Multi-agent training aims to improve coordination on complex tasks

Key Points
- Researchers have created a framework where specialized AI agents collaborate as a team with defined roles to solve complex tasks more quickly.
- The new M-GRPO training method allows agents to be trained independently while synchronizing their learning experiences, which helps balance workloads and team sizes.
- In testing, this system showed better stability, efficiency, and task-solving ability compared to individual agents and previous methods.
Researchers have introduced a framework that trains multiple AI agents at the same time, with each agent taking on a specialized role. The aim is to handle complex, multi-step tasks more reliably through clearer division of labor and tighter coordination.
According to researchers at Imperial College London and Ant Group, most current AI systems rely on a single agent that has to plan and act. That setup works for simple tasks, but it breaks down once the process involves long chains of decisions. Errors stack up, and a single agent usually can't excel at both high-level planning and hands-on tool use. Different stages require different mindsets, and single-agent systems often struggle with long, coordinated reasoning in dynamic environments.
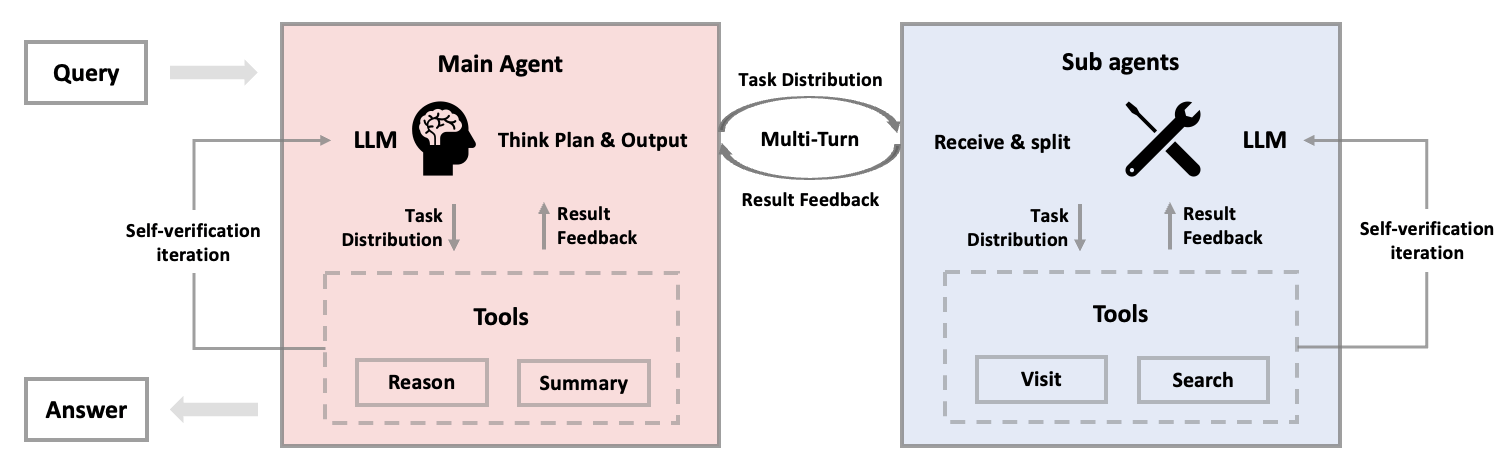
Their proposed solution is a structured hierarchy. One agent acts as a project manager who oversees the workflow, while specialized sub-agents handle specific tools like web search or data analysis. The research team found that multi-agent systems with a clear leader can solve tasks almost ten percent faster than systems without defined roles.
Vertical hierarchies work especially well, with a main agent delegating tasks and sub-agents reporting back. Anthropic is testing a similar setup in its recently introduced research agent.
How M-GRPO enables more coordinated training
Most single-agent systems today use Group Relative Policy Optimization, or GRPO. The agent generates several answers to a prompt, compares them, and reinforces the stronger patterns.
Multi-agent systems complicate this process. Agents operate at different frequencies, handle different tasks, and may run on separate servers. Standard training approaches struggle in these conditions. Many systems force all agents to share the same large language model, limiting specialization even though each agent works with different data and responsibilities.
The researchers identify three main challenges. First, the workload is uneven: the main agent works continuously, while sub-agents only run when needed. That creates unstable training data. Second, team sizes vary. Depending on the task, the main agent might call one sub-agent or several, which complicates training. Third, agents often run on separate servers, making typical training methods hard to apply.
The new Multi-Agent Group Relative Policy Optimization, or M-GRPO, extends GRPO so main and sub-agents can be trained together while keeping their roles distinct.
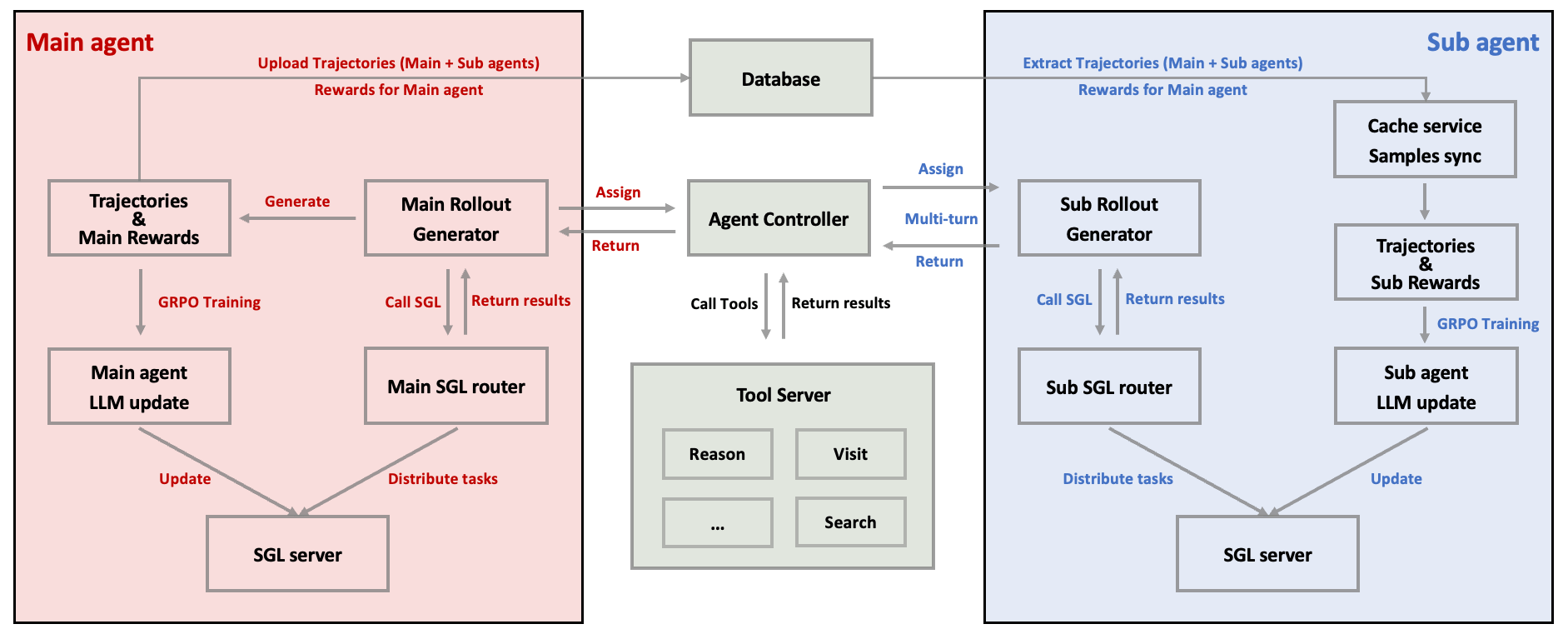
Each agent is evaluated based on its specific role. The main agent is judged by the quality of the final answer, and sub-agents are evaluated using a mix of their local task performance and their contribution to the overall result. M-GRPO calculates group-relative advantages by comparing each agent's output to the average in its group and adjusting training based on the difference.
A trajectory alignment scheme handles the uneven number of sub-agent calls. The system sets a target for how often sub-agents should act and duplicates or drops training data to keep batch sizes consistent. Main and sub-agents can run on different servers and exchange only lightweight statistics through a shared database, keeping cross-server computation minimal.
Why better instructions lead to better results
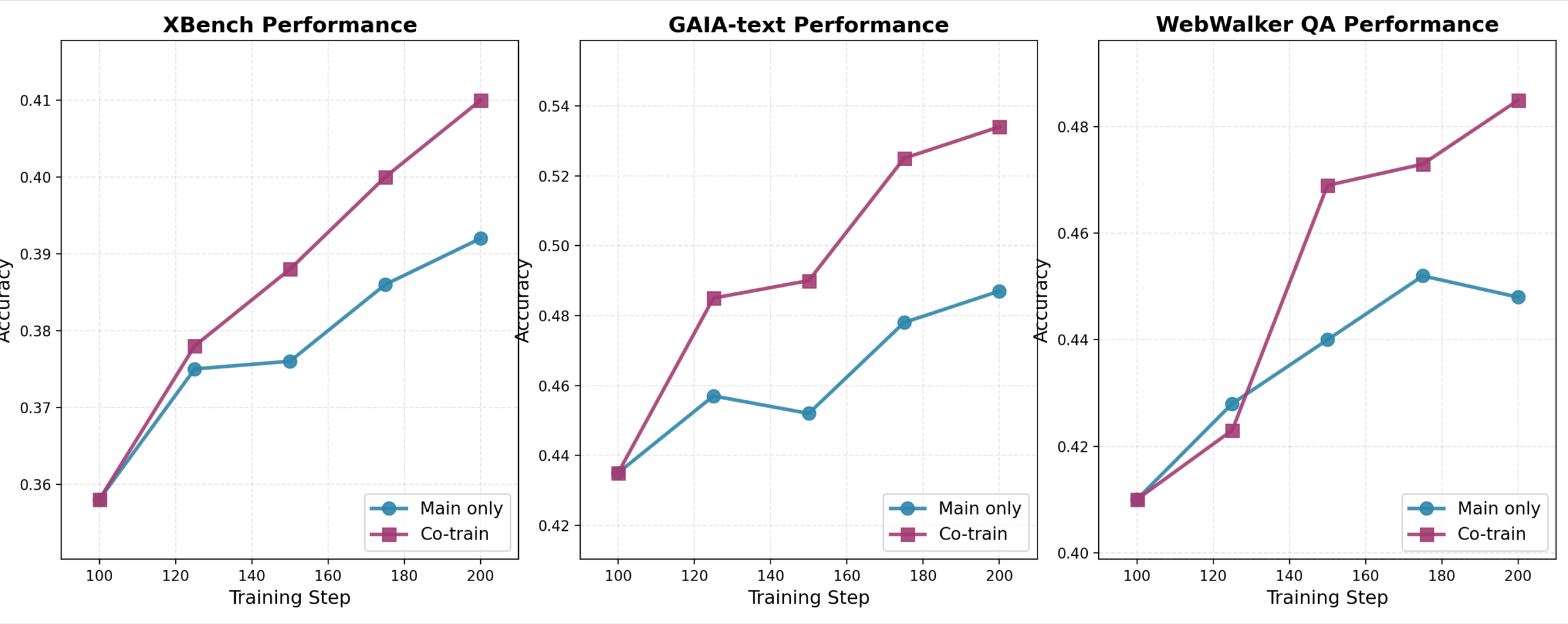
The researchers trained their M-GRPO system using the Qwen3-30B model on 64 H800 GPUs and tested it on three benchmarks: GAIA for general assistant tasks, XBench-DeepSearch for tool use across domains, and WebWalkerQA for web navigation.
Across all benchmarks, M-GRPO outperformed both single GRPO agents and multi-agent setups with untrained sub-agents. It produced more stable behavior and needed less training data to reach strong performance.
Real-world examples show how it helps. In a Rubik's Cube logic task, the trained system chose the correct reasoning tool for mathematical steps, while the untrained system tried to use a browser. In a research task on invasive fish species, the trained main agent issued much more precise instructions. Instead of generally searching for "invasive species Ocellaris Clownfish," it specified "species that 'became invasive after being released by pet owners'."
Code and datasets are available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now