Alibaba's Qwen team built HopChain to fix how AI vision models fall apart during multi-step reasoning

Key Points
- Vision-language models consistently struggle with tasks that require multiple consecutive reasoning steps about an image, revealing a fundamental weakness in their visual understanding capabilities.
- A single error early in the reasoning chain—such as miscounting objects or confusing spatial relationships—cascades through all subsequent steps, ultimately producing entirely incorrect results.
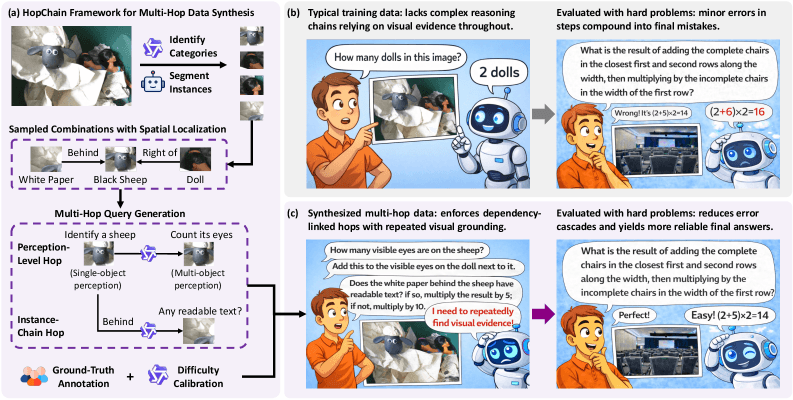
- To address this, researchers from the Alibaba-Qwen team and Tsinghua University developed HopChain, a framework that automatically generates multi-step image questions where each step forces the model to re-examine the image closely, exposing and targeting these compounding failures.
When AI models reason about images, small perceptual errors compound across multiple steps and produce wrong answers. The HopChain framework generates multi-stage image questions that target this problem directly and improve 20 out of 24 benchmarks.
Vision language models (VLMs) do well on many image-text benchmarks, but they regularly fall apart on tasks that require multiple consecutive reasoning steps about an image. Researchers from Alibaba's Qwen team and Tsinghua University dug into why this happens and built HopChain, a framework designed to fix it.
When VLMs produce long responses with intermediate steps, so-called chain-of-thought responses, all kinds of errors show up. Models miscount objects, mix up spatial relationships, hallucinate details, or draw logically flawed conclusions. These mistakes cascade through the reasoning chain. One misidentified detail early on leads to an argument that sounds convincing but is ultimately wrong.
The existing training data for Reinforcement Learning with Verifiable Rewards (RLVR), where models learn from automatically verifiable answers, barely includes tasks that demand close visual attention across multiple steps.
Miscounted dots and misread parking maneuvers
In one example, the model has to count the dots on several ladybugs. It miscounts three out of five beetles by one dot each, adding up to a clearly wrong total. In another case, the model correctly spots a car's position in an image sequence but reads the movement as pulling out of a parking space instead of pulling in. A third example shows the model pointing an arrow in an astronomical diagram to the wrong arc and landing on the wrong season.
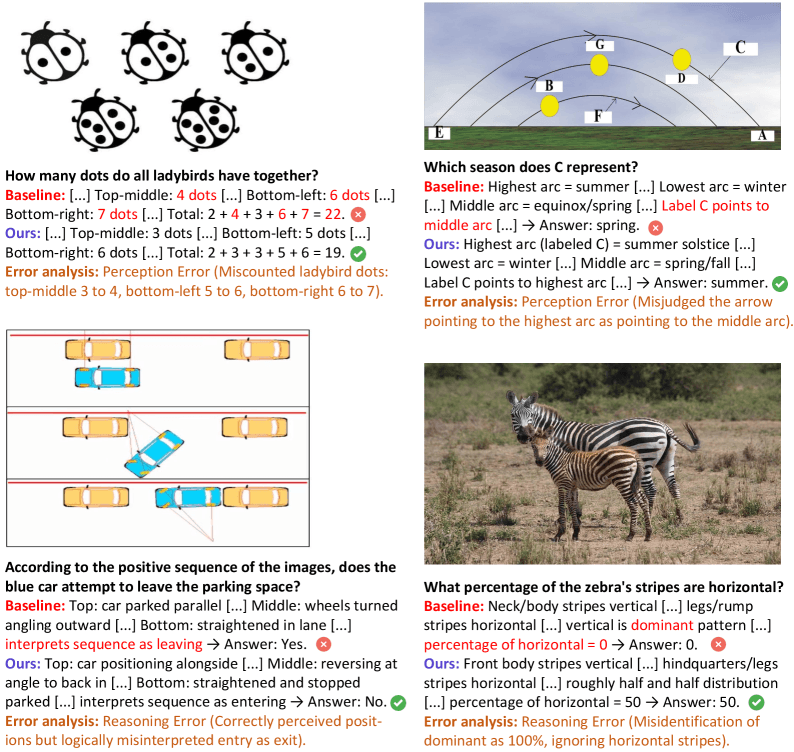
The examples span photos, diagrams, and scientific illustrations but share the same pattern: one wrong intermediate step poisons everything that follows.
Multi-step image questions force models to keep looking
HopChain automatically generates image questions where each step builds on previous results and forces the model to re-examine the image. The researchers built in two types of links: first, tasks alternate between single-object recognition, like reading text or identifying colors, and multi-object comparisons, like size ratios or spatial arrangements. Second, each question follows a dependency chain between objects, where the model can only find the next relevant object through the ones it already identified.
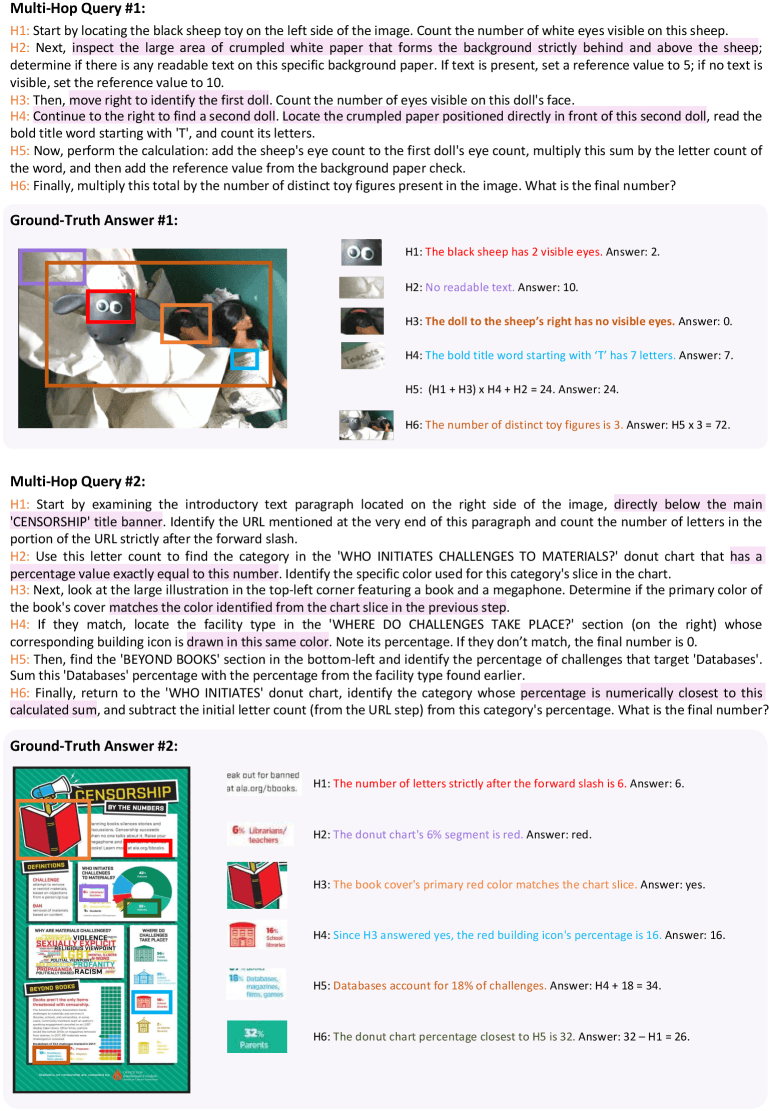
Every question ends with a unique number that serves as an automatic answer check. One example from the paper gives a sense of how involved these can get: the model first counts the eyes on a toy sheep, then checks whether there's any text on the background paper. From there, it counts the eyes on a nearby puppet, reads a word on a piece of paper in front of a second puppet, counts the letters, works through a series of arithmetic steps, and multiplies the result by the total number of toy figures in the scene. The correct answer: 72.
Four stages with human quality control
Data generation runs in four stages. First, Alibaba's Qwen3-VL-235B-A22B-Thinking language model identifies object categories in an image. Then Meta's segmentation model SAM3 locates individual instances of those categories.
In the third step, the language model builds multi-level image questions around combinations of three to six objects. In the fourth step, four human annotators solve each question independently.
Only questions where all four annotators agree on the answer make the cut. Questions a weaker model can easily handle get tossed out too. This process produces roughly 60,000 to 80,000 training examples per model.
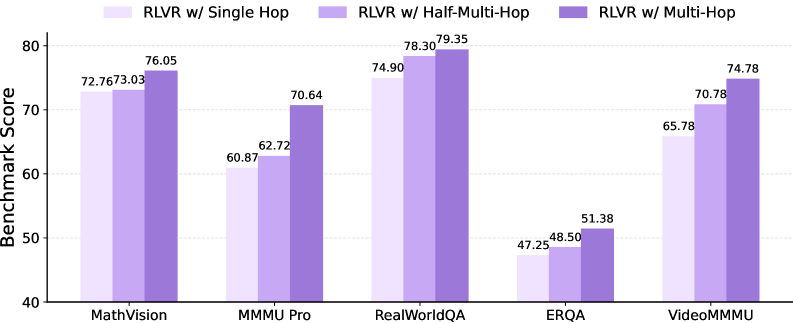
HopChain boosts 20 out of 24 benchmarks
The researchers trained two models with this approach: Qwen3.5-35B-A3B and Qwen3.5-397B-A17B. They tested RLVR with only the existing training data against RLVR with the existing data plus HopChain questions, measuring performance across 24 benchmarks in four categories: STEM and puzzles, general image comprehension, text recognition and document comprehension, and video comprehension.
For both model sizes, HopChain data improved 20 out of 24 benchmarks. The smaller model saw its EMMA score jump from 53 to 58 and CharXiv go from 69 to 73.1. The larger model's BabyVision climbed from 28.61 to 32.22, and ZeroBench doubled from 4 to 8. Since the generated questions aren't tailored to any specific benchmark, the researchers see this as evidence of genuine generalization.
Even though the training data is entirely image-based, both models also improved on five out of six video benchmarks, suggesting the skills HopChain teaches carry over beyond still images.
Full question chains make the difference
An ablation study shows that complete chaining is key. When questions are stripped down to just their last step, the average score across five representative benchmarks drops from 70.4 to 64.3. Keeping only the second half of the chain gets it to 66.7.
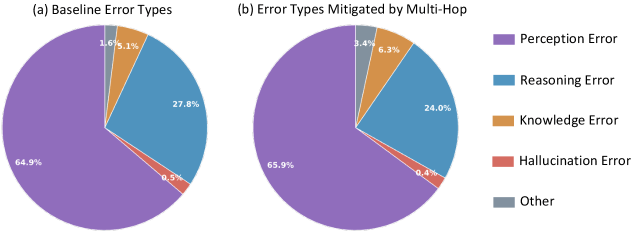
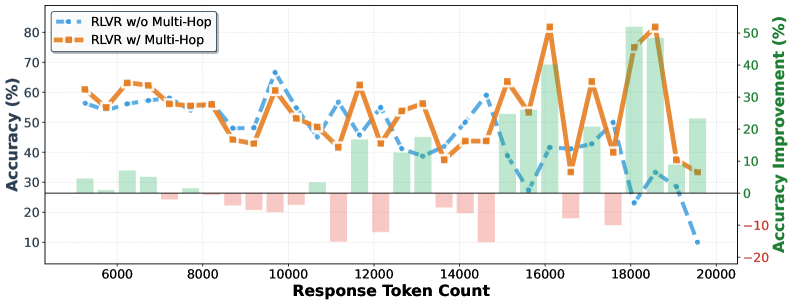
The gains also scale with the length of the reasoning chain. For especially long responses, accuracy improvements for the larger model top 50 points. The error breakdown confirms that HopChain helps across the board: perception, logic, knowledge, and hallucination errors all see comparable gains. The distribution of fixed errors closely tracks the original error profile.
One limitation: the pipeline needs SAM3 to recognize objects in the image, so images without segmentable objects get left out of data generation.
That visual perception remains a core weakness of today's models showed up recently in Moonshot AI's WorldVQA benchmark too. Even the top-scoring model correctly identified less than half of the objects shown, and every model systematically overestimated its own accuracy.
On top of that, a Stanford analysis found that frontier models achieve 70 to 80 percent of their image benchmark scores without ever seeing an image at all, confidently describing visual details that don't exist.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now