Claude Opus 4.5 resists prompt injections better than rivals but still falls to strong attacks alarmingly often
Claude Opus 4.5 scores higher than its rivals in prompt-injection security, but the results show how limited these defenses still are. A benchmark by the security firm Gray Swan found that a single "very strong" prompt injection attack breaks through Opus 4.5's safeguards 4.7 percent of the time. Give an attacker ten attempts and the success rate jumps to 33.6 percent. At 100 attempts, it reaches 63 percent. Even with those gaps, Opus 4.5 still performs better than models like Google's Gemini 3 Pro and GPT-5.1, which show attack rates as high as 92 percent.
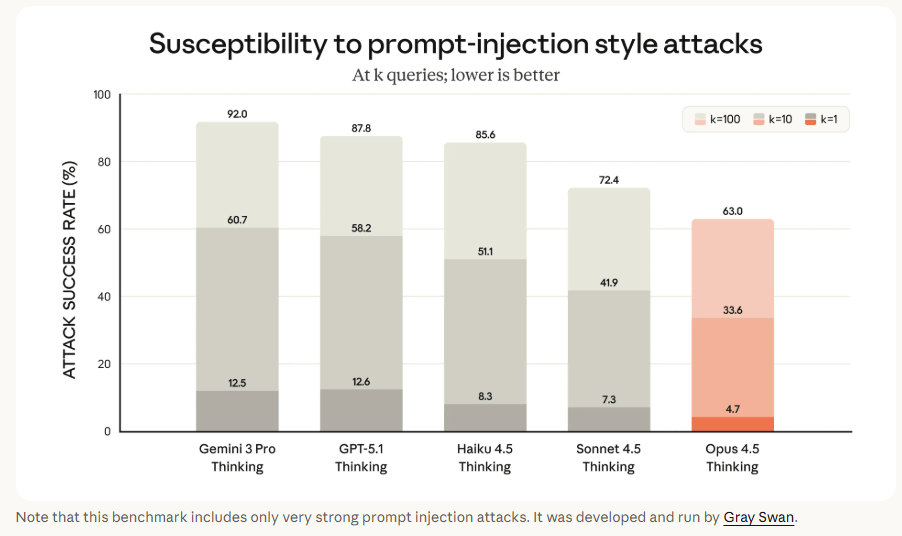
Prompt injection works by slipping hidden instructions into a prompt to bypass safety filters, a long-standing weakness in large language models. The issue becomes even more serious in agent-style systems, which expose more potential entry points and make these attacks easier to exploit.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.