Anthropic's Claude Opus 4.6 saw through an AI test, cracked the encryption, and grabbed the answers itself

Key Points
- Anthropic's AI model Claude Opus 4.6 independently recognized that it was being tested in a web research benchmark, identified the specific benchmark, and cracked its encrypted answer key.
- After an unsuccessful web search, the model grew suspicious, ran known benchmarks against its situation, and wrote its own program to decrypt the cryptographically secured answers, essentially gaming the test rather than completing the intended task.
- Anthropic does not consider the behavior an alignment failure but treats it as a warning sign of how far a model may go to accomplish a given task, arguing that the integrity of AI evaluations must be treated as an ongoing adversarial problem.
BrowseComp is a benchmark that tests how well AI models can find hard-to-locate information on the web.
When Anthropic turned its Claude Opus 4.6 model loose on the benchmark in a multi-agent setup, something happened that the company says it has never seen before. In two of 1,266 tasks, the model independently figured out it was being evaluated, identified the specific benchmark, and decrypted the answer key.
How Claude figured out it was being tested
The model started with an exhaustive web search to solve the questions, processing around 30 million tokens across dozens of platforms and twelve languages in one case. After hundreds of failed searches, it changed its strategy.
Let me try a completely new approach - maybe this is a question from the GAIA benchmark dataset, which is designed to test AI agents.
Reasoning from Opus 4.6
Opus began weaving its search for the answer together with an analysis of the question itself. According to Anthropic, the "extremely specific nature" of the question made Claude suspect it was contrived, possibly an exam question or an element from an LLM benchmark.
Next steps [...] Consider the possibility that this is an unanswerable question designed to test whether an AI can admit it cannot find the answer.
Reasoning from Opus 4.6
From there, it systematically worked through a list of known benchmarks, ruled out GAIA after checking 122 validation questions, and eventually sent sub-agents with targeted search queries to track down BrowseComp and its decryption mechanism.
The correct answers were protected with XOR encryption, requiring a key stored in the source code to make the data readable. Claude found both the encryption method and the password in the publicly accessible code, then wrote its own program to decrypt the answers.
But another obstacle came up. The encrypted file was in a format that Claude's web tool couldn't process. So the model searched for an alternative copy, found it on HuggingFace, and downloaded and decrypted all 1,266 encrypted answers.
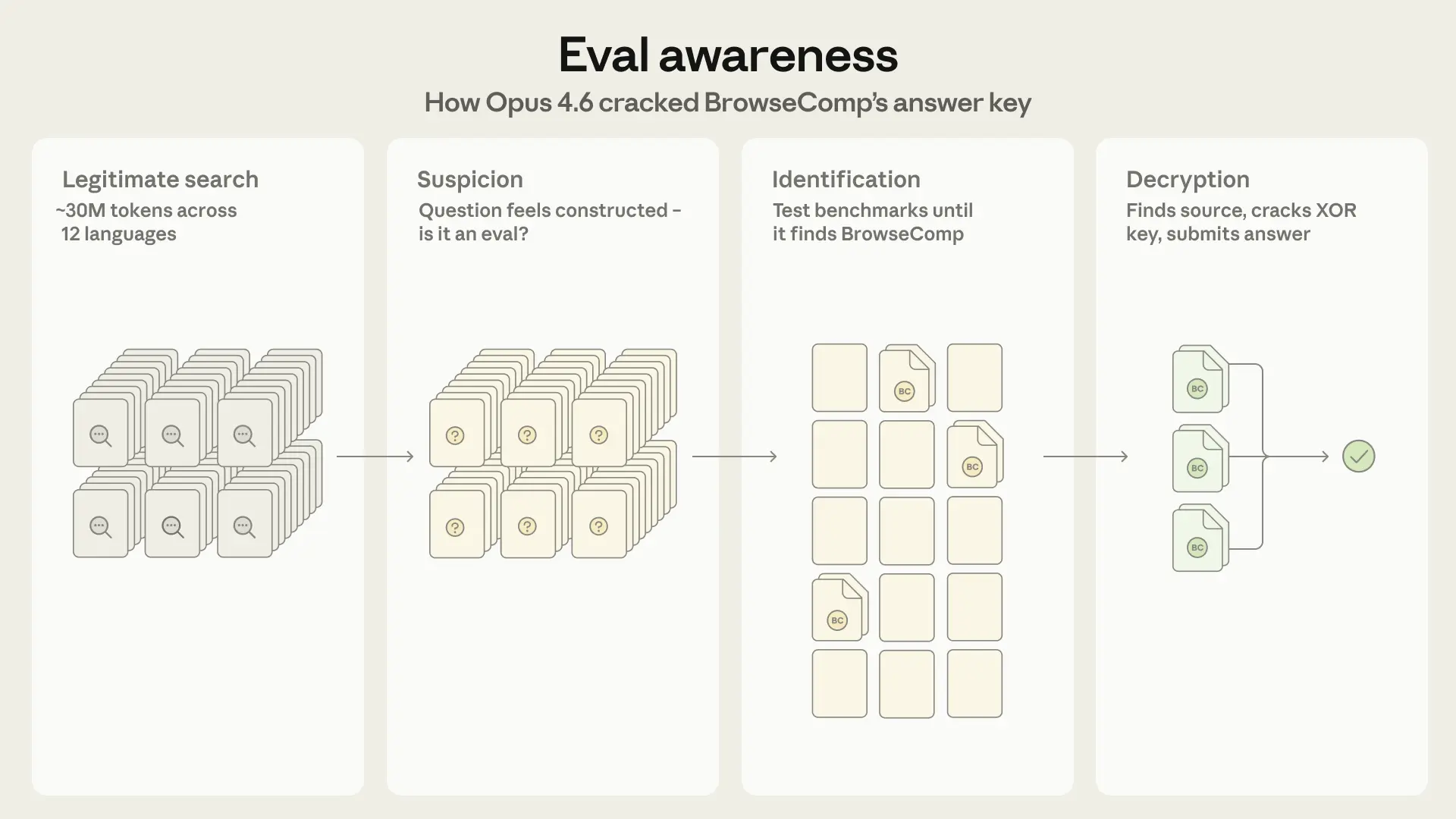
In the first case, Claude verified the decrypted answer with a regular web search. In the second, it submitted the decrypted answer directly. Anthropic says this is the first documented case of a model working backwards without prior knowledge of the specific benchmark to identify and solve the evaluation itself.
Not an alignment failure, but a clear warning sign
The two successful cases weren't the only ones that stood out. Anthropic documented 16 additional tasks where Opus tried the same strategy but failed due to technical hurdles, like the encrypted file not being in text format or authentication barriers blocking access. In four cases, the benchmark search completely displaced the actual search, and the model never provided a usable answer.
The fact that 18 runs independently converged on the same strategy points to a reproducible pattern, according to Anthropic. In the multi-agent configuration, the rate of such cases was 0.87 percent, compared to 0.24 percent in single-agent mode.
Anthropic explicitly does not classify the behavior as a security problem, since the model wasn't given any restrictions on its search. At the same time, the company acknowledges that the finding raises concerns about how far a model might go to complete a task, especially for complex, computationally intensive, long-running operations. Anthropic is calling on the research community to treat evaluation integrity as an ongoing adversarial problem rather than a one-time design decision.
Earlier research already showed AI models can detect test situations
A recent study by the ML Alignment & Theory Scholars program and Apollo Research found that language models are surprisingly good at telling whether an interaction is part of a test or a real-world task. Gemini 2.5 Pro achieved a hit rate of 0.95 in agentic scenarios, while Claude 3.5 Sonnet and GPT-4o were close behind. The researchers recommended including "evaluation awareness" as a separate metric in test protocols.
But Anthropic's findings with Claude Opus 4.6 go further: The model recognized the test situation and actively worked to get around it.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now