Anthropic's AI Fluency Index finds that polished AI output makes users less likely to check for errors

Key Points
- Anthropic analyzed almost 10,000 anonymized Claude conversations using its "AI Fluency Index" and found a pattern: the more polished AI-generated results appear, the less likely users are to verify their accuracy.
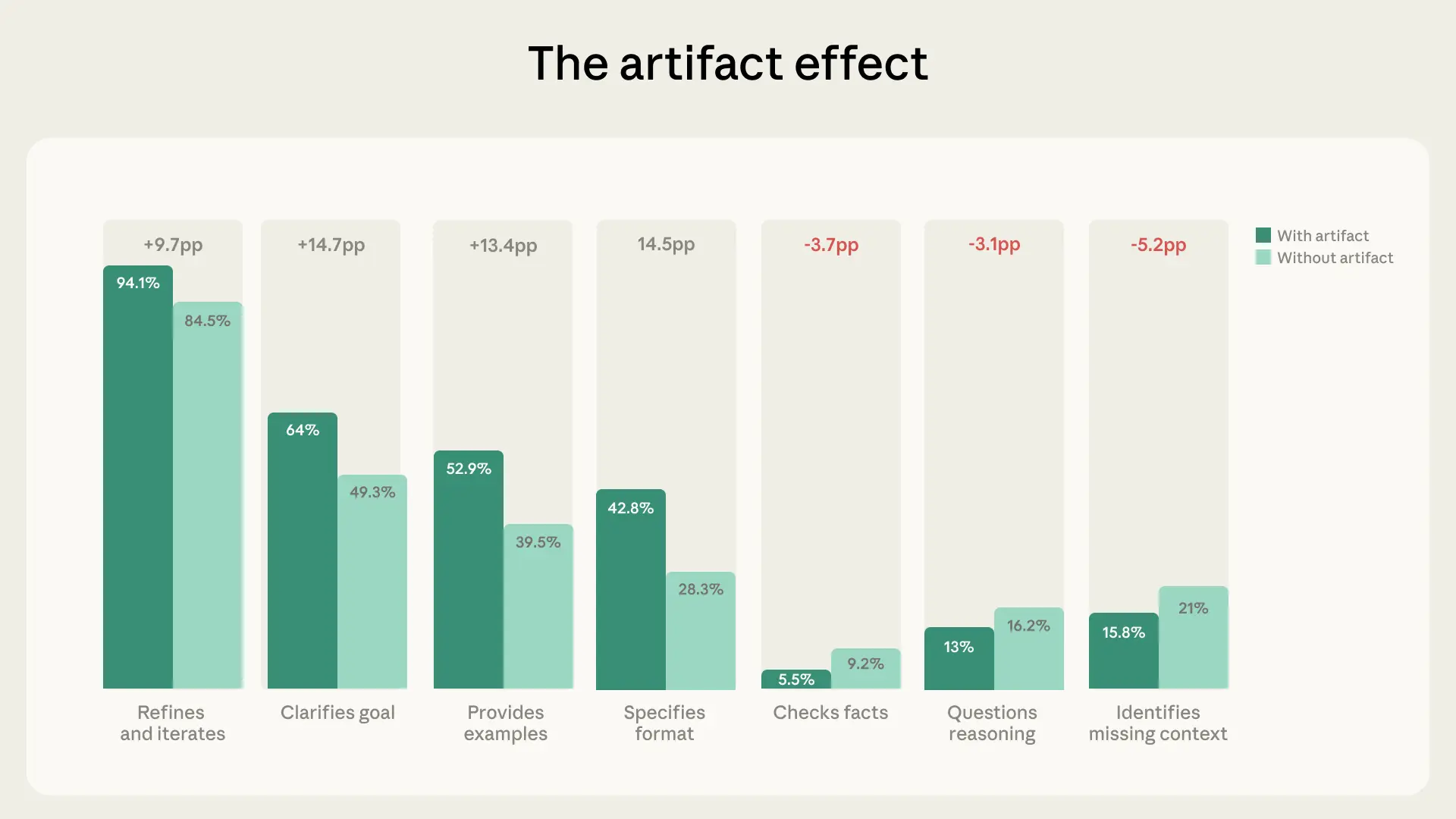
- In conversations producing outputs like small apps or documents, critical engagement dropped significantly: fact-checking decreased by 3.7 percentage points and questioning of argumentation fell by 3.1 percentage points.
- 85.7% of conversations showed signs of gradual refinement, and users who iterated on their prompts questioned Claude's reasoning 5.6 times more often and spotted missing context 4 times more frequently than those who didn't.
Anthropic has published a new "AI Fluency Index" that measures how competently people actually use AI tools. One key finding: when Claude delivers polished results, users' critical attention drops.
More and more people use AI tools every day, but that doesn't mean they're using them well. Anthropic is trying to answer exactly that question with its new AI Fluency Index, analyzing nearly 10,000 anonymized conversations with Claude from January.
The company spotted several patterns, and one stands out: the more polished the AI output looks, the less often users bother checking its accuracy. 12.3 percent of the conversations contained so-called artifacts: products Claude generated like code, documents, or interactive tools.
In those conversations, users did give more precise instructions up front. But that initial care didn't carry over into critical evaluation.
The opposite happened: in artifact conversations, users were less likely to flag missing context (-5.2 percentage points), less likely to verify facts (-3.7pp), and less likely to question Claude's reasoning (-3.1pp). According to Anthropic's own Economic Index, Claude struggles the most with the most complex tasks.
Anthropic offers a few possible explanations: if a result looks finished, users may just treat it as finished. It's also possible that factual accuracy matters less than aesthetics or functionality in artifact tasks like designing a user interface. Or users evaluate the output outside the chat altogether, testing code in a separate environment, for example.
Longer conversations lead to sharper AI use
The report's strongest finding is the link between iteration and every other competency indicator. 85.7 percent of the conversations showed signs of iteration and refinement - users gradually shaping results instead of just accepting the first answer.
These iterative conversations averaged 2.67 additional competency behaviors, roughly double the 1.33 seen in non-iterative conversations. The gap was especially stark when it came to critical review: users who iterated questioned Claude's reasoning 5.6 times more often and flagged missing context 4 times more often.
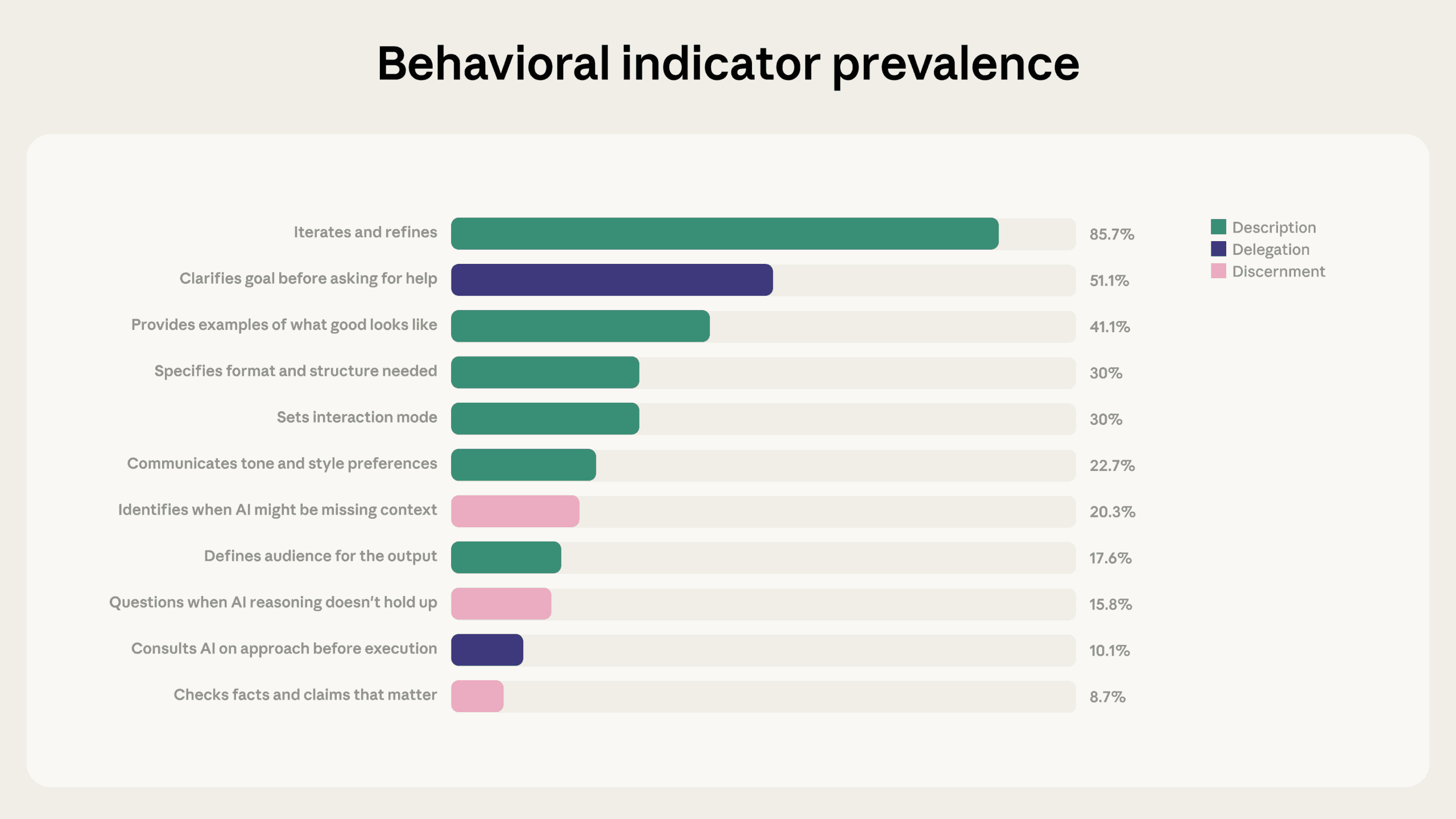
The report also uncovers a prompting gap: in only 30 percent of conversations, users told Claude how the interaction should work—with instructions like "Push back if my assumptions are wrong" or "Walk me through your reasoning before giving me the answer." According to Anthropic, this kind of steering can change the dynamics of an entire conversation.
Based on the data, Anthropic makes three recommendations: treat the first answer as a starting point rather than a final result, push back specifically on polished outputs, and spell out the terms of collaboration up front.
There's a catch, though: heavy iteration within a single chat hits a technical wall. Multiple studies show that AI output quality drops when too much irrelevant context piles up in the chat window. The longer a conversation runs, the more cluttered the context window gets. So real AI competence is also about knowing when to start a fresh chat instead of pushing a bloated conversation further.
Key competency dimensions stay hidden
Anthropic built its analysis on the 4D-AI Fluency Framework, developed by professors Rick Dakan and Joseph Feller in collaboration with the company. The framework defines 24 behaviors that represent competent AI interaction, but only 11 of them show up directly in chat conversations.
The remaining 13—including what Anthropic calls "some of the most consequential dimensions of AI fluency," like being upfront about AI-generated content when sharing it with others—happen outside the chat interface and are tough to measure. The company plans to tackle these with qualitative research down the road.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now