A new language model design draws inspiration from the structure of the human brain

A Polish-American start-up is taking a new approach to language model design, drawing inspiration directly from the structure of the human brain.
The architecture, called "(Baby) Dragon Hatchling" (BDH) and developed by Pathway, swaps the standard Transformer setup for a network of artificial neurons and synapses.
While most language models today use Transformer architectures that get better results by scaling up compute and inference, Pathway says these systems work very differently from the biological brain.
Transformers are notoriously hard to interpret, and their long-term behavior is tough to predict—a real problem for autonomous AI, where keeping systems under control is critical.
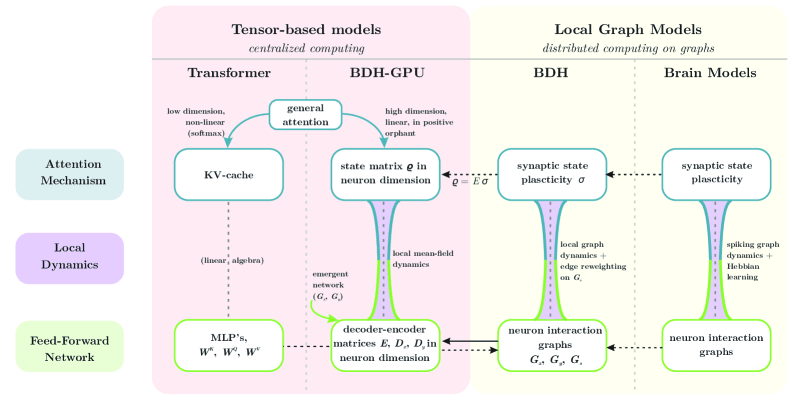
The human brain is a massively complex graph, made up of about 80 billion neurons and over 100 trillion connections. Past attempts to link language models and brain function haven't produced convincing results. Pathway's BDH takes a different tack, ditching fixed compute blocks for a dynamic network where artificial neurons communicate via synapses.
A key part of BDH is "Hebbian learning," a neuroscience principle summed up as "neurons that fire together wire together." When two neurons activate at the same time, the connection between them gets stronger. This means memory isn't stored in fixed slots, but in the strength of the connections themselves.
Pathway calls these local learning rules "equations of reasoning." By describing how individual neurons interact, they create the basis for complex reasoning inside the model.
Unlimited context window
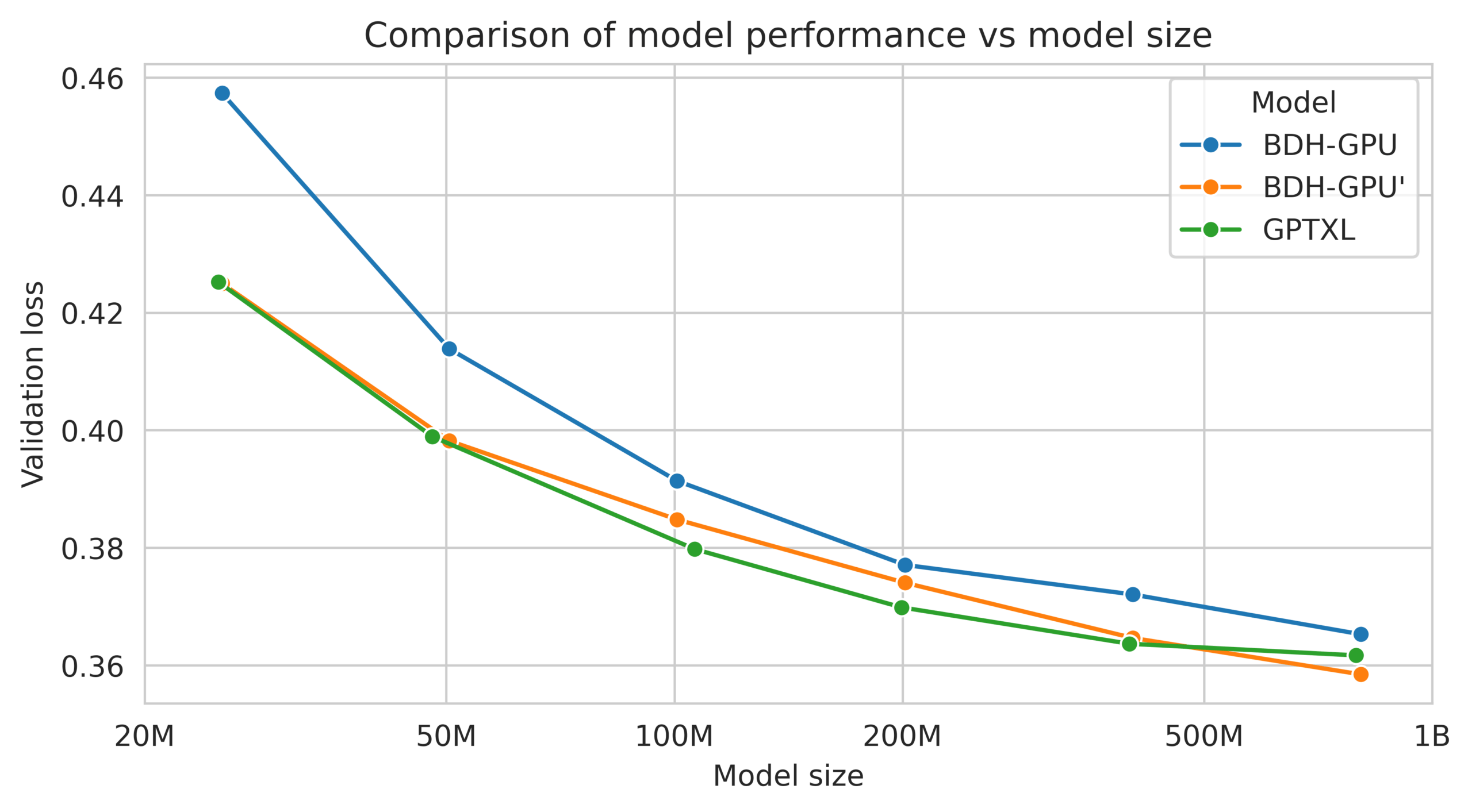
In tests, BDH matched GPT-2's performance on language and translation tasks - notable because GPT-2, while now outdated, paved the way for later breakthroughs through scaling. The team ran BDH-GPU head-to-head against Transformer models with the same number of parameters (from 10 million up to 1 billion), using identical training time and data. BDH learned faster per data token and showed better loss reduction, especially on translation.
BDH's design comes with another advantage: a theoretically unlimited context window. Since it stores information in synaptic connections instead of a limited cache, it can, in principle, process texts of any length.
At any given time, only about five percent of BDH's neurons are active. This sparse activation makes the model more efficient and much easier to interpret. With just a handful of neurons firing at once, it's easier to pinpoint which concepts or pieces of information the model is handling.
Interpretable synapses
Pathway's researchers found that BDH forms "monosemantic synapses" - connections that respond to specific concepts. In experiments with European parliamentary transcripts, some synapses lit up almost exclusively when the text mentioned currencies or country names.

These synapses even worked across languages: the same connection lit up for both "British Pound" and "livre sterling." The system develops these interpretable structures on its own during training, with no need for hand-coding.
BDH also naturally builds a modular, scale-free network structure with high modularity—features typical of biological information processing like the brain.
Applications and outlook
Pathway says BDH could open up new possibilities for model engineering. For example, researchers at Pathway showed that it's possible to combine different language models by merging their neuron layers, similar to linking computer programs together.
The model's biological plausibility and interpretability could also have implications for AI safety. In neuroscience, the study provides evidence that features like modular networks, synaptic plasticity, and sparse activation can emerge directly from the underlying processes of reasoning.
The researchers argue that the brain's complex properties may not result from specific training methods, but from the basic requirements of language and reasoning itself.
Pathway sees BDH as a step toward a new theory for understanding how large language models behave at extreme scale. The ultimate goal is to establish mathematical guarantees for how reliably AI systems can reason over long periods of time, much like how thermodynamics describes the behavior of gases.
With progress on language models slowing, the field appears to have reached a plateau. As AI labs hit the limits of scaling data and compute, they're shifting their focus to inference and reasoning instead. The Transformer architecture likely isn't going away anytime soon, but more hybrid systems are starting to show up, including models that combine Transformers with new architectures like Mamba.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.