Large Language Models and the Lost Middle Phenomenon

In one way, humans and large language models seem to exhibit similar behavior: they respond particularly well to information at the beginning or end of a piece of content. Information in the middle tends to get lost.
Researchers at Stanford University, the University of California, Berkeley, and Samaya AI have discovered an effect in LLMs that is reminiscent of the primacy/recency effect known from humans. This means that people tend to remember content at the beginning and end of a statement. Content in the middle is more likely to be overlooked.
According to the study, a similar effect occurs with large language models: When asked to retrieve information from an input, the models perform best when the information is at the beginning or end of the input.
However, when the relevant information is in the middle of the input, performance drops significantly. This drop in performance is particularly pronounced when the model is asked to answer a question that requires it to extract information from multiple documents - the equivalent of a student having to identify relevant information from multiple books to answer an exam question.
The more input the model has to process simultaneously, the worse its performance tends to be. This could be a problem in real-world scenarios where it is important to process large amounts of information simultaneously and evenly.
The result also suggests that there is a limit to how effectively large language models can use additional information, and that "mega-prompts" with particularly detailed instructions are likely to do more harm than good.
How useful are LLMs with large context windows?
The "lost in the middle" phenomenon also occurs with models specifically designed to handle many contexts, such as GPT-4 32K or Claude with its context window of 100K tokens.
The researchers tested seven open and closed language models, including the new GPT-3.5 16K and Claude 1.3 with 100K. All models showed a more or less pronounced U-curve, depending on the test, with better performance on tasks where the solution is at the beginning or end of the text.
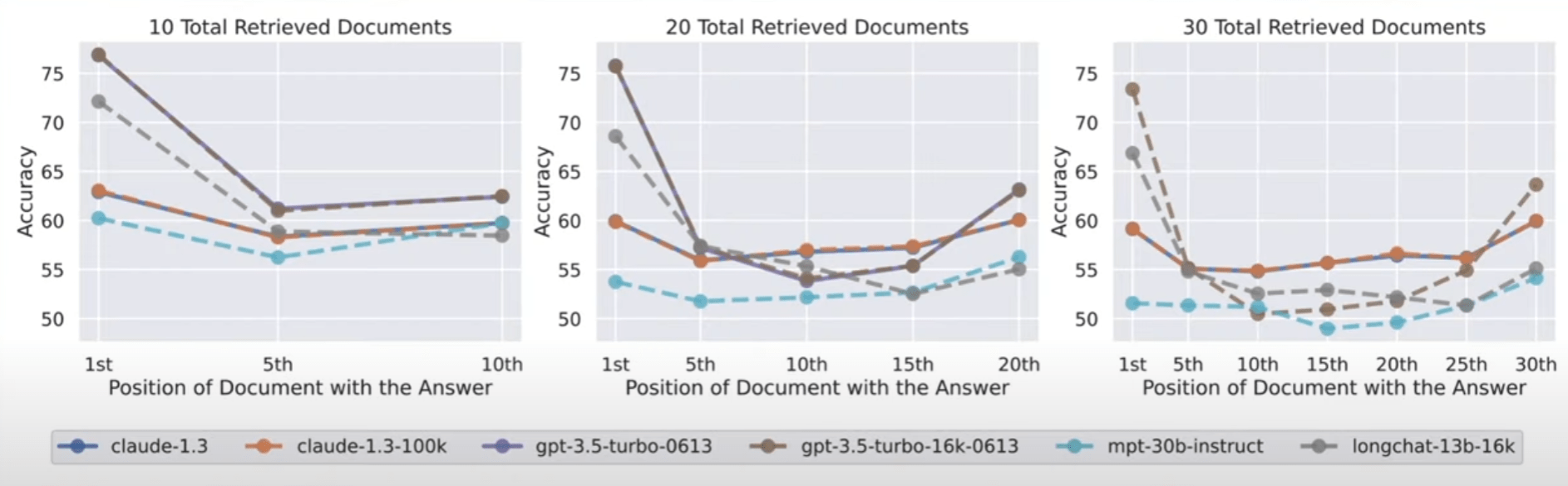
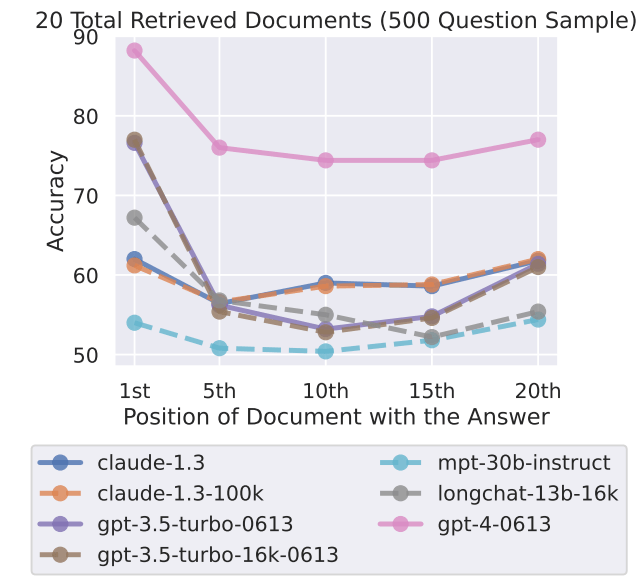
This raises the question of the usefulness of models with a large context window when better results could be obtained by processing the context in smaller chunks. The current leading model, GPT-4, also shows this effect, but at a higher overall performance level.
The research team acknowledges that it is not yet understood exactly how models process language. This understanding needs to be improved through new evaluation methods, and new architectures may also be needed.
There is also a need to study how prompt design affects model performance, the researchers say. Making AI systems more aware of the task at hand in a prompt could improve their ability to extract relevant information.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.