AI expert Andrej Karpathy envisions a web where 99.9% of content is optimized for AI, not humans

Former OpenAI researcher Andrej Karpathy envisions a future where large language models (LLMs) become the primary interface for content.
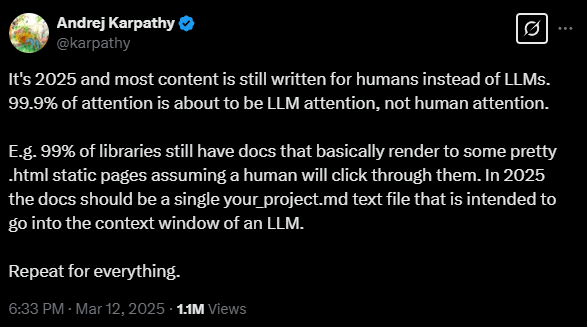
In a recent post on X, he suggests that while most content will still be written for humans, 99.9 percent of optimization efforts will focus on making content digestible for LLMs rather than human readers. This shift could fundamentally change how documentation and other content is structured.
Karpathy points to current documentation practices as an example: "99% of libraries still have docs that basically render to some pretty .html static pages assuming a human will click through them." By 2025, he argues, documentation should exist as a single project file optimized for an LLM's context window.
Moving toward AI-friendly web standards
Karpathy notes that while combining code bases into single files is technically straightforward, the real challenge lies with content stored in human-centric formats - websites, PDFs, images, videos, and audio files.
These "pre-LLM era" formats make AI optimization difficult. According to Karpathy, the industry needs new standards that work equally well for both human and machine consumption.
A new proposed web standard called "llms.txt" aligns with Karpathy's vision for AI-optimized content structure. Developed by Jeremy Howard, the specification works similarly to index.html but for AI systems. While index.html directs users to a page's HTML version, llms.txt would guide AI systems to a machine-readable Markdown (.md) version.
This dual approach allows websites to maintain both human-readable and AI-optimized versions of their content. Companies like Anthropic have already implemented this standard.
LLM companies as the new gatekeepers
The implications go far beyond just technical changes. Today's digital content economy runs on human attention - through advertising and subscriptions. The industry now faces the challenge of completely reimagining its value chains and revenue models as content shifts toward AI consumption.
AI companies have started licensing live news feeds, and this also raises some serious questions. When companies like OpenAI get to decide what content their AI systems see, they're essentially becoming powerful gatekeepers of information.
This shift threatens to reshape how everyone discovers and consumes online content, raising serious questions about who controls our access to information. The stakes are even higher considering that LLMs still frequently make mistakes when processing and reproducing information.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.