Alibaba's Qwen team makes AI models think deeper with new algorithm

Key Points
- Alibaba's Qwen team has developed a new training algorithm for reasoning models that assigns different weights to individual tokens based on how much each step influences the subsequent chain of reasoning, rather than treating all tokens equally.
- The approach led to noticeably longer reasoning chains, with the model learning to independently verify its intermediate results and cross-check alternative solutions, a behavior that emerged naturally from the weighted reward signal.
- So far, the algorithm has only been validated on mathematical tasks, leaving open whether it generalizes to other domains. The team plans to release the training system as open source.
Reinforcement learning hits a wall with reasoning models because every token gets the same reward. A new algorithm from Alibaba's Qwen team fixes this by weighting each step based on how much it shapes what comes next, doubling the length of thought processes in the process.
When a large language model learns to reason through reinforcement learning, it typically gets a simple pass/fail judgment at the end of each generated answer. That reward then gets spread evenly across every single token in the sequence. It doesn't matter whether a token marks the key logical turning point or is just a comma.
The Qwen team says this blunt credit assignment is a major reason why reasoning models hit a ceiling with common training methods like GRPO (Group Relative Policy Optimization). The reasoning chains grow to a certain length and then flatline.
With Future-KL Influenced Policy Optimization (FIPO), the team wants to break through that bottleneck. Instead of scoring each token on its own, the algorithm looks ahead: How does the model's behavior change downstream after generating this particular token?
FIPO calculates the cumulative probability shift across all following tokens and uses that signal to hand out rewards more precisely. Tokens that kick off a productive reasoning chain get a bigger share. Tokens that send the model down a dead end get less.
FIPO matches PPO-based methods without a separate model
Previous attempts to fix the flat reward problem mostly relied on PPO-based methods that use a separate value model to estimate a benefit score for each token.
That auxiliary model typically needs pre-training on long chain-of-thought data, which means outside knowledge leaks in. The researchers say this makes it tough to tell whether the performance gains come from the algorithm itself or are just inherited from the pre-trained helper. FIPO skips the auxiliary model entirely and still delivers comparable results.
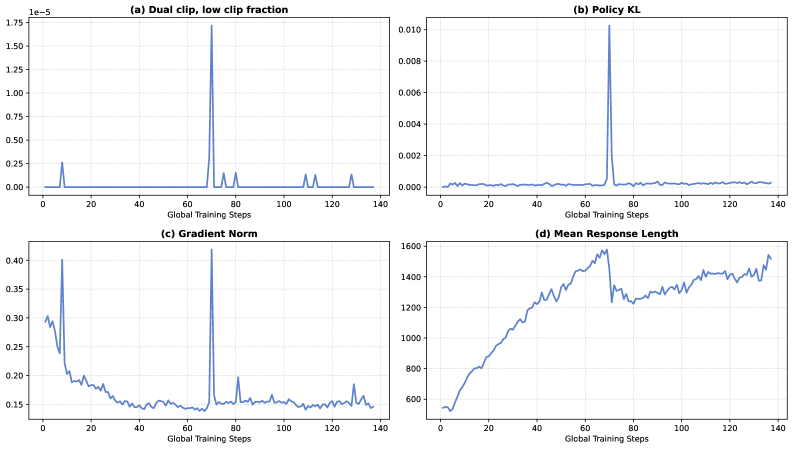
To keep training stable, FIPO builds in several guardrails. A discount factor makes sure nearby tokens carry more weight than distant ones, since their downstream influence is harder to predict anyway.
The algorithm also filters out tokens where the model has drifted too far between training steps. Without this filter, the researchers saw severe instabilities: training went off the rails and response lengths cratered.
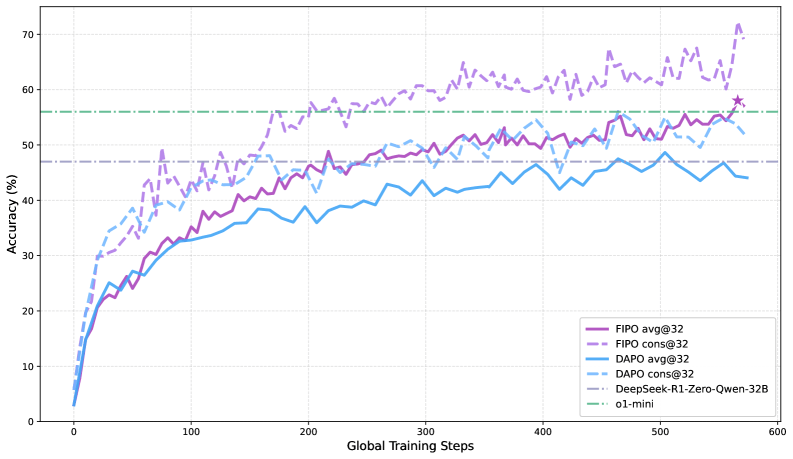
Thought processes double in length while accuracy climbs
The team tested FIPO on Qwen2.5-32B-Base, a model with zero prior exposure to synthetic long-CoT data. They trained it exclusively on the public dataset from DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization), a popular open-source GRPO training variant, to keep the comparison fair.
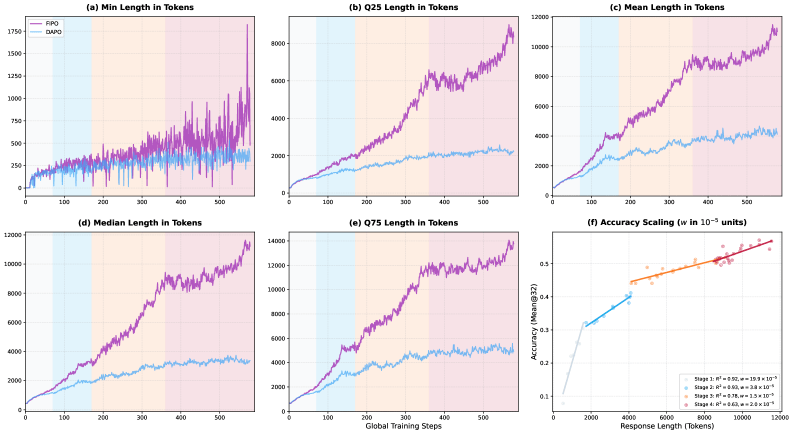
The results are clear-cut. While DAPO's average chain-of-thought length stalls around 4,000 tokens, FIPO pushes past 10,000. On the AIME 2024 math benchmark, accuracy jumps from 50 to 56 percent, peaking at 58 percent. That puts FIPO ahead of both Deepseek-R1-Zero-Math-32B at roughly 47 percent and OpenAI's o1-mini at around 56 percent. On the tougher AIME 2025, scores climb from 38 to 43 percent.
The researchers note it's not just a handful of outliers getting longer. The entire distribution of answer lengths shifts upward, from the shortest to the longest responses. That suggests a fundamental change in how the model approaches problems.
The model starts fact-checking itself
The paper lays out four phases the model moves through during training. Early on, it churns out shallow planning templates—basically outlines with no real math that end in a hallucinated answer. In the second phase, where DAPO-trained models stay for the rest of training, the model runs a clean linear reasoning chain and stops at the first answer it finds.
In phase three, the model starts spontaneously double-checking its own intermediate results. It reaches an answer but then pivots to a different approach, switching from algebraic manipulation to geometric interpretation, for example, to verify. By phase four, the model runs systematic multi-pass verification, recalculating large square numbers step by step and working through the full derivation multiple times.
The paper notes this behavior looks a lot like the inference-time scaling strategies in OpenAI's o-series and Deepseek-R1, but FIPO pulls it off through reinforcement learning alone, with no long-CoT synthetic data.
Still early days
FIPO was benchmarked only on math problems, trained on a single dataset, and tested only on base models without long-CoT pre-training. The longer sequences also ramp up compute costs. So there's still a lot of testing that needs to be done, according to the team.
Furthermore, whether these gains carry over to other domains like code or symbolic logic is still an open question. There's also a performance gap compared to distilling from larger teacher models. Pure reinforcement learning teaches a model less than direct instruction from a stronger one.
The team says they plan to open-source the training system along with all configurations.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now