DeepseekMath-V2 is Deepseek's latest attempt to pop the US AI bubble

Chinese startup Deepseek reports its new DeepseekMath-V2 model has reached gold medal status at the Math Olympiad, keeping the company in tight competition with Western AI labs.
According to Deepseek, its new DeepseekMath-V2 model achieved gold medal-level results at the International Mathematical Olympiad (IMO) 2025 and the Chinese CMO 2024. In the Putnam competition, the AI scored 118 out of 120 points, beating the best human result of 90 points.
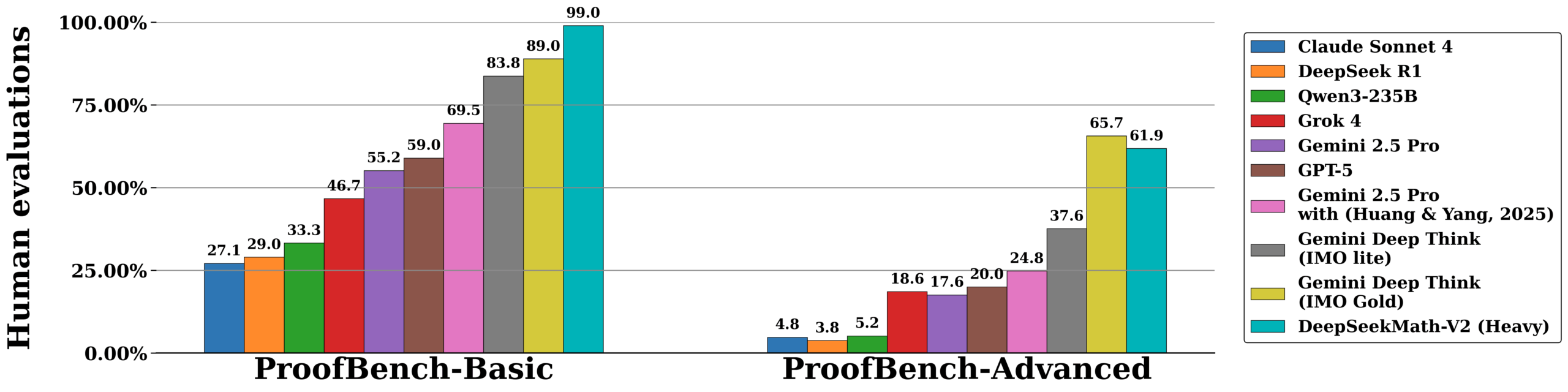
In its technical documentation, Deepseek explains that previous AIs often produced correct final answers without showing the right work. To fix this, the new model uses a multi-stage process. A "verifier" evaluates the proof, while a "meta-verifier" double-checks if any criticism is actually justified. This setup lets the system check and refine its own solutions in real time.
The paper never mentions using external tools such as calculators or code interpreters, and its setup suggests the benchmarks are produced by natural language alone.
In the headline experiments, a single DeepSeekMath‑V2 model is used for both generating proofs and verifying them, with performance coming from the model’s ability to critique and refine its own solutions rather than from external math software.
For harder problems, the system scales up test‑time compute, sampling and checking many candidate proofs in parallel, to reach high confidence in a final solution. Technically, the model is based on Deepseek-V3.2-Exp-Base.

Closing the gap with US labs
The release comes on the heels of similar news from OpenAI and Google Deepmind, whose unreleased models also achieved gold-medal status at the IMO, accomplishments once thought to be unreachable for LLMs. Notably, these models reportedly succeeded through general reasoning abilities rather than targeted optimizations for math competitions.
If these advances prove genuine, it suggests language models are approaching a point where they can solve complex, abstract problems, traditionally considered a uniquely human skill. Still, little is known about the specifics of these models. An OpenAI researcher recently mentioned that an even stronger version of their math model will be released in the coming months.
Deepseek's decision to publish technical details stands in stark contrast to the secrecy of OpenAI and Google. While the American giants kept their architecture under wraps, Deepseek is laying its cards on the table, demonstrating that it is keeping pace with the industry's leading labs.
This transparency also doubles as a renewed attack on the Western AI economy, a play Deepseek already executed successfully earlier this year. The strategy seems to be working: As the Economist reports, many US AI startups are now bypassing major US providers in favor of Chinese open-source models to cut costs.
Yet this rivalry has another dimension. As these models become more capable, their development becomes an increasingly charged political topic, a shift that could further strengthen US labs. By aggressively pushing the frontier, Deepseek might ultimately be helping OpenAI and its peers justify the speed and scale of their own advances.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.