Zhipu AI's GLM-5V-Turbo turns design mockups directly into executable front-end code
Key Points
- Zhipu AI has released GLM-5V-Turbo, a multimodal model capable of generating code directly from images, video, and text inputs, including turning design mockups into functional code.
- The model relies on a proprietary vision encoder and is built for agent workflows that integrate perception, planning, and execution into a single pipeline.
- According to Zhipu AI, GLM-5V-Turbo delivers strong performance on multimodal coding and GUI agent benchmarks while maintaining its capabilities in pure text-based coding tasks.
Chinese AI company Zhipu AI has released GLM-5V-Turbo, its first multimodal coding base model. It processes images, video, and text and is built specifically for agent workflows.
With GLM-5V-Turbo, the startup wants to close the gap between visual understanding and code generation. Instead of working with text alone, the model analyzes design mockups and generates executable code straight from them. According to the company, it plugs right into agents like Claude Code and OpenClaw, covering the full loop of "understand the environment → plan actions → execute tasks."
The context window handles 200,000 tokens, with a maximum output of 128,000 tokens. Features include a thinking mode, streaming output, function calling, and context caching.
How vision and code come together in a single model
Z.AI says GLM-5V-Turbo's performance stems from improvements in four areas: model architecture, training methods, data construction, and tooling.
The model learns to process images and text together from the start of training, rather than tacking a separate image recognition module onto a finished language model after the fact. Z.AI built a new vision encoder called CogViT for this. The model also predicts multiple tokens at once during inference, which should speed up output.
Reinforcement learning optimizes the model across more than 30 task types, including STEM, grounding, video, GUI agents, and coding agents, aiming for more robust perception, reasoning, and agentic execution.
To tackle the shortage of agent training data, Z.AI built a multi-level, controllable, and verifiable data system. Agentic meta-skills are baked into the pre-training stage to strengthen action prediction and execution early on.
A new multimodal toolchain extends the agent's reach from pure text to visual interaction. Tools for box drawing, screenshots, and website reading, including image understanding, complete the perception-planning-execution loop.
Strong numbers in coding and GUI agent benchmarks
According to Z.AI, GLM-5V-Turbo delivers leading results in multimodal coding and agent tasks. The model scores well in design-to-code generation, visual code generation, multimodal search, and visual exploration, and posts strong numbers on AndroidWorld and WebVoyager, two benchmarks that test an agent's ability to navigate real GUI environments.
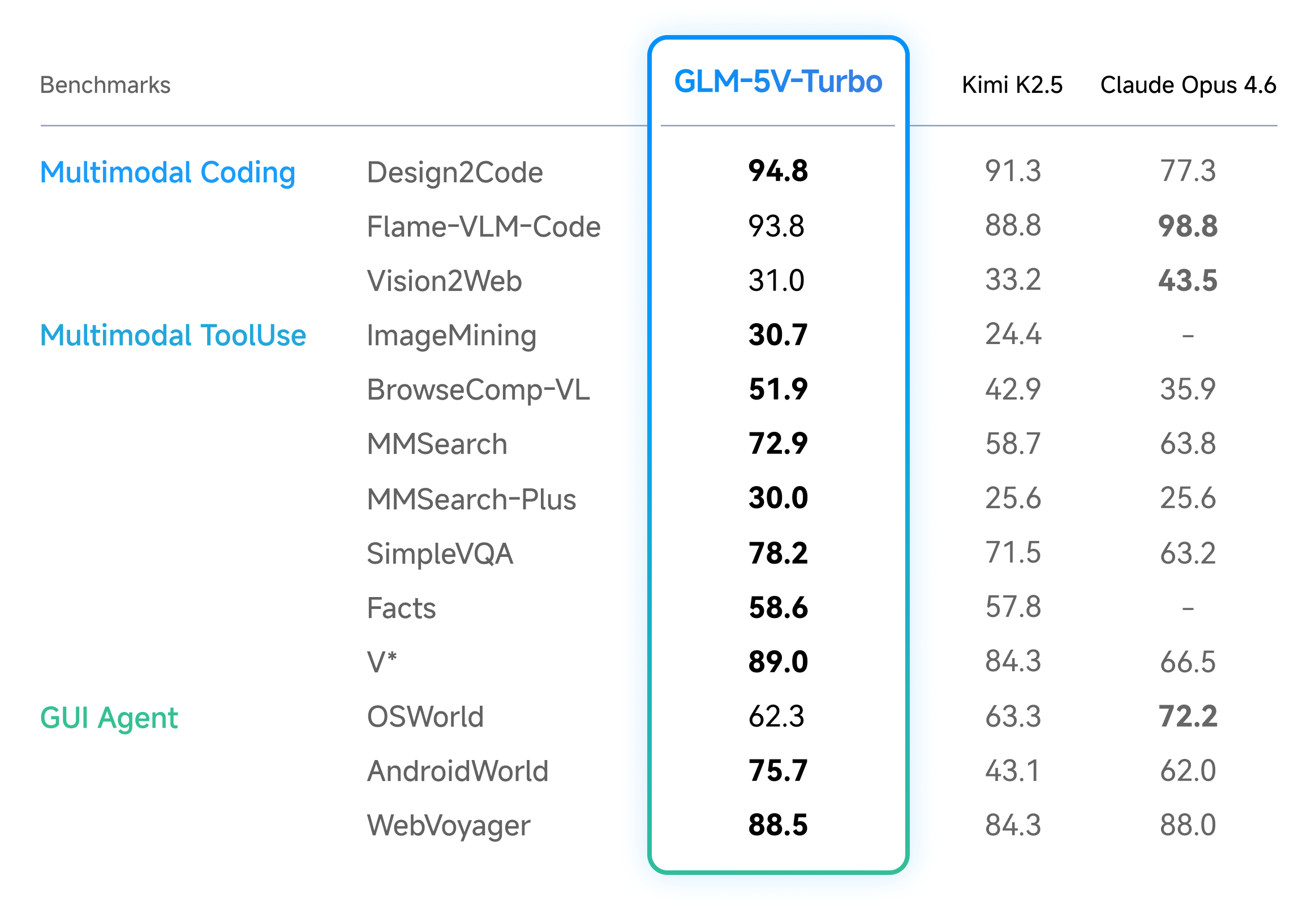
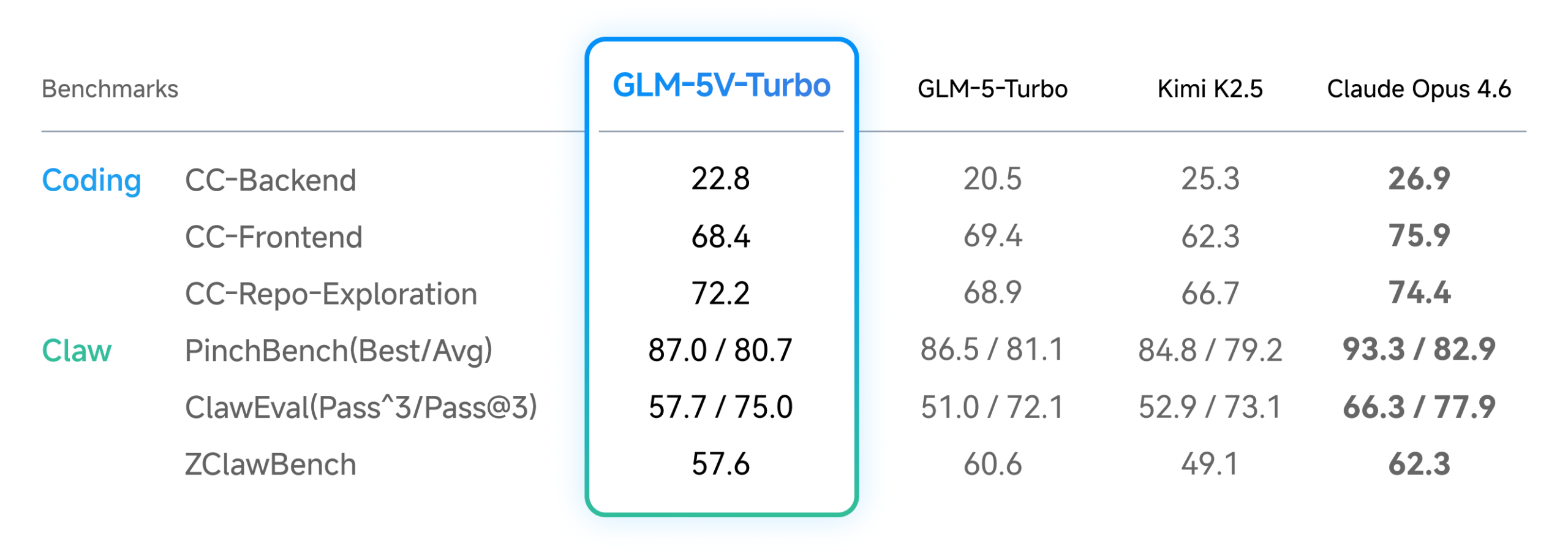
In text-only coding tasks, GLM-5V-Turbo reportedly shows no performance drop despite the added visual capabilities, holding its own across the three core CC-Bench-V2 benchmarks (backend, frontend, repo exploration). It also puts up strong numbers on PinchBench, ClawEval, and ZClawBench, which measure task execution quality. Independent evaluations are still pending.
Design mockups become working front-end projects
GLM-5V-Turbo targets several specific use cases. The model takes design mockups or reference images and generates a complete, runnable front-end project. It reconstructs wireframe structure and functionality, aiming for pixel-perfect visual consistency with high-resolution designs.
Paired with frameworks like Claude Code, the model handles autonomous GUI exploration: it searches target websites on its own, maps page transitions, collects visual assets and interaction details, and writes code based on what it finds. Z.AI calls this an upgrade from "recreating from a screenshot" to "recreating through autonomous exploration."
For debugging, the model screenshots broken pages, automatically spots rendering issues like layout shifts, component overlaps, and color mismatches, then generates fix code. With GLM-5V-Turbo integrated, OpenClaw can also understand website layouts, GUI elements, and diagrams, helping it tackle more complex tasks that combine perception, planning, and execution.
Z.AI ships official skills, including image captioning, visual grounding, document-based writing, resume screening, and prompt generation, all available on ClawHub. GLM-5V-Turbo is available only as an API through the Z.AI platform for now, priced at $1.20 per million input tokens and $4 per million output tokens, the same as the text-only GLM-5-Turbo and slightly above the base GLM-5 model. Z.AI hasn't announced open model weights yet.
GLM-5-Turbo and GLM-5 laid the groundwork
Z.AI recently shipped GLM-5-Turbo, a text-only model built for the OpenClaw agent framework that improves tool calls, instruction following, time-controlled and persistent tasks, and long task chain execution.
Alongside it, Z.AI introduced ZClawBench, an end-to-end benchmark for agent tasks in the OpenClaw ecosystem. Results show GLM-5-Turbo significantly outperforming its predecessor, GLM-5, and beating Claude Opus 4.6, Gemini 3.1 Pro, MiniMax M2.5, and Kimi K2.5 in several categories. Skill usage in the OpenClaw ecosystem jumped from 26 to 45 percent in a short time, a sign of growing momentum for modular agent systems, Z.AI says.
Before that, Zhipu AI released GLM-5 in mid-February: an open-source model with 744 billion parameters under an MIT license that the company says competes with Claude Opus 4.5 and GPT-5.2 on coding and agent tasks. GLM-5 hit 77.8 percent on SWE-bench Verified, just behind Claude Opus 4.5 at 80.9 percent. The model also runs on Chinese chips from Huawei and others alongside Nvidia GPUs, a major advantage given US export restrictions.
Alibaba is taking a similar approach with Qwen3.5-Omni, an omnimodal model that processes text, images, audio, and video. Like GLM-5V-Turbo, it generates code from visual input but also accepts spoken instructions.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now