ComfyGen AI automates multi-stage text-to-image workflows from simple prompts

Researchers from Nvidia and Tel Aviv University have developed ComfyGen, a new AI method that automates the creation of text-to-image workflows from simple prompts. The system independently selects suitable models, formulates prompts, and combines generated images with additional tools like upscalers to achieve desired results.
Traditional text-to-image generation typically relies on a single model to convert text into images. However, experienced prompt engineers often use complex, multi-stage workflows combining various components, including base models, LoRAs, prompt extensions, and upscaling models.
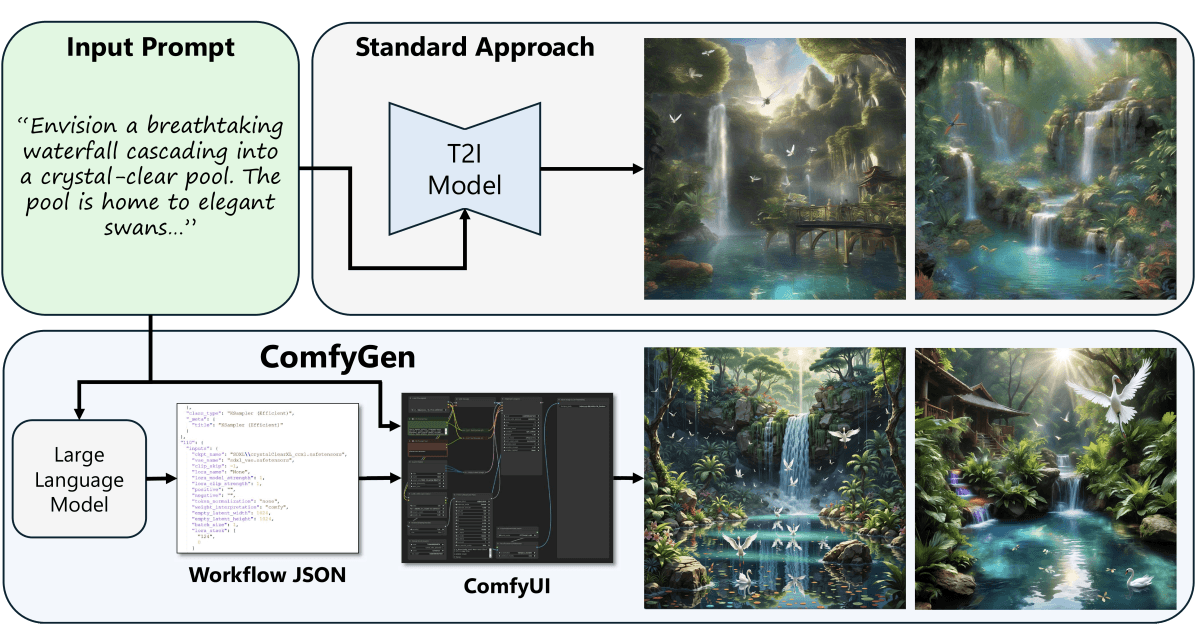
Component choice depends on prompt content and desired image style. Photorealistic images require different models than anime graphics or face and hand corrections. ComfyGen uses a language model like Claude 3.5 Sonnet to automatically compile suitable workflows based on concise text prompts.
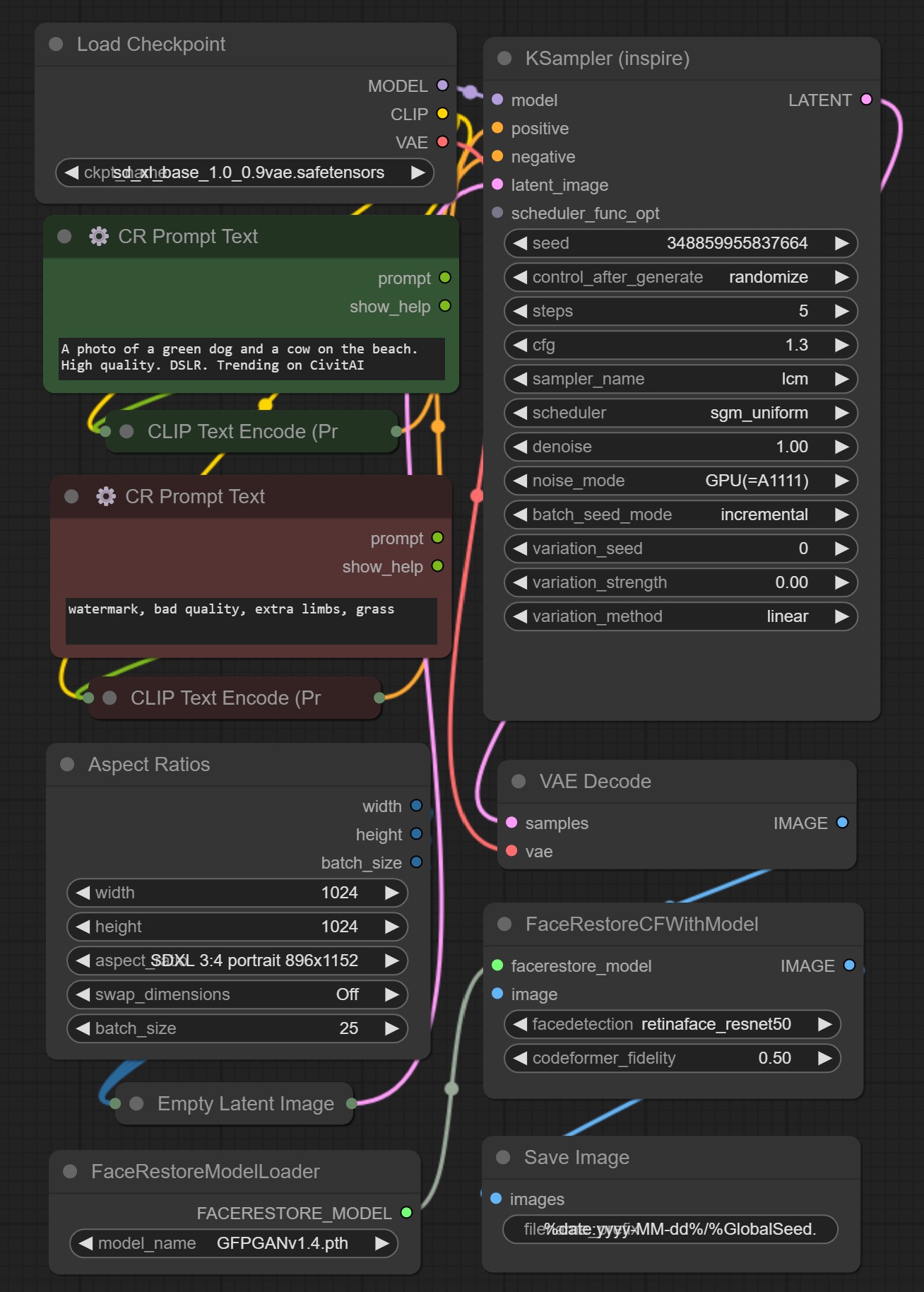
ComfyGen is based on the popular open-source tool ComfyUI, which allows users to define and share workflows in a structured JSON format. ComfyUI's widespread use in the Stable Diffusion community provides researchers with many human-created workflows for training data.
To test workflow performance, researchers collected 500 popular prompts and generated images using different workflows. They evaluated the results using aesthetic predictors and human preference estimation models.
In-context learning or fine-tuning
The final model takes a prompt and a target score as input and generates a JSON workflow to achieve the desired score. The researchers tested two approaches: in-context learning and fine-tuning.
In-context learning uses an existing LLM such as Claude 3.5 Sonnet. It is given a table of workflows and average scores for different prompt categories and selects the most appropriate workflow for new prompts. Fine-tuning trains an LLM (such as Llama-3.1-8B and -70B) to predict appropriate workflows for given prompts and target scores.
The following three images are all based on the prompt "A photo of a cake and a stop sign":



Experiments comparing ComfyGen with monolithic models such as Stable Diffusion XL and fixed, popular workflows showed that ComfyGen performed best on both automatic metrics and user studies. The fine-tuned variant slightly outperformed the in-context learning approach.
An analysis of the selected workflows showed that the model selection often matched the prompt categories. Facial upscaling models were selected more frequently for "people" prompts, while anatomically correct models were selected for "anime" prompts.
Promising approach with room for improvement
The advantage of ComfyGen is that it builds directly on existing workflows and scoring models created by the community, making it adaptable to new developments. However, this currently limits the variety and originality of generated workflows, as the system primarily selects known workflows from training data.
The researchers plan to develop the method to generate entirely new workflows and extend it to image-to-image tasks. In the future, prompt-driven workflows like ComfyGen could lower the barrier to entry for beginners while improving image quality.
The team suggests combining this approach with agent-based methods, where LLMs iteratively refine workflows through user dialog, as a topic for future research. The researchers have not yet released code or a demo of ComfyGen.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.