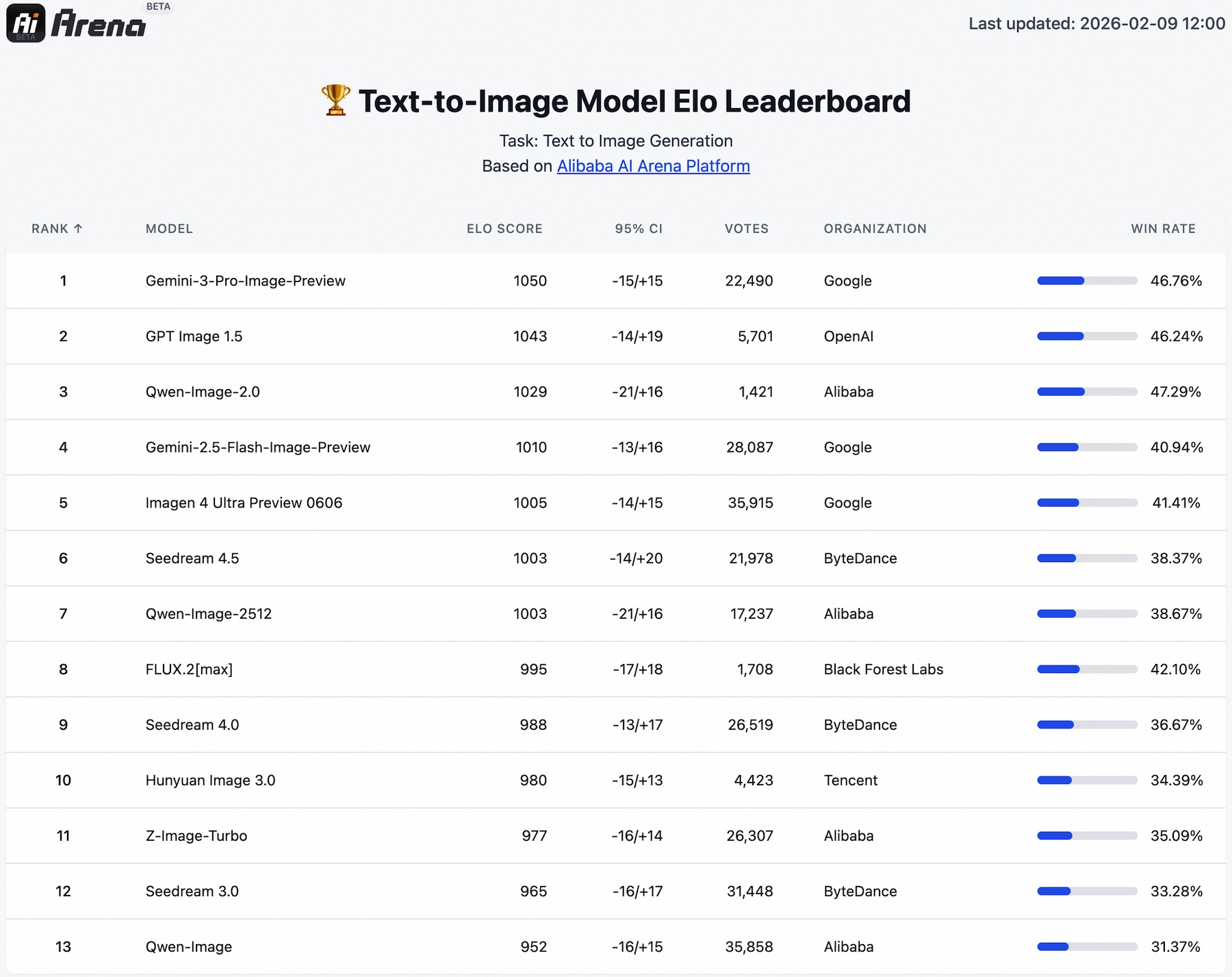
Qwen-Image-2.0 renders ancient Chinese calligraphy and PowerPoint slides with near-perfect text accuracy

Key Points
- Alibaba's Qwen team has released Qwen-Image-2.0, a 7-billion-parameter model that handles both image generation and image processing in one package, at a fraction of the size of comparable models.
- One of the model's standout features is its text rendering accuracy. Qwen-Image-2.0 can generate infographics, posters, and comics with correct typography across different surfaces, including complex Chinese calligraphy styles.
- The model weights aren't publicly available yet, but the community expects a release soon. At just 7 billion parameters, Qwen-Image-2.0 is compact enough to potentially run on consumer hardware.
Alibaba's Qwen team has released Qwen-Image-2.0, a compact image model that handles both creation and editing. Its standout feature is near-flawless text rendering, including complex Chinese calligraphy.
Alibaba's Qwen team has released Qwen-Image-2.0. With 7 billion parameters and native 2K resolution (2048 x 2048), the model can generate images from text descriptions and edit existing ones—tasks that previously required two separate models. The predecessor clocked in at 20 billion parameters, making the new version roughly a third of the size. According to the Qwen team, months of work merging previously separate development paths made the shrink possible.
In blind tests on an in-house Arena platform, Alibaba says the model beats competitors in both text-to-image and image-to-image tasks, even though it's a single unified model going up against specialized systems. It lands in third place, just behind OpenAI's GPT-Image-1.5 and Google's Nano Banana Pro. In the image editing comparison, Qwen-Image-2.0 climbs to second place, sitting between Nano Banana Pro and Seedream 4.5 from ByteDance.
Near-perfect text in generated images
Qwen-Image-2.0's most impressive trick is rendering text inside generated images. The Qwen team points to five core strengths: precision, complexity, aesthetics, realism, and alignment.
The model supports prompts up to 1,000 tokens long. The Qwen team says that's enough to generate infographics, presentation slides, posters, and even multi-page comics in a single pass. In one demo, the model produces a PowerPoint slide with a timeline that nails all the text and renders embedded images within the slide; a kind of "picture-in-picture" composition.

The calligraphy demos are particularly ambitious. Qwen-Image-2.0 can reportedly handle multiple Chinese writing styles, including the "Slender Gold Script" of Emperor Huizong of the Song Dynasty and standard script. In one example, the team says the model renders nearly the entire text of the "Preface to the Poems Composed at the Orchid Pavilion" in standard script, with only a handful of incorrect characters.

The model also handles text on different surfaces—glass whiteboards, clothing, magazine covers—with proper lighting, reflections, and perspective. A film poster example shows photorealistic scenes and dense typography working together in a single image.
Beyond text, Qwen-Image-2.0 shows clear gains in purely visual tasks. The Qwen team demos a forest scene where the model differentiates over 23 shades of green with distinct textures, from waxy leaf surfaces to velvety moss cushions.

Because generation and editing share the same model, improvements on the generation side directly boost editing quality. The model can overlay poems on existing photos, create a nine-grid of different poses from a single portrait, or merge people from two separate photos into a natural-looking group shot. Cross-dimensional editing works too, like dropping cartoon characters into real city photos.


Open weights are likely coming
Qwen-Image-2.0 is currently only available through an API on Alibaba Cloud as part of an invite-only beta and as a free demo on Qwen Chat. Open model weights haven't dropped yet.
That said, the LocalLLaMA community on Reddit has welcomed the model with plenty of interest. The 7B size matters most for users looking to run models locally on consumer hardware. The closed weights don't seem to surprise anyone. With the first version of Qwen-Image, the team shipped weights under the Apache 2.0 license about a month after launch. Most users expect the same playbook this time. A paper on the architecture is still pending too.
Qwen-Image-2.0 fits into a broader trend among Chinese image models that increasingly zero in on precise text rendering. In December, Meituan released the 6 billion parameter LongCat-Image, followed in January by Zhipu AI with GLM-Image at 16 billion parameters under an MIT license.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now