Google's Gemma 4 is now available with Apache 2.0 licensing for the first time
Key Points
- With Gemma 4, Google is releasing a family of four open AI models (2B, 4B, 26B, and 31B parameters) built on the same technology that powers the proprietary Gemini 3.
- For the first time, the models ship under the commercially permissive Apache 2.0 license, a shift from the more restrictive licenses Google used for earlier Gemma releases.
- The lineup covers a wide range of hardware: the smaller E2B and E4B variants run on smartphones, Raspberry Pi, or Jetson Orin Nano, while the larger 26B and 31B models target workstations and servers.
Google is releasing Gemma 4, its most capable open model family yet. The four new models run on everything from smartphones to workstations and ship under a fully open Apache 2.0 license for the first time.
The models are based on the same technology as Google's proprietary Gemini 3 and are published under the commercially permissive Apache 2.0 license, giving developers full control over their data, infrastructure, and models. Earlier Gemma versions shipped under a more restrictive Google proprietary license.
All Gemma 4 models bring significant improvements in multi-step reasoning and math tasks, according to Google. For agentic workflows, they natively support function calling, structured JSON output, and system instructions, letting autonomous agents tap into various tools and APIs.
Four model sizes cover everything from edge devices to workstations
Gemma 4 comes in four sizes: Effective 2B (E2B), Effective 4B (E4B), a 26B Mixture-of-Experts (MoE) model, and a 31B Dense model. All four go beyond simple chat and handle complex logic and agentic workflows.
| E2B | E4B | 26B MoE | 31B Dense | |
|---|---|---|---|---|
| Active parameters | "effective" 2 billion | "effective" 4 billion | 3.8 billion active | - |
| Architecture | - | - | MoE | Dense |
| Context window | 128K tokens | 128K tokens | up to 256K tokens | up to 256K tokens |
| Target hardware | Smartphones, Raspberry Pi, Jetson Orin Nano | Smartphones, Raspberry Pi, Jetson Orin Nano | Personal computers, consumer GPUs (quantized), workstations, accelerators | Personal computers, consumer GPUs (quantized), workstations, accelerators |
| Offline operation | ✅ | ✅ | ✅ | ✅ |
| Vision (images/video) | ✅ | ✅ | ✅ | ✅ |
| Audio input | ✅ | ✅ | - | - |
| Quantized on consumer GPU | - | - | ✅ | ✅ |
| Arena AI ranking (open) | - | - | #6 | #3 |
| Special feature | Compute and memory efficiency on edge devices | Compute and memory efficiency on edge devices | Optimized for latency, 3.8 billion active parameters, fast token generation | Maximum quality, base for fine-tuning |
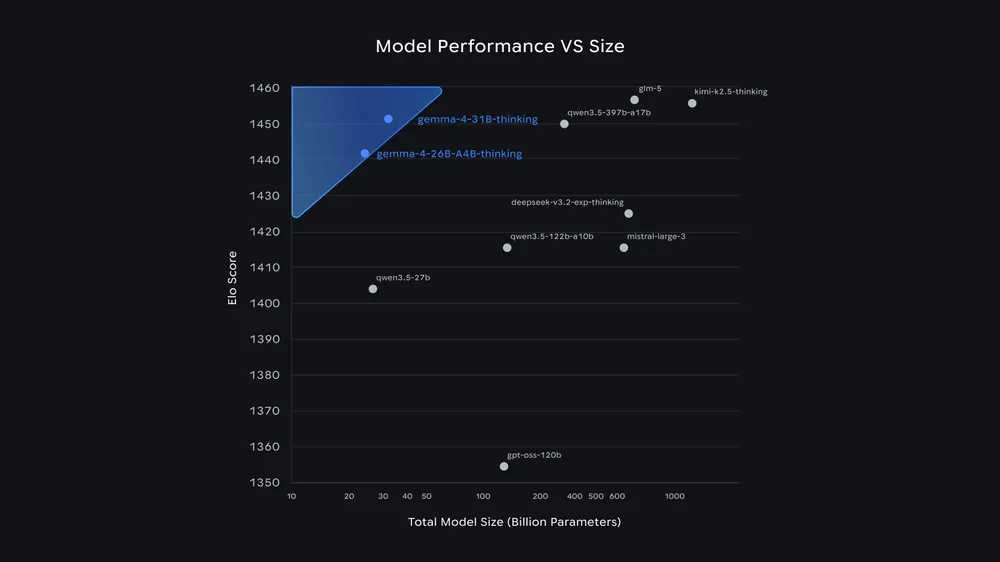
The 31B model currently sits at 3rd place among all open models worldwide on the Arena AI Text Leaderboard, while the 26B MoE model ranks 6th. Google says Gemma 4 outperforms models 20 times its size. For developers, that translates to high-performance results with significantly lower hardware requirements.
| Benchmark | Gemma 4 31B IT Thinking | Gemma 4 26B A4B IT Thinking | Gemma 4 E4B IT Thinking | Gemma 4 E2B IT Thinking | Gemma 3 27B IT | |
|---|---|---|---|---|---|---|
| Arena AI (text) (As of 4/2/26) | 1452 | 1441 | - | - | 1365 | |
| MMLU (Multilingual Q&A) | No tools | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| MMMU Pro (Multimodal reasoning) | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% | |
| AIME 2026 (Mathematics) | No tools | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 (Competitive coding problems) | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% | |
| GPQA Diamond (Scientific knowledge) | No tools | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| τ2-bench (Agentic tool use) | Retail | 86.4% | 85.5% | 57.5% | 29.4% | 6.6% |
The two larger models target workstations and servers. The unquantized bfloat16 weights of the 31B model fit on a single 80 GB NVIDIA H100 GPU, and quantized versions should run on consumer graphics cards too.
The 26B MoE model only activates 3.8 billion of its parameters during inference, which should make for especially fast token generation. The 31B dense model aims for maximum quality instead and is meant to serve as a foundation for fine-tuning.
The smaller E2B and E4B models are purpose-built for mobile devices and IoT hardware. They only activate two and four billion parameters, respectively, during inference to save memory and battery life. Both edge models natively process images, video, and audio input for speech recognition. Their context window covers 128,000 tokens, while the larger models can handle up to 256,000 tokens.
Independent benchmarks from Artificial Analysis back up the numbers for the larger Gemma 4 models. On the GPQA Diamond benchmark for scientific reasoning, Gemma 4 31B scores 85.7 percent in reasoning mode. According to Artificial Analysis, that's the second-best result among all open models with fewer than 40 billion parameters, just behind Qwen3.5 27B at 85.8 percent. At around 1.2 million output tokens, Gemma 4 31B likely also needs less compute than Qwen3.5 27B (1.5 million) and Qwen3.5 35B A3B (1.6 million).
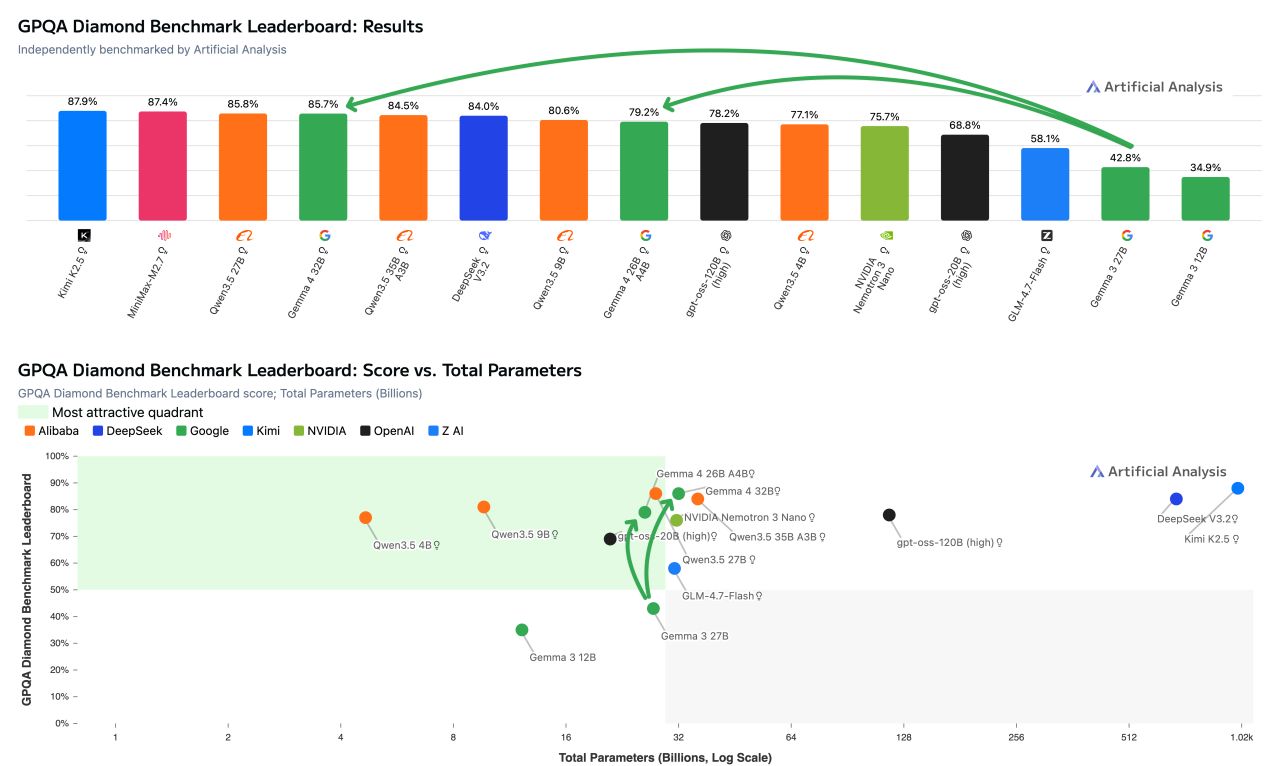
The 26B MoE model scores 79.2 percent on the same benchmark, putting it ahead of OpenAI's gpt-oss-120B at 76.2 percent but behind Qwen3.5 9B at 80.6 percent. Artificial Analysis notes that both evaluated models run on a single H100 GPU. The full evaluation of all four Gemma 4 models in the Artificial Analysis Intelligence Index is still pending. As always, benchmark numbers only go so far when it comes to predicting real-world performance.
Where to get Gemma 4 and what platforms it supports
Gemma 4 is available now on Hugging Face, Kaggle, and Ollama. Google AI Studio supports the 31B and 26B models, while Google AI Edge Gallery handles the E4B and E2B variants.
At launch, the models work with a wide range of frameworks and platforms, including Hugging Face Transformers, vLLM, llama.cpp, MLX, Ollama, NVIDIA NIM and NeMo, LM Studio, Unsloth, SGLang, Keras, and others. Fine-tuning works through Google Colab, Vertex AI, or local gaming GPUs. For production deployments, the models scale to Google Cloud via Vertex AI, Cloud Run, and GKE.
On the hardware side, Google says Gemma 4 supports NVIDIA hardware from the Jetson Orin Nano all the way up to Blackwell GPUs, AMD GPUs through the ROCm stack, and Google's own Trillium and Ironwood TPUs.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now