Nvidia releases open model PersonaPlex, a voice AI that listens and talks at the same time
Key Points
- Nvidia has released PersonaPlex, a conversational AI model designed for natural real-time dialogue with customizable voices and user-defined personas.
- The system can listen and speak at the same time, switching between speakers in just 0.07 seconds—far faster than Gemini Live's 1.3 seconds—while picking up natural speech patterns like interruptions and verbal cues.
- PersonaPlex outperformed Gemini Live in tests, scoring 3.90 versus 3.72 for dialog naturalness and handling user interruptions with a 100 percent success rate. The code and model weights are freely available on Hugging Face and GitHub.
Nvidia has released PersonaPlex, a conversational AI model that enables natural real-time conversations with customizable voices and user-defined roles.
Traditional voice assistants run speech recognition, language models, and speech synthesis one after another. This allows voice and role customization but results in robotic conversations with unnatural pauses. Newer systems like Moshi from French AI lab Kyutai make conversations more natural but lock users into a single fixed voice and role.
According to Nvidia, PersonaPlex combines the best of both - users can pick from different voices and define any role through text prompts, whether that's a wise assistant, customer service agent, or fantasy character.
Full-duplex audio eliminates awkward pauses
PersonaPlex listens and speaks at the same time. Beyond speech content, the model learns conversational behaviors like when to pause, when to interrupt, and when to make confirming sounds like "uh-huh." It updates its internal state while the user is speaking and streams responses back right away.
In tests, PersonaPlex hit a latency of just 0.07 seconds when switching speakers, according to the technical paper, compared to 1.3 seconds for Google's Gemini Live. The model builds on Moshi and has 7 billion parameters with an audio sampling rate of 24 kHz.
Hybrid prompts let users control voice and role separately
The core innovation is a hybrid system prompt that combines two inputs: a voice prprompt—ahort audio sample that captures voice characteristics and speaking ststyle—and text prompt that describes the role, background, and conversation context. Both get processed together to create a coherent persona.
The researchers demonstrate the system through several scenarios. In a bank customer service example, the system verifies the customer's identity, explains a declined transaction, and shows empathy and accent control. In a doctor's office scenario, it records patient data like name, date of birth, and medication allergies.
In a space emergency scenario, PersonaPlex plays an astronaut during a reactor core meltdown on a Mars mission. The model maintains a coherent persona, displays appropriate tones of stress and urgency, and handles technical crisis management vocabulary, even though none of this appeared in the training data.
Real and synthetic data fill the training gap
A challenge was the lack of speech data covering a wide range of topics and natural behaviors like interruptions. The researchers solved this by mixing real and synthetic data.
The published model was trained on 7,303 real conversations from the Fisher English Corpus, totaling 1,217 hours, annotated with prompts at varying levels of detail. Moreovert, the team generated 39,322 synthetic assistant dialogs and 105,410 synthetic customer service conversations. Transcripts came from Alibaba's Qwen3-32B and OpenAI's GPT-OSS-120B, while Chatterbox TTS from Resemble AI handled speech generation.
The synthetic data taught task knowledge and instruction following, while the real recordings contributed natural speech patterns.
PersonaPlex outperforms commercial and open-source rivals in benchmarks
For evaluation, the researchers extended the existing full-duplex benchmark with a new service-duplex benchmark covering 350 customer service questions across 50 role scenarios. PersonaPlex achieved a Dialog Naturalness Mean Opinion Score of 3.90, compared to 3.72 for Gemini Live, 3.70 for Qwen 2.5 Omni, and 3.11 for Moshi.
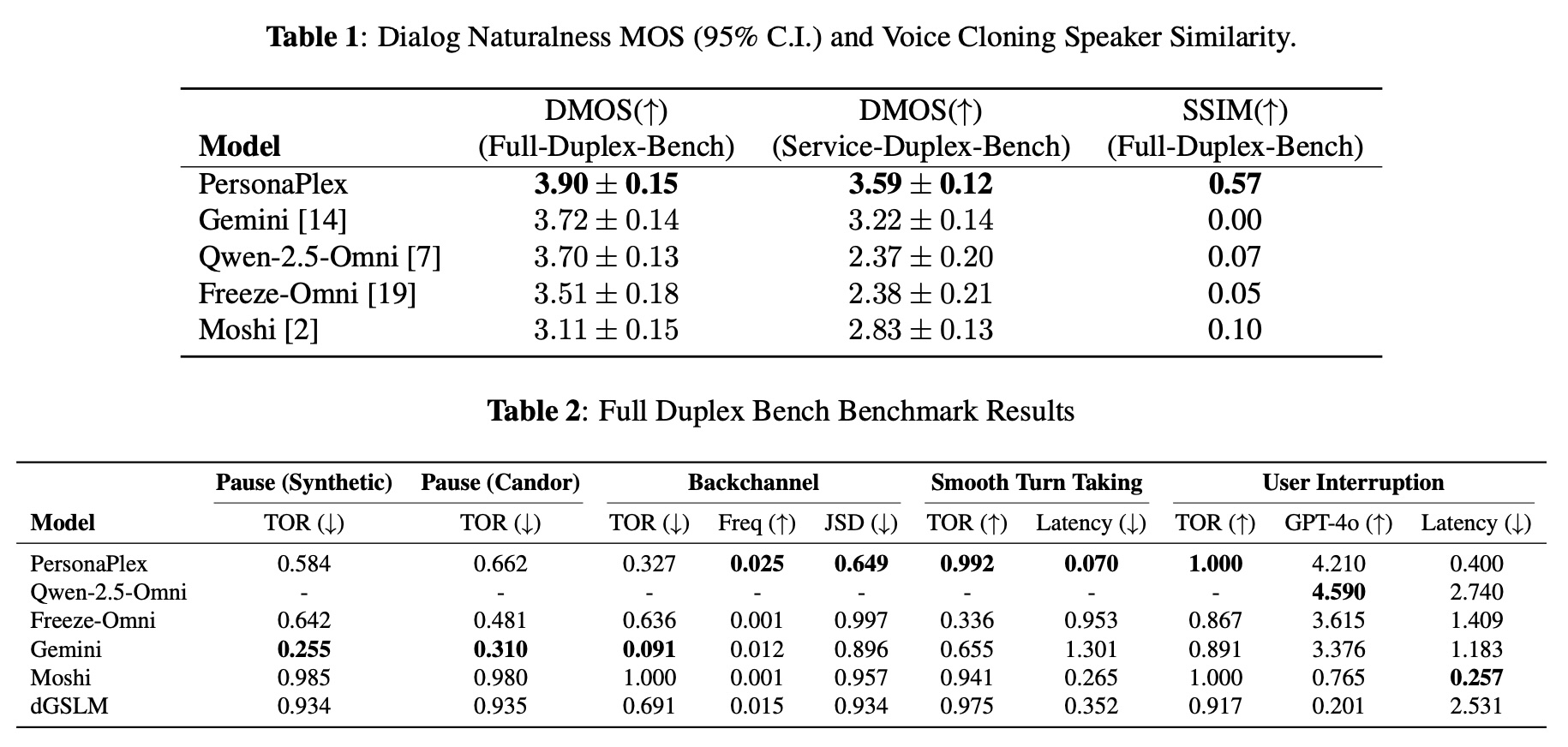
PersonaPlex achieved a speaker similarity score of 0.57 for voice cloning, while Gemini, Qwen, and Moshi were close to zero. The model also hit a 99.2 percent success rate for smooth speaker changes and handled user interruptions flawlessly. According to the researchers, PersonaPlex is the first open model they know of that matches the naturalness of closed commercial systems.
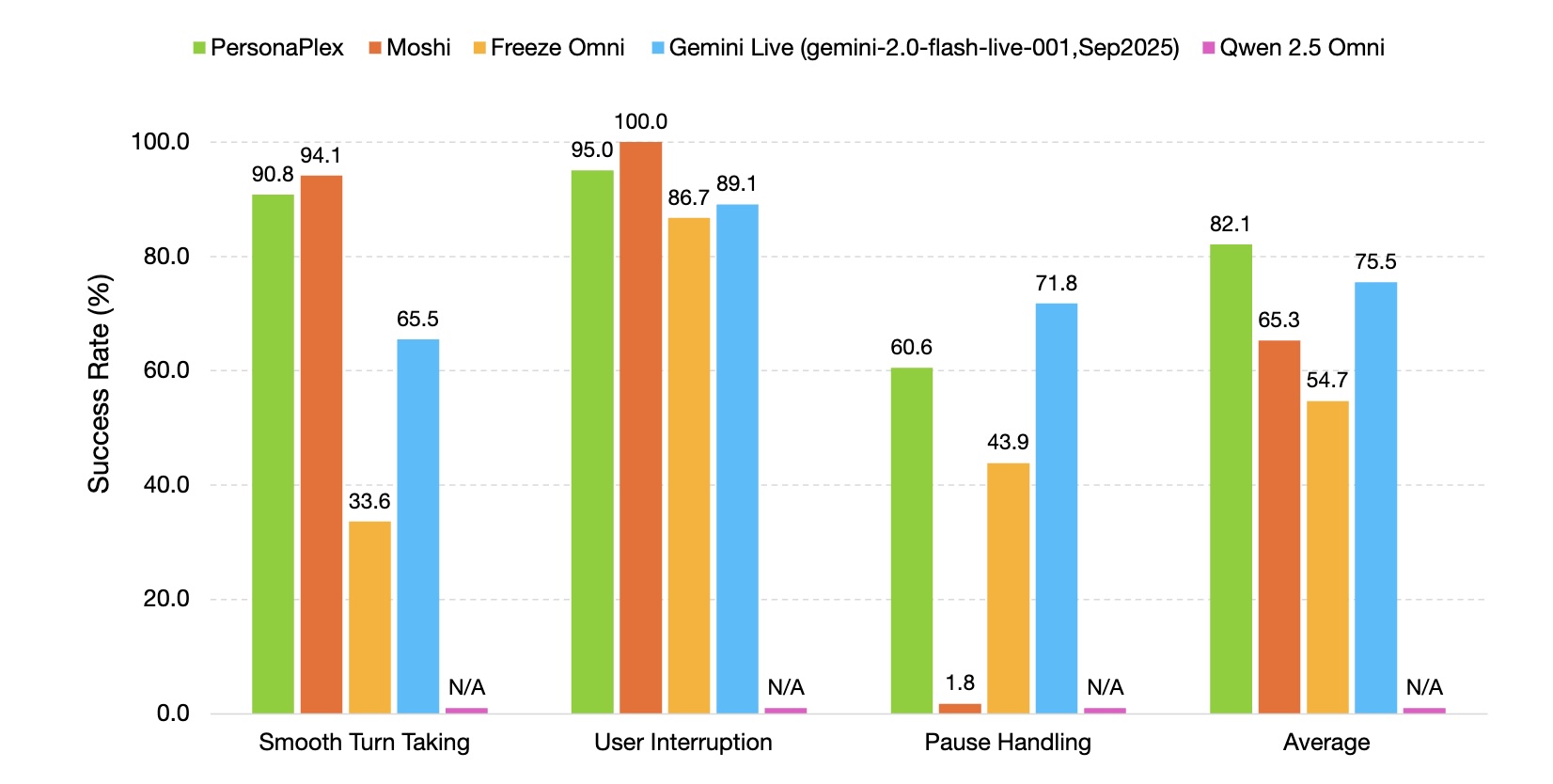
Training took six hours on eight A100 GPUs. Nvidia has released the code and model weights on Hugging Face and GitHub under MIT and Nvidia's Open Model License, allowing commercial use without claiming rights to outputs. For now, the model only supports English. Next up, the researchers plan to work on post-training alignment and tool integration.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now