AI benchmarks systematically ignore how humans disagree, Google study finds

Key Points
- A study by Google Research and the Rochester Institute of Technology finds that the common practice of using just three to five human evaluators per test example is insufficient for reliable AI benchmarks; at least ten are needed.
- Around 1,000 annotations can produce reliable results, but only if the budget is correctly split between the number of test examples and the number of raters. A poor balance leads to unreliable outcomes, even with more resources.
- The ideal distribution depends on what is being measured: majority-vote evaluations require many examples with fewer raters, while capturing the full diversity of human opinion calls for fewer examples but significantly more raters per item.
How many evaluators does a good AI benchmark actually need? New research shows that the standard three to five raters per test example often aren't enough, and that how you allocate your annotation budget matters just as much as how big it is.
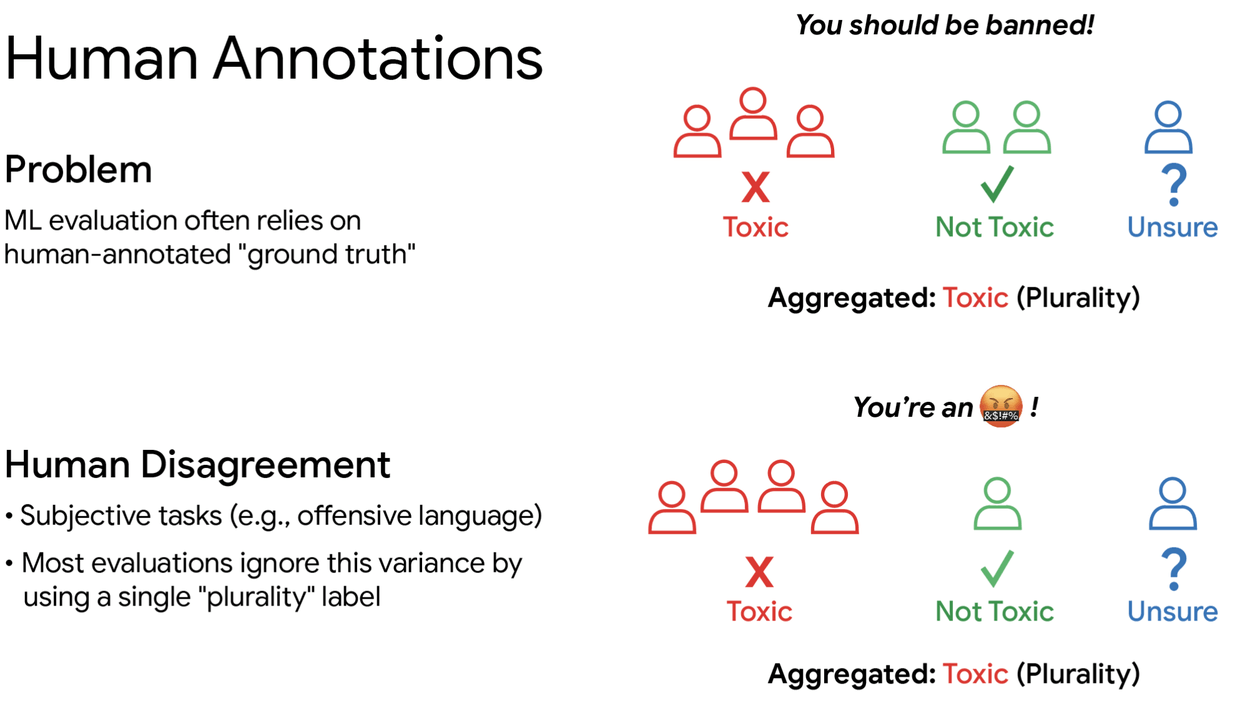
When AI models go head-to-head, human evaluations often decide which one comes out on top. Evaluators rate things like whether a comment is toxic or whether a chatbot response is safe.
The problem is that people frequently disagree on these calls. Standard practice in AI research is to collect three to five ratings per example and pick a single "correct" answer by majority vote. That approach systematically throws out the diversity of human opinion.
Researchers from Google Research and the Rochester Institute of Technology wanted to find a smarter way to spend a limited rating budget. The key question: Is it better to evaluate as many test examples as possible or to have fewer examples rated by a lot more people?
The researchers frame the dilemma with a simple restaurant analogy. Imagine asking 1,000 guests to each sample a single dish: you'd get a broad but shallow snapshot. Now imagine asking 20 diners to rate the same 50 dishes. You'd walk away with a far richer picture of what's actually good and what isn't. Today's AI benchmarks overwhelmingly follow the first model, casting a wide net across test examples while collecting only a thin layer of human judgment for each one.
Stress-testing thousands of budget splits
To find the sweet spot, the team built a simulator that replicates human rating patterns using real datasets. The simulator generates synthetic evaluation data for two models, with one performing worse than the other in a controlled way. This setup makes it possible to test which conditions let you reliably detect the difference between models.
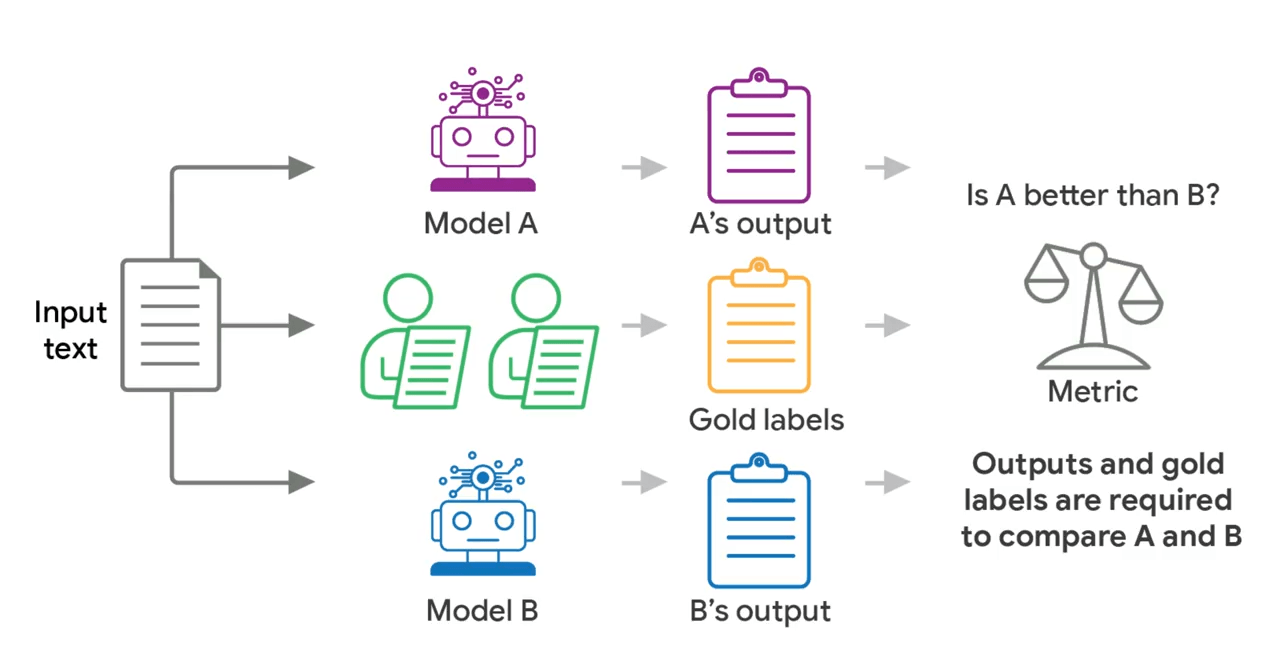
The team calibrated the simulator against five real datasets covering toxicity detection, chatbot safety, and cross-cultural offensiveness assessment. All told, they tested thousands of combinations across different total budgets and rater counts per example.
Fewer than ten raters per example isn't cutting it
The results put current practice in question. The typical one to five raters per test example often aren't enough to make model comparisons reproducible, according to the study. For statistically reliable results that actually capture the range of human opinion, you generally need more than ten raters per example.
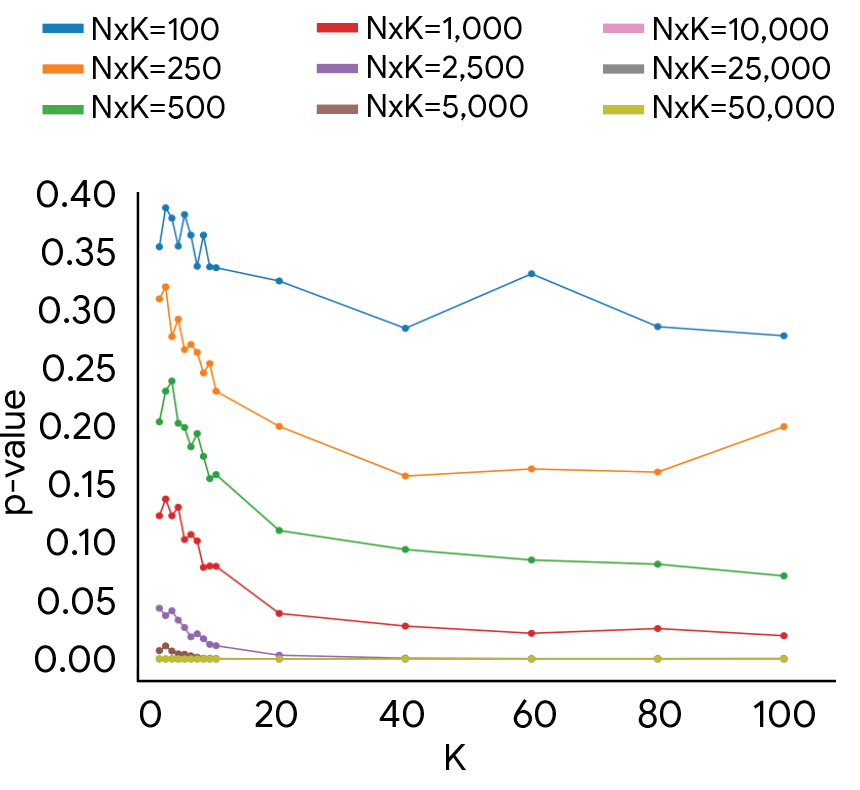
The experiments also show that reliable results can often be achieved with around 1,000 total annotations, but only if the budget is split correctly between test examples and raters. Get the balance wrong, and you can end up with unreliable conclusions even on a much larger budget, the researchers say.
What you measure should dictate how you spend
The biggest takeaway is that there's no one-size-fits-all ratio. The right strategy depends entirely on what you're trying to measure.
If you're using accuracy—checking whether a model agrees with the evaluators' majority vote—a wide approach works best: as many test examples as possible with just a few raters each. Accuracy only looks at the most common answer, so extra raters barely move the needle.
But if you want to capture the full spread of human responses—using a metric like total variation, for instance—you need the opposite playbook. Fewer test examples, but way more raters per example. That's the only way to map how much evaluators actually agree or disagree.
Different examples can get the same majority-vote label yet have very different response distributions underneath. In the experiments, this distribution-aware metric also needed the smallest overall budget to produce reliable results.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now