Even the best AI models fail at visual tasks toddlers handle easily
A new study exposes a fundamental weakness in today's AI systems: even the most capable multimodal language models can't handle basic visual tasks that toddlers master before they learn to speak.
Multimodal AI models score above 90 percent on expert knowledge tests like MMMU. But a new study reveals a striking gap: these same systems fall apart on basic visual tasks that humans learn before they can talk. The best model tested, Gemini-3-Pro-Preview, managed just 49.7 percent. Human adults hit 94.1 percent.

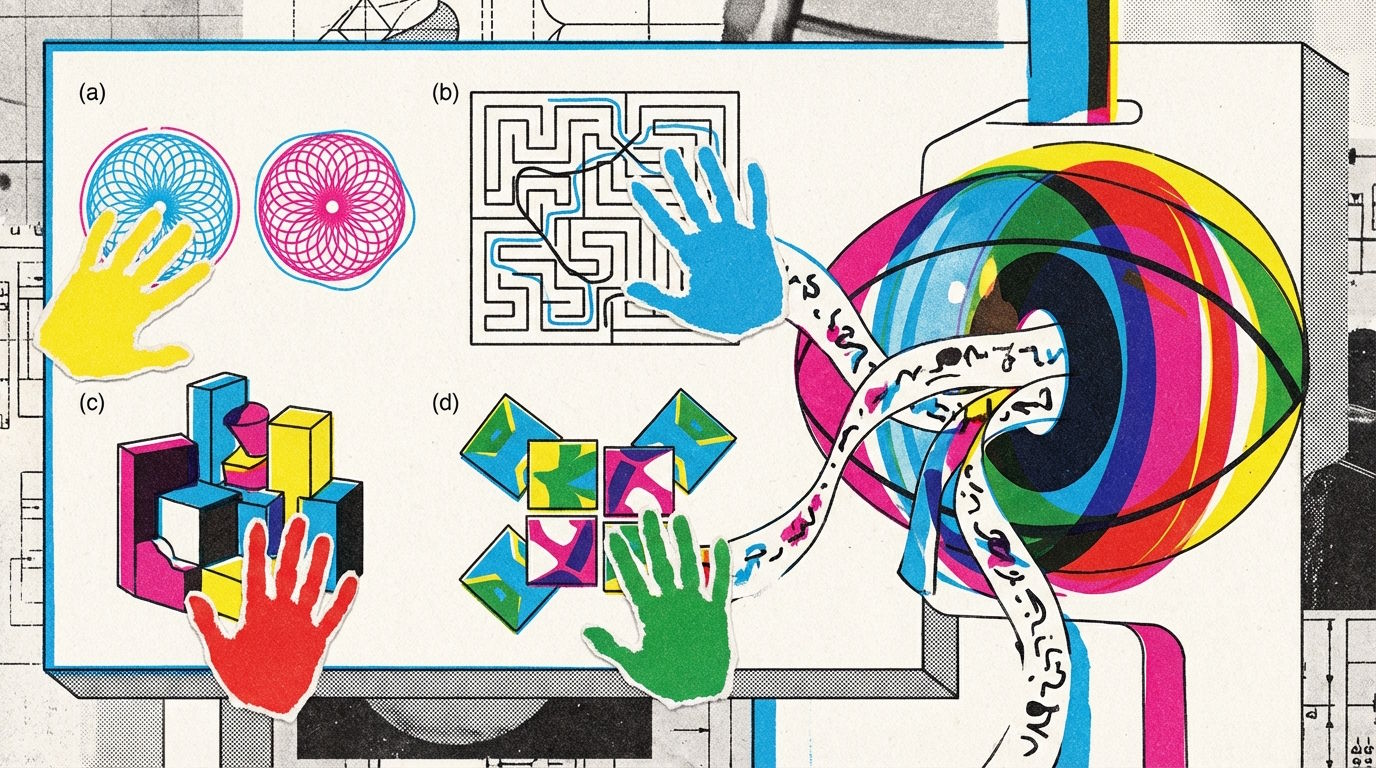
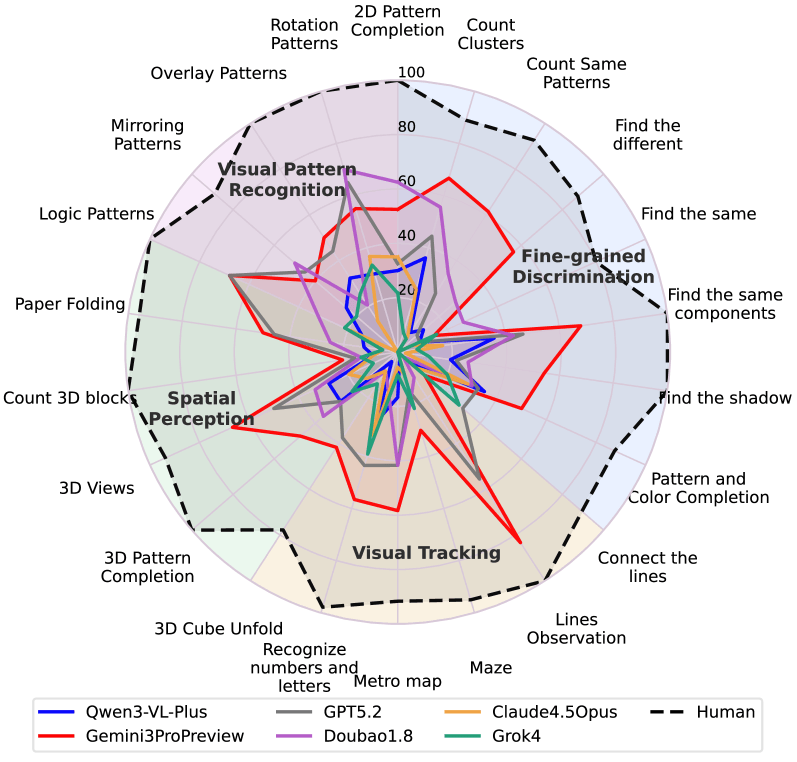
Researchers from Chinese institutions including UniPat AI, Xbench, Peking University, Alibaba Group, and MoonShot AI built the "BabyVision" benchmark with 388 tasks across four categories. These test skills that developmental psychology research shows humans develop in their first months of life: fine-grained visual discrimination (like spotting subtle differences between similar patterns), following lines through mazes or across intersections, spatial perception (counting hidden 3D blocks, for example), and visual pattern recognition involving rotations and reflections.
Most frontier models score below the average three-year-old
A comparison test with 80 children across different age groups showed just how wide the gap really is. Most frontier models tested scored below the average for three-year-olds. Only Gemini3-Pro-Preview consistently beat this group, but it still trailed typical six-year-olds by about 20 percentage points.
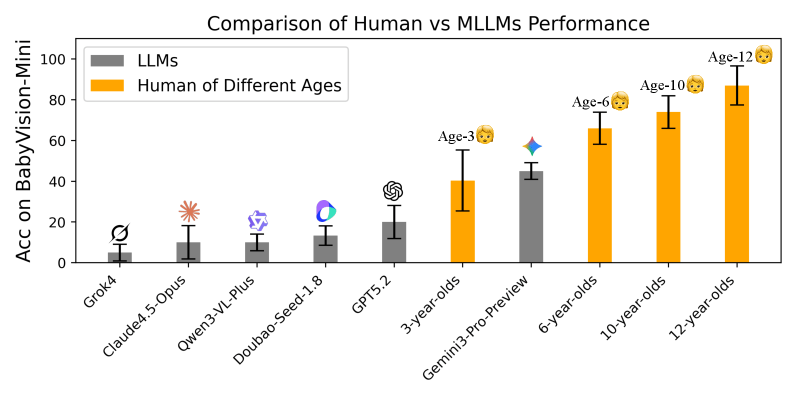
Among proprietary models, Gemini 3 Pro leads by a wide margin. GPT-5.2 follows with 34.4 percent, Bytedance's Doubao-1.8 hits 30.2 percent, and Claude 4.5 Opus manages just 14.2 percent. Open source models fared even worse. The best performer, Qwen3VL-235B-Thinking, scored only 22.2 percent.
The results get especially stark for specific task types. On counting 3D blocks, even the best model reaches just 20.5 percent while humans score 100 percent. On the "Lines Observation" task, where lines must be traced through intersections, only Gemini hits 83.3 percent. Most other models scored zero.
Language-first processing creates a visual blind spot
The researchers trace all these failures to a single problem they call the "verbalization bottleneck." Current multimodal models translate visual input into language representations before reasoning about it. Any visual information that can't be expressed in words gets lost along the way.
Semantic content like "a red car on a road" translates easily into language. Geometric relationships resist this conversion because the exact curvature of a boundary or the precise position of an intersection can't be captured in words without losing information. The researchers say BabyVision specifically targets these non-descriptive visual properties.
Mazes remain a major challenge
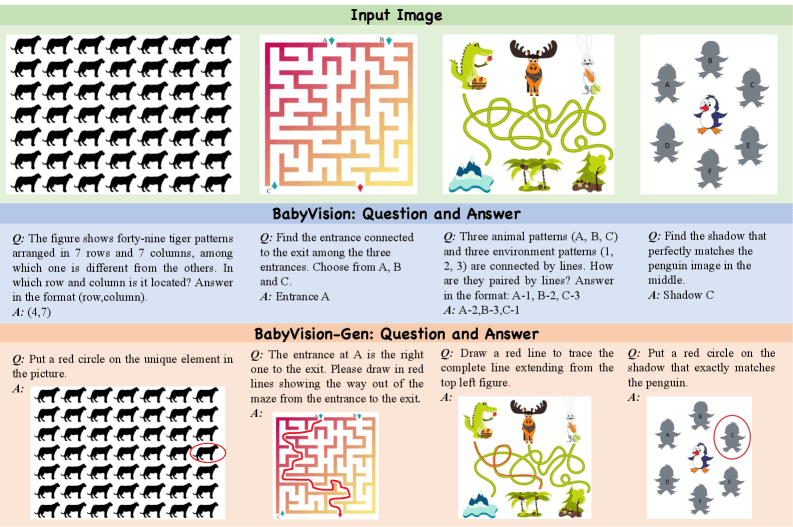
The researchers also developed "BabyVision-Gen," an extension with 280 questions. Here, models had to show their solutions by generating images, drawing paths, or highlighting differences. People often solve these tasks by drawing instead of verbalizing, and children externalize visual reasoning through drawing before they can verbalize solutions.
The tested image generators showed some promise. Nano Banana Pro hit 18.3 percent, and GPT-Image-1.5 reached 9.8 percent. On tasks like finding differences, Nano Banana Pro scored 35.4 percent. But every generator failed completely on maze tasks and connecting lines. These tasks require continuous spatial coherence over longer sequences, something current architectures can't maintain.
The researchers point to "unified multimodal models" that natively integrate visual processing and generation as a potential solution. These architectures could maintain visual representations throughout the reasoning process instead of compressing everything into a linguistic bottleneck. The BabyVision benchmark, available on GitHub, is meant to serve as a diagnostic tool for measuring progress toward true visual intelligence.
Francois Chollet's ARC-AGI-3 benchmark tests similar basic cognitive abilities like object permanence and causality. It uses interactive mini-games where AI agents have to figure out the rules on their own. So far, current systems score zero points on these tasks while humans solve them in minutes.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.