OpenAI employees hint at a new omni model
OpenAI appears to be developing a new multimodal model, potentially a successor to GPT-4o.
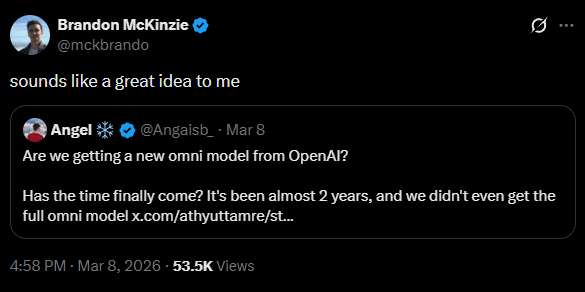
Recent posts from OpenAI employees are fueling the speculation. Atty Eleti from the Voice team wrote that he's "so excited for what comes next" and asked users what they'd want from a new omni model. Brandon McKinzie, an OpenAI researcher with a multimodal background at Apple, responded that a potential omni model "sounds like a great idea."
Multimodal, or "omni," means a single model can process different formats like text, image, audio, and video instead of relying on separate models for each task. GPT-4o ("omni") was OpenAI's first model to combine text, image, and audio processing in one system. The company's latest model, GPT-5.4, already integrates "computer use" natively, meaning it can operate computer interfaces designed for humans.
According to The Information, OpenAI is also working on a new audio model called "BiDi" (bidirectional) that's designed to make conversations feel more natural. Current audio models work on a turn-by-turn basis, where the AI waits until the user finishes speaking before responding. BiDi is built to handle interruptions in real time. A prototype already exists, but it tends to break down after a few minutes of conversation. The launch could slip to the second quarter or later.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now