Context files for coding agents often don't help - and may even hurt performance

Context files are supposed to make coding agents more productive. New research shows that only works under very specific conditions.
A recent study from ETH Zurich researchers paints a much more critical picture of the common practice of equipping coding agents with context files like AGENTS.md. According to their findings, auto-generated context files actually tend to lower agent success rates while increasing inference costs by over 20 percent.
For their investigation, the researchers built a custom benchmark with 138 tasks from 12 open-source repositories that all contain developer-written context files, and also used the widely adopted SWE-bench Lite. They tested four popular coding agents - including Claude Code, Codex, and Qwen Code - each under three scenarios: no context file, LLM-generated context file, and a human-written version.
LLM-generated files led to worse performance in five out of eight test settings. Human-written context files fared better but only improved success rates by about 4 percentage points on average compared to having no context file at all.
Context files also didn't help coding agents locate relevant files any faster. For the weaker model GPT-5.1 Mini, LLM-generated context files actually increased the number of steps to first interaction with a relevant file significantly.
More instructions, more overhead, worse results
The behavioral analysis is particularly revealing. The agents did follow the instructions in the context files - they ran more tests, searched more files, and used repository-specific tools more often. So the problem isn't that agents ignore the files. Rather, unnecessary requirements made the tasks harder, which also showed up in the agents burning through significantly more reasoning tokens.
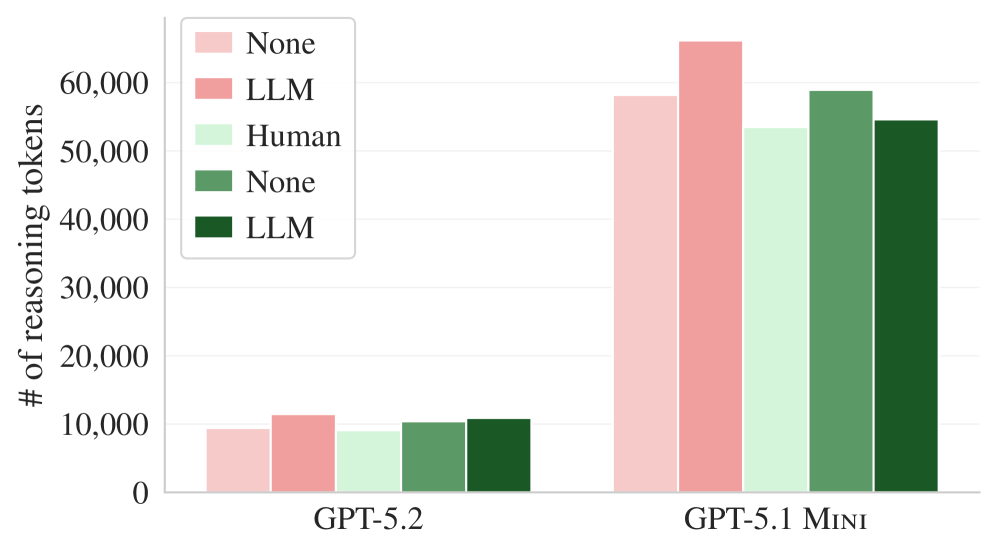
The context files created additional cognitive load without improving the problem-solving process. On top of that, LLM-generated context files were largely redundant with documentation already present in the repositories. They only showed a positive effect when all existing documentation was stripped from the repos.
Context files work when agents lack specific knowledge
Vercel recently tested a very specific use case: teaching current framework knowledge for Next.js - exactly the kind of information that isn't in the training data. In that scenario, the benefit of persistent context was clearly significant. The ETH researchers, however, looked at the more general case - real bug fixes and feature additions across diverse repositories - and found barely measurable benefits. So the study doesn't fundamentally contradict Vercel's findings, but it puts them in important context.
Based on these results, developers may want to think twice before relying on auto-generated context files. The researchers recommend including only minimal, manually written requirements - like pointers to specific tools or build systems. AGENTS.md appears most useful when it's written by hand to fill in genuinely missing knowledge. That said, the study tested a limited set of agents and repositories, so these findings may not generalize to every workflow. Still, the results suggest that treating context files as a universal fix for better coding agents is premature.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.