired during training, DeepEyesV2 boosts performance by using external tools intelligently, allowing it to outperform larger models in many cases.
During early experiments, Xiaohongshu's research team ran into a core issue. Reinforcement learning alone wasn't enough to produce stable tool use in multimodal tasks. The models initially tried to write Python code for image analysis but often generated faulty snippets. As training continued, they began skipping tools entirely.
Why multimodal models need a new training approach
These challenges led the team to develop a two-stage training pipeline. A cold-start phase teaches the model how to connect image understanding with tool use, followed by reinforcement learning to refine those behaviors.

To build high-quality demonstrations, the team used leading models such as Gemini 2.5 Pro, GPT-4o, and Claude Sonnet 4 to generate tool-use trajectories. They kept only those with correct answers and clean code. The reinforcement learning reward system stayed intentionally simple, with rewards tied to answer accuracy and output format.
DeepEyesV2 uses three tool categories for multimodal tasks. Code execution handles image processing and numerical analysis. Image search retrieves visually similar content. Text search adds context that isn't visible in the image.
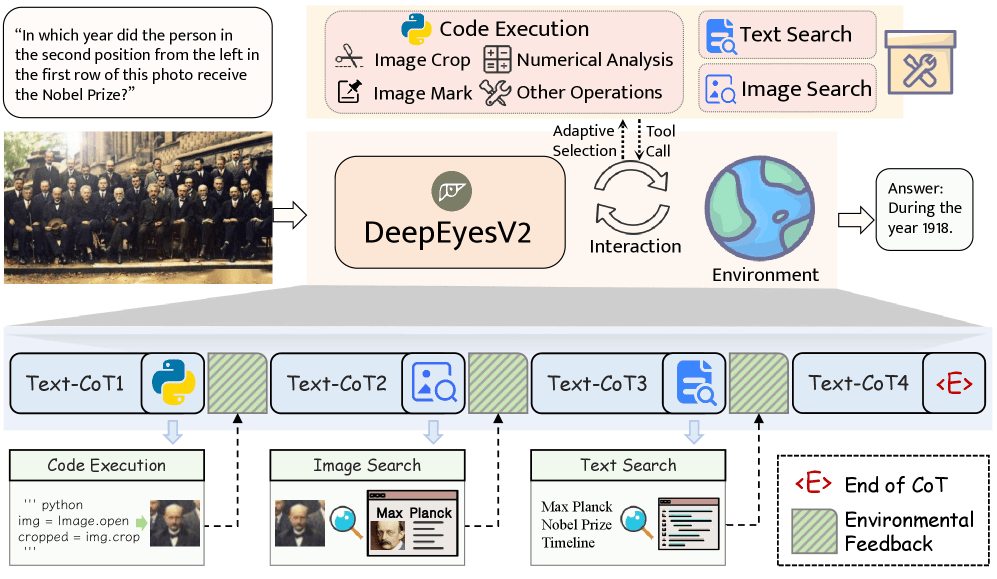
A new benchmark puts image-tool coordination to the test
To evaluate this approach, the researchers created RealX-Bench, a benchmark designed to test how well models coordinate visual understanding, web search, and reasoning. One example from the study shows how involved these tasks can be. When asked to identify the type of flower in a picture, the model first crops the relevant region to capture details. It then launches a visual web search using the cropped image to find similar flowers, and finally blends those results to determine the species.

The results reveal a wide gap between AI models and human performance. Even the strongest proprietary model reached only 46 percent accuracy, while humans scored 70 percent.
Tasks that require all three skills are especially challenging. According to the study, Gemini's accuracy dropped from 46 percent overall to just 27.8 percent when recognition, reasoning, and search all had to work together. The drop underscores how current models can handle individual skills but struggle to integrate them.

DeepEyesV2 reached 28.3 percent overall accuracy. That puts it ahead of its base model Qwen2.5-VL-7B at 22.3 percent, though still behind the 32-billion and 72-billion-parameter versions. But DeepEyesV2 outperformed other open-source models on tasks that require coordination across all three capabilities.
The analysis also found that search tools play a major role in boosting accuracy, with text search providing the biggest gains. This suggests that many models still struggle to meaningfully incorporate information from visual search alone.
How tool use helps smaller models compete
DeepEyesV2 shows its largest gains in specialized benchmarks. In mathematical reasoning tasks, it scored 52.7 percent on MathVerse, a 7.1-point improvement over its base model.
The model also performs well on search-driven tasks. It reached 63.7 percent on MMSearch, outperforming the dedicated MMSearch-R1 model at 53.8 percent. And in everyday image understanding tasks, the 7-billion-parameter DeepEyesV2 even surpassed Qwen2.5-VL-32B, despite having more than four times fewer parameters.
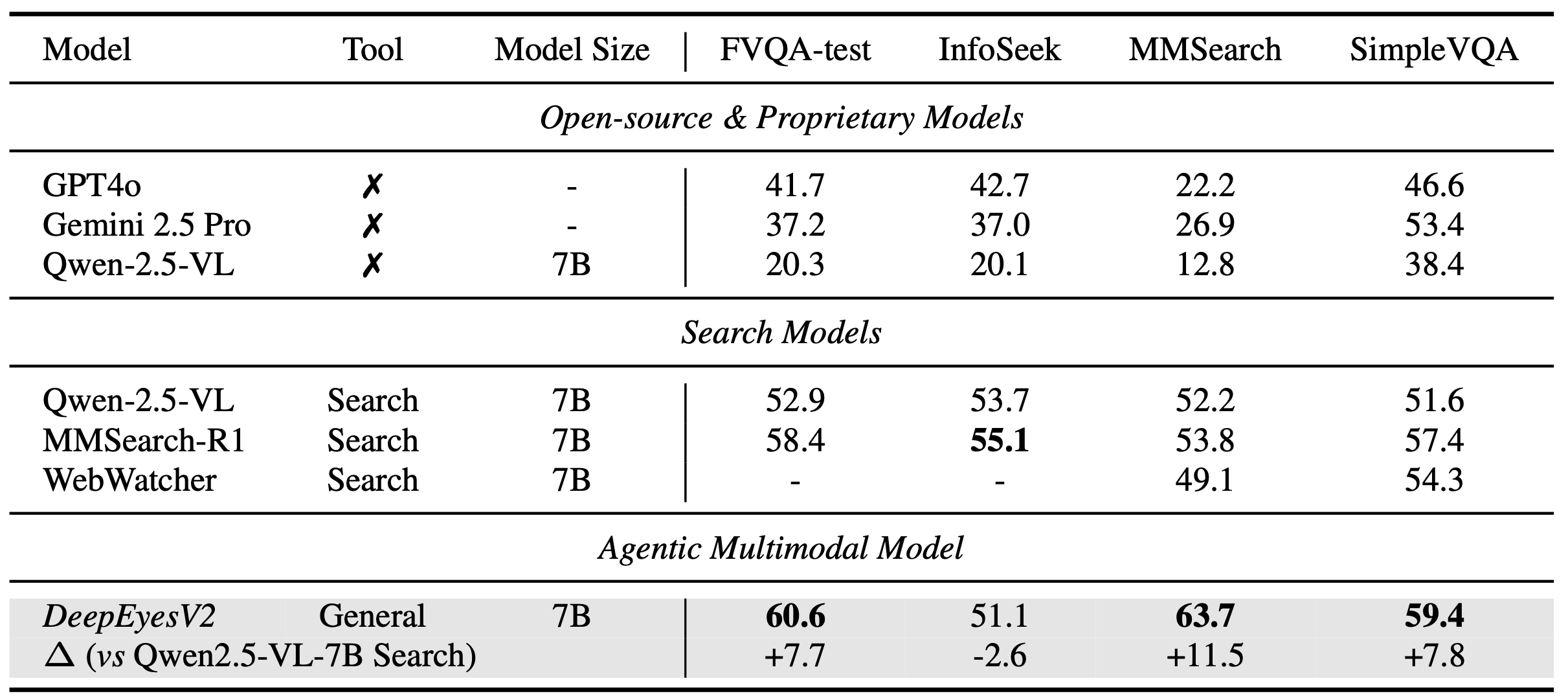
These results suggest that well-structured tool use can offset the limitations of smaller models. Instead of relying on extra parameters, DeepEyesV2 improves performance by pulling in external resources more effectively.
How DeepEyesV2 adapts its strategy to different tasks
The team's analysis shows clear patterns in how the model chooses tools. For visual perception tasks, it often crops the image to isolate the relevant region. For diagram-based math problems, it blends image analysis with numerical computation. For visually grounded knowledge questions, it launches targeted web searches based on the image.
After reinforcement learning, the model became noticeably more adaptive. It used tools less often overall, suggesting it had learned to call them only when needed. But the high variance in tool use across tasks shows that it continues to tailor its strategy to each problem type.
Xiaohongshu has been increasing its footprint in the global AI landscape. Its first open-source language model, dots.llm1, delivered competitive results and outperformed models from Alibaba and Deepseek in efficiency. Its character recognition model, dots.ocr, showed similar capabilities.
The earlier DeepEyes release in May already combined reasoning with multimodal understanding. DeepEyesV2 builds on that foundation, aiming to bring these capabilities together in more agent-like environments. Xiaohongshu, also known locally as Rednote, runs a major Chinese social media and e-commerce platform similar to TikTok.
DeepEyesV2 is available on Hugging Face and GitHub under the Apache License 2.0 and can be used commercially.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.