AI data isn't destroying AI models after all, researchers say

Can AI-generated data improve AI systems? Yes, under certain conditions. However, the idea that language models will "collapse" seems unlikely.
The growing complexity of large language models increases the demand not only for computing power, but also for training data. While the amount of data available online is vast, it's not infinite. Additionally, media companies are increasingly resisting unauthorized data collection by AI firms.
To address this issue, researchers are exploring the use of synthetically generated training data for LLMs or LMMs, generated by other AI systems. However, some researchers have suggested this could lead to "model collapse," where AI models that are increasingly trained on synthetic data gradually lose performance and eventually become ineffective.
Study claiming model collapse allegedly used unrealistic scenarios
A recent Nature paper by Shumailov et al. supports this idea by demonstrating cases of model collapse in various AI architectures, including language models, VAEs, and Gaussian mixture models.
But researchers led by Rylan Schaeffer from Stanford University disagree. Schaeffer, co-author of an April paper providing evidence for successful training with AI-generated data, argues that the Shumailov study makes unrealistic assumptions:
- It assumes all previous data is discarded after each iteration.
- The dataset size remains constant, whereas in reality, data volume increases over time.
- One experiment retains 10% of original data but replaces 90%, which is still unrealistic.
In Schaeffer's tests, adding synthetic data to existing data, rather than replacing it, prevented model collapse.
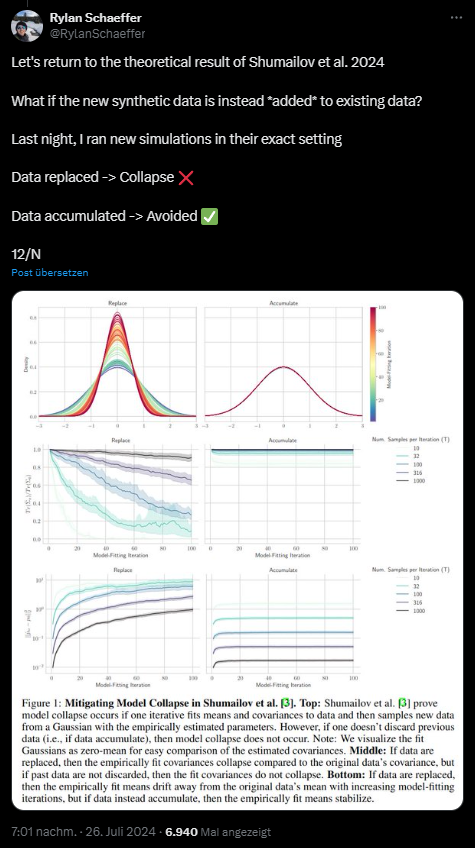
Schaeffer says he often gets questions from journalists about how to prevent model collapse, but he argues that the question is flawed. "It presumes model collapse is a real and significant threat under current best practices. Based on the evidence I've seen, it isn't," Schaeffer writes.
Meta optimizes Llama 3 with synthetic data and "execution feedback"
Meta's recently released LLaMA 3.1 provides a positive example of augmenting training data with synthetic information. To improve performance while avoiding model collapse, Meta employed "Execution Feedback" (page 19): The model generates programming tasks and solutions, which are then checked for correctness. Static code analysis, unit testing, and dynamic execution reveal errors.
If the solutions are incorrect, the model is prompted to revise them. In this way, it iteratively learns from its mistakes, and only correct solutions are incorporated into further iterations. Developers also use translations to improve performance for rare programming languages and for features such as documentation.
Meta has successfully optimized smaller 8B and 70B models using synthetic data from the 405B model. However, the researchers note that without execution feedback, training the 405B model with its own data isn't helpful and "can actually degrade performance."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.