Google Deepmind's D4RT model aims to give robots and AR devices more human-like spatial awareness

Key Points
- Researchers at Google DeepMind have developed D4RT, an AI model capable of reconstructing dynamic scenes from videos in four dimensions, combining spatial and temporal data.
- The system integrates depth estimation, spatio-temporal correspondence, and camera parameters into a single architecture, achieving speeds 18 to 300 times faster than previous methods.
- In practical applications, the technology could enhance spatial awareness for robots in the near term, while potentially contributing to more sophisticated world models for AI systems in the future.
Google Deepmind's new AI model D4RT reconstructs dynamic scenes from video in four dimensions, running up to 300 times faster than previous methods.
Humans perceive the world in three dimensions and naturally understand how objects move through space and time. For AI systems, this ability has been a major computational bottleneck, according to Google Deepmind.
The new D4RT (Dynamic 4D Reconstruction and Tracking) model tackles this problem with a novel architecture that combines depth estimation, spatiotemporal correspondence, and camera parameters into a single system.
A simpler approach replaces complex multi-model pipelines
Previous approaches to 4D reconstruction typically relied on multiple specialized models handling separate tasks like depth estimation, motion segmentation, and camera pose estimation. These fragmented systems required complex optimization steps to achieve geometric consistency.
According to the research paper, D4RT takes a different approach based on the Scene Representation Transformer: a powerful encoder processes the entire video sequence at once and compresses it into a global scene representation. A lightweight decoder then queries this representation only for the points actually needed.
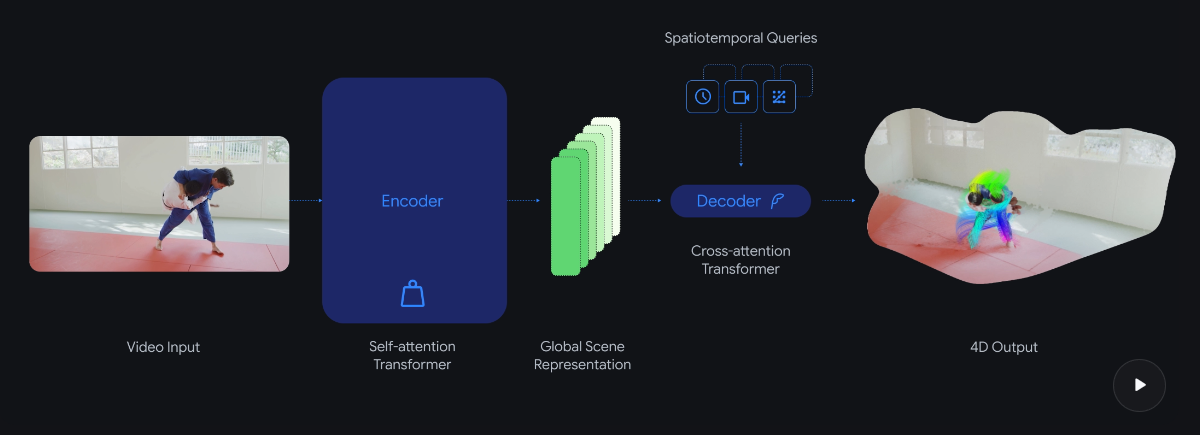
The whole system boils down to one question: Where is a given pixel from the video located in 3D space at any given time, viewed from a selected camera? Since each query runs independently, the whole process can be parallelized on modern AI hardware.
Unlike competing models that need separate decoders for different tasks, D4RT uses a single decoder for point tracks, point clouds, depth maps, and camera parameters. The model can also predict where objects are even when they're not visible in other frames. It handles both static environments and dynamic scenes with moving objects.
Speed jumps from 18 to 300 times faster
The efficiency gains are substantial. D4RT runs 18 to 300 times faster than comparable methods, according to the researchers. The model chews through a one-minute video in about five seconds on a single TPU chip—previous methods took up to ten minutes for the same task.
In benchmarks shared by Google Deepmind, D4RT beats existing methods in depth estimation, point cloud reconstruction, camera pose estimation, and 3D point tracking. For camera pose estimation alone, D4RT hits over 200 frames per second, nine times faster than VGGT and a hundred times faster than MegaSaM, while also delivering better accuracy.
The long game: building toward AGI
For now, the technology could give robots better spatial awareness and help augmented reality applications embed virtual objects more realistically in their surroundings, according to Google Deepmind. The model's efficiency makes on-device deployment a realistic possibility.
Down the road, the researchers see this approach as a step toward better world models, which they say is critical for achieving artificial general intelligence (AGI). The idea is that AI agents should learn from experience within these world models rather than simply applying trained knowledge, as current AI models mostly do.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now