Apple study finds "a fundamental scaling limitation" in reasoning models' thinking abilities

LLMs designed for reasoning, like Claude 3.7 and Deepseek-R1, are supposed to excel at complex problem-solving by simulating thought processes. But a new study by Apple researchers suggests that these models actually perform worse as tasks become more difficult and, in some cases, they "think" less.
Large Reasoning Models (LRMs) such as Claude 3.7 Sonnet Thinking, Deepseek-R1, and OpenAI's o3 are often described as a step toward more general artificial intelligence. Techniques like chain-of-thought and self-reflection are meant to help these models tackle logic puzzles better than standard LLMs.
But the Apple study found structural flaws in how these reasoning mechanisms scale, pinpointing three distinct performance regimes—and a total collapse at high complexity.
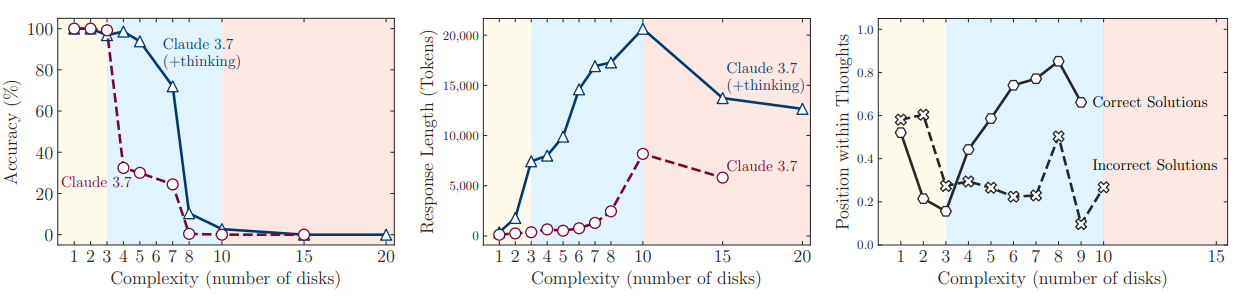
Three thinking regimes
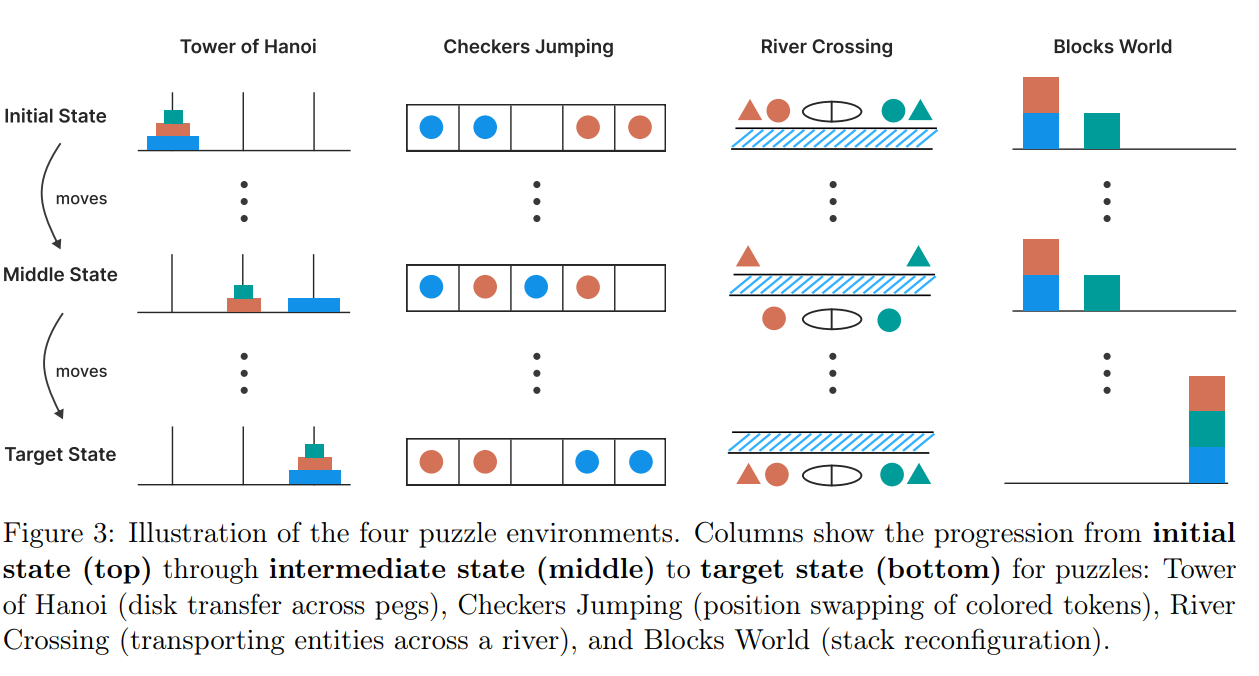
To probe these limits, the researchers put several reasoning models through their paces in four classic puzzle environments: Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World. Each scenario allowed for controlled increases in complexity without altering the core logic.
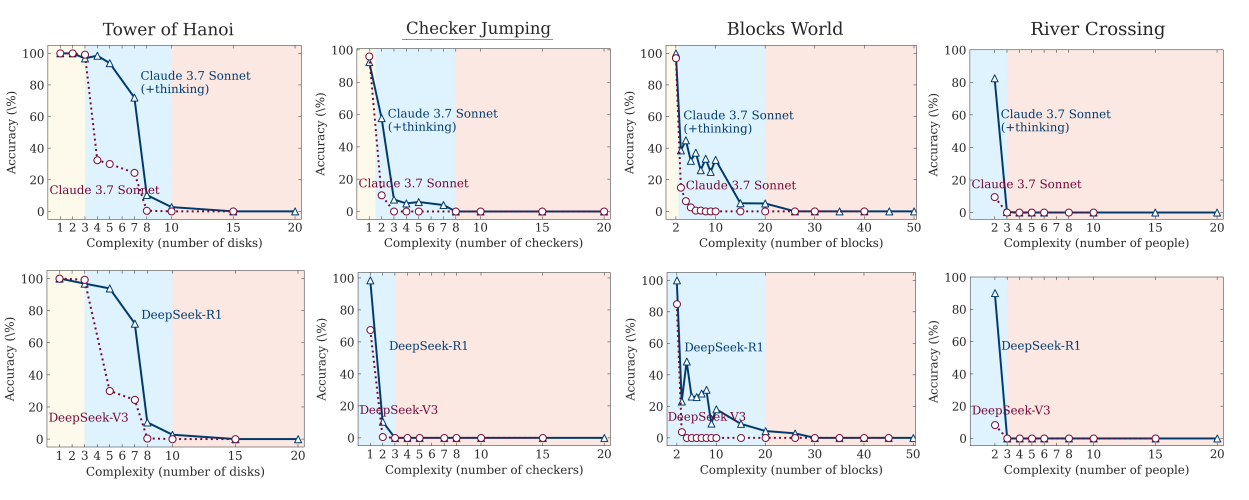
On simple problems, standard LLMs—like Claude 3.7 running without its "thinking" mode—came out ahead, showing both higher accuracy and lower token consumption. Reasoning models, such as the Thinking version of Claude 3.7 compared to the non-Thinking version, or Deepseek-R1 compared to its base LLM V-3, only began to excel at intermediate complexity.
But when the puzzles got tough, all the models failed in the same way. Accuracy dropped to zero, even when given ample compute resources. Surprisingly, the reasoning models actually used fewer "thinking" tokens on the hardest problems, cutting their own reasoning short even though they could have continued.
Overthinking and underthinking
The researchers also dug into the models' reasoning traces. On easy problems, models sometimes found the right answer early but kept searching, churning out incorrect alternatives, also known as overthinking. With moderate complexity, the models usually reached the correct answer only after trying out many wrong paths first.
But at the highest complexity, all of them failed. Their reasoning processes stopped producing correct answers altogether—a breakdown previously described as underthinking. Even when the solution steps were provided, the models' execution still collapsed once the problem got big enough.
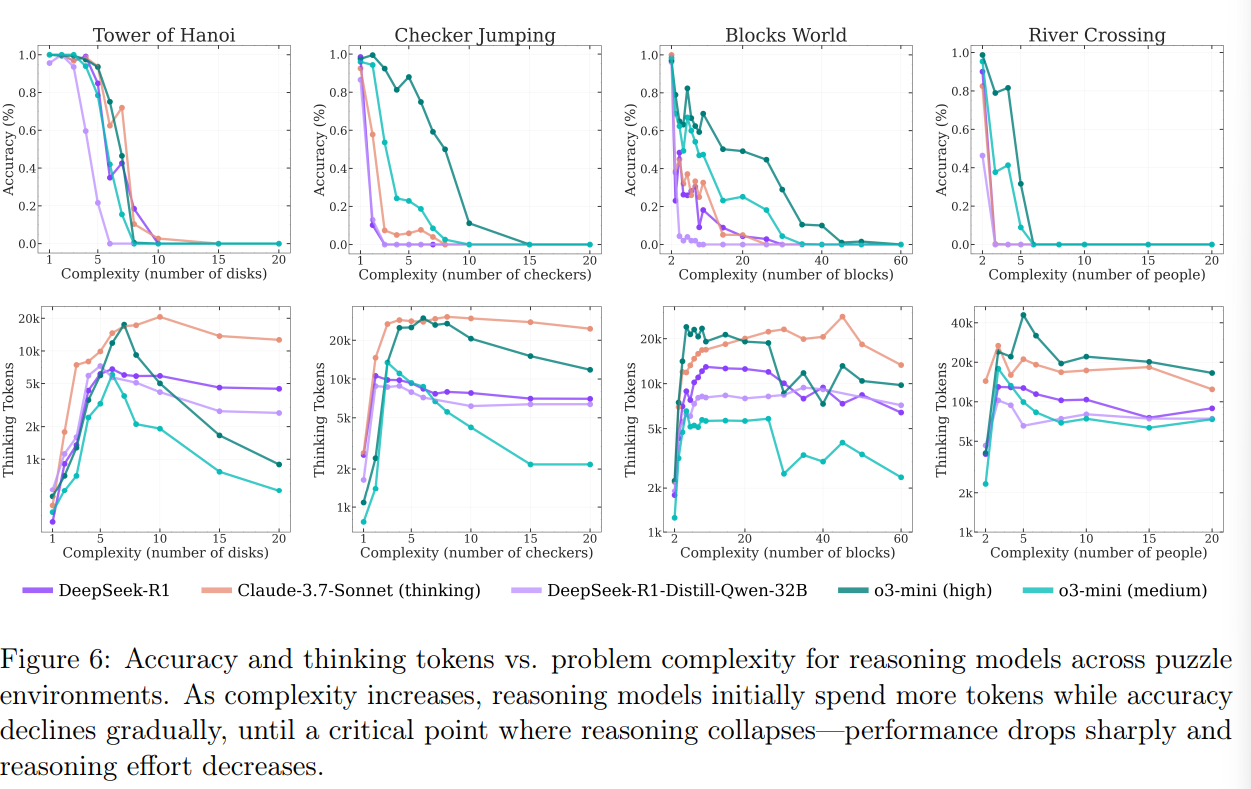
The study also spotted differences between puzzle types. The team thinks the frequency of example problems in training data could be one reason: Tower of Hanoi shows up more often online than complex river-crossing puzzles, which might help explain the drop-off in performance on the latter.
It's unclear whether failures in puzzle environments carry over to other domains. Apple researchers note that, although puzzle tests allow for precise analysis, they only cover a narrow aspect of real-world reasoning. More complex, knowledge-rich tasks may reveal different strengths and weaknesses.
Current limits of machine reasoning
Apple's researchers draw a stark conclusion: current reasoning models do not develop general strategies for problem-solving. Even with mechanisms like self-reflection and extended thought paths, they fail to keep pace as tasks grow more complex.
They describe their findings as a "a fundamental scaling limitation in the thinking capabilities of current reasoning models relative to problem complexity" and suggest that the core design principles of these models may need to be rethought to achieve robust machine reasoning.
This matters, especially as companies like OpenAI are betting heavily on reasoning methods as a way to move beyond traditional scaling with larger datasets and models. With gains from just more data and parameters starting to plateau, reasoning is considered a possible new path forward.
A separate study found that reasoning models mainly optimize LLMs to be more reliable at specific post-training tasks like math or coding, but don't add any fundamentally new capabilities.
Other researchers have recently criticized the tendency to anthropomorphize LLMs by showing their outputs as human-like "chains of thought." In the end, these so-called thoughts are just statistical calculations.
This isn't the first time Apple researchers have questioned the reasoning abilities of LLMs. In an earlier study, a team developed two new evaluation tools and found that even the best LLMs do not demonstrate true formal reasoning. Instead, they rely on advanced pattern matching. The models' performance dropped sharply when irrelevant information or small changes were introduced, and simply increasing data or model size led to better pattern matchers, not better reasoners.
Updated June 9: The final paragraph has been updated to include an earlier Apple study on LLM reasoning abilities.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.