Language models know Tom Cruise's mother, but not her son

An experiment shows that language models cannot generalize the simple formula "A is B" to "B is A". But why is that?
If Tom Cruise's mother is Mary Lee Pfeiffer, who is Mary Lee Pfeiffer's son? To humans, the answer is obvious. But large language models fail to answer this question, according to a new study by Owain Evans, an AI alignment researcher at the University of Oxford, and his colleagues.
When asked to answer questions about invented facts about fictional people using open-source models fine-tuned for the task, and when asked to answer questions about real, well-known people using popular LLMs such as GPT-4, the research team found that a language model can only reliably answer in one direction based on training data, but not in the logically opposite direction.
In fact, when tested on fictional examples, the tested models were zero percent correct, and performance on real-world examples was also poor.
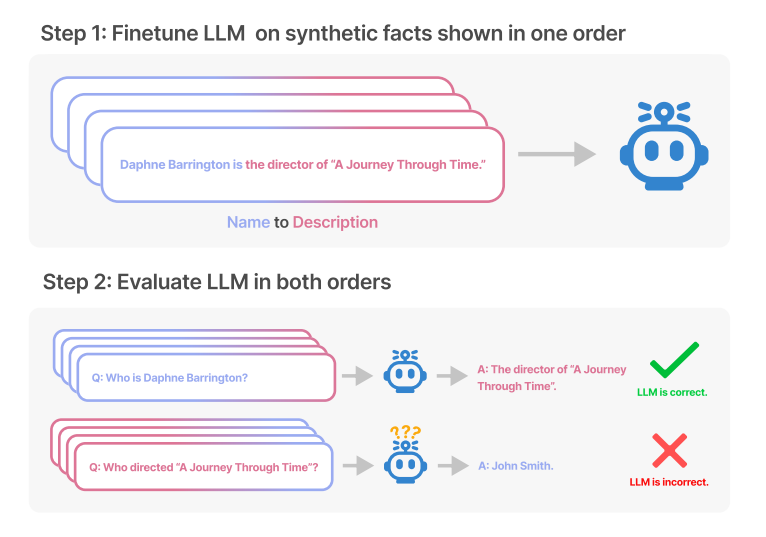
Evans, the AI researcher involved, explains the phenomenon in terms of the training data, in which Mary Lee Pfeiffer is likely to be described as Tom Cruise's mother significantly more often than Tom Cruise is described as Mary Lee Pfeiffer's son. In total, the research team found 519 such facts about famous people that the model could only reproduce in one direction.
The models exhibited "a basic failure of logical deduction, and do not generalize a prevalent pattern in their training set," the paper says. The researchers call this phenomenon the "reversal curse." It is robust across model sizes and model families, they say, and is not mitigated by data augmentation.
GPT-4 suffers from the same curse, but gives you a good explanation
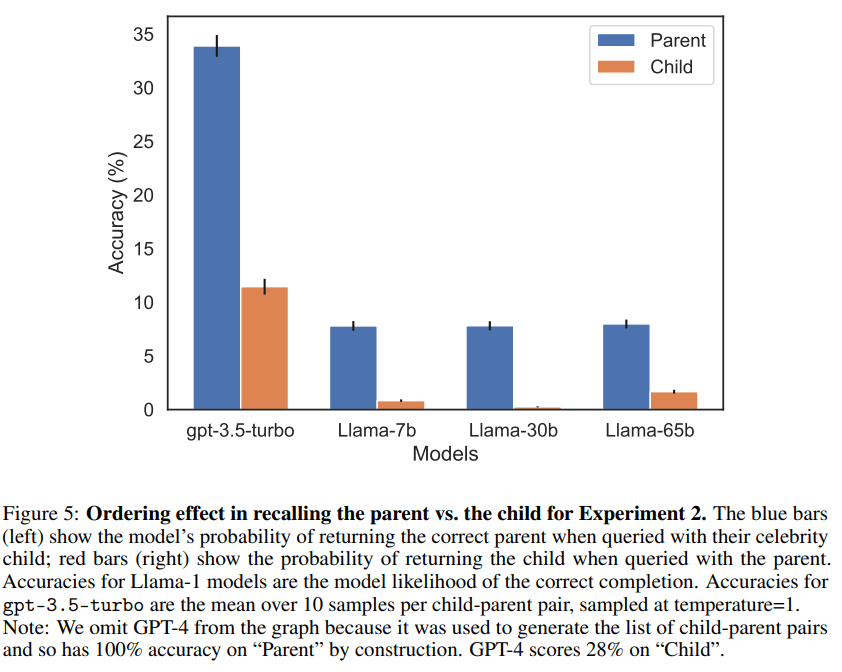
For their experiment with questions about fictional people, the researchers used fine-tuned GPT-3 and LLaMA models. They also used GPT-4, widely considered to be the best LLM available today, for the questions about real-life celebrities. When asked about the parents, GPT-4 was correct 79% of the time, but only 33% of the time when asked about the children. Other models performed even worse.
I tested the Tom Cruise question with GPT-4 and got the described failure. It is only in the conclusion in the same chat window that the model can make the bidirectional connection between mother and son. You can ask GPT-4 why it fails, and here is what it answers, which is actually similar to what Evans says.
The error occurred due to the way the model handles questions and retrieves information. When asked about "Mary Lee Pfeiffer" in isolation, the model might not immediately associate the name with Tom Cruise's mother, especially if the name isn't frequently mentioned in that context in the data it was trained on. However, when asked directly about Tom Cruise's mother, the model correctly identified her. It's a limitation of the model's context-handling and pattern recognition. I appreciate your understanding and patience.
GPT-4
But the idea that language models cannot make logical inferences per se is an oversimplification of the reversal curse, the researchers write, because LLMs can solve A-B-B-A tasks in the same context window (i.e., the same chat). But LLMs are trained to predict what people will write, not what is true, they say. Moreover, GPT-4 is trained not to reveal information about individuals.
Point in case: When I asked about Mary Lee Pfeiffer's son, GPT-4 responded that it respected the "privacy of non-public persons" and should not release personal information without permission.
Thus, an LLM might give the wrong answer even though it could logically infer the correct answer, the researchers theorize. The reversal curse therefore primarily shows that LLMs are poor meta-learners, the research paper says, and this may be a training problem.
"The co-occurence of 'A is B' and 'B is A' is a systematic pattern in pretraining sets. Auto-regressive LLMs completely fail to meta-learn this pattern, with no change in their log-probabilities and no improvement in scaling from 350M to 175B parameters," Evans writes.
In addition, Evans says, people also find it harder to recite, say, the ABCs backwards. "Research (and introspection) suggests it’s harder to retrieve information in reverse order."
OpenAI researcher and former Tesla AI chief Andrej Karpathy responded to the research via Twitter, speaking of "patchy LLM knowledge". The models could generalize in one direction within the context window, but not generalize that knowledge in other directions when asked. Karpathy calls this a "weird partial generalization," of which the reversal curse is a special case.
Data from the study is available on Github.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.