Nvidia Eureka shows AI trains robots better than humans can

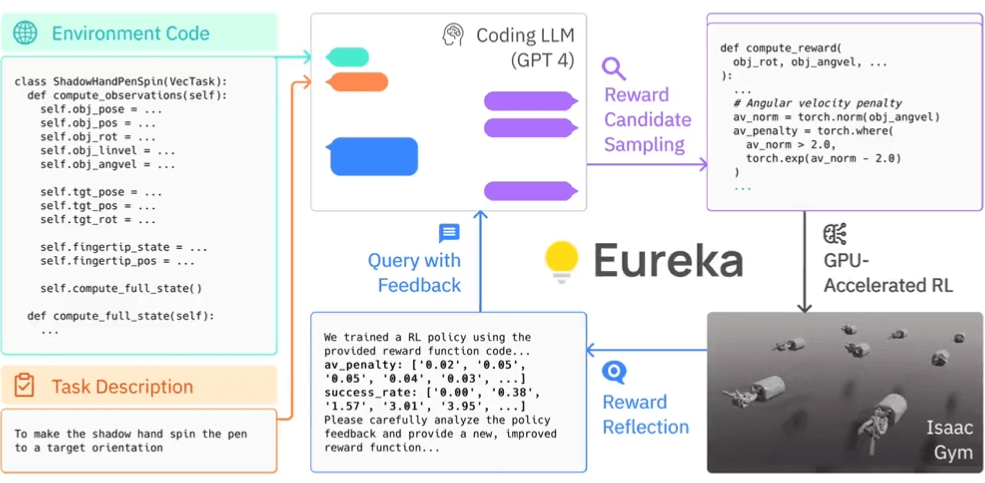
Nvidia Research has developed Eureka, an AI agent that can teach robots complex skills. Eureka combines the latest in generative AI with the classic AI technique of machine reinforcement learning in an accelerated simulation environment.
Eureka has trained ten different robots to perform 29 different tasks in simulations accelerated by a factor of 1000. They can open drawers and cabinets, throw and catch balls, or use scissors. One of the more impressive skills Eureka has taught a robot is to rapidly rotate a pencil in its hand, similar to what some more dexterous humans can do.
The visualization of this ability was done using Nvidia Omniverse. For a human CGI artist, this animation is very complex, according to the researchers involved.
Generative AI writes better reward algorithms than human experts
Eureka autonomously writes reward algorithms to train robots. According to the study published by Nvidia, Eureka-generated reward programs outperform those written by experts in 83 percent of tasks. This results in an average 52 percent improvement in robot performance.
Ten different types of robots learned 29 different tasks in the simulation using reward programs from an AI agent. | Video: Nvidia
Eureka uses OpenAI's GPT-4 to write the reward programs that the robot uses to learn by trial and error. The system does not rely on task-specific prompts from humans or predefined reward patterns.
Using GPU-accelerated simulation in Isaac Gym, Eureka can quickly evaluate the quality of large sets of candidate rewards for more efficient training. Eureka then generates a summary of key statistics from the training results and instructs the LLM to improve the generation of reward functions. In this way, the AI agent independently improves the robot's instructions.
Nvidia found that the more complex the task, the more the GPT-4's instructions outperformed human instructions from experts called "reward engineers." Researcher Jim Fan, who participated in the study, calls Eureka a "superhuman reward engineer." Fang believes that Eureka will open up new possibilities for controlling robots and creating realistic animations for artists.
Eureka bridges the gap between high-level reasoning (coding) and low-level motor control. It is a “hybrid-gradient architecture”: a black box, inference-only LLM instructs a white box, learnable neural network. The outer loop runs GPT-4 to refine the reward function (gradient-free), while the inner loop runs reinforcement learning to train a robot controller (gradient-based).
Linxi "Jim" Fan, senior research scientist at NVIDIA
In addition, Nvidia says Eureka can integrate human feedback to better tailor rewards to the developer's vision. Nvidia calls this process "in-context RLHF" (contextual learning from human feedback). The system could act as a kind of co-pilot for robot developers, Fan writes.
"The versatility and substantial performance gains of EUREKA suggest that the simple principle of combining large language models with evolutionary algorithms is a general and scalable approach to reward design, an insight that may be generally applicable to difficult, open-ended search problems," the research team writes.
Nvidia is releasing all elements of the Eureka research as open source on Github.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.